
人脸识别在现实生活中有非常广泛的应用,例如iPhone X的识别人脸解锁屏幕、人脸识别考勤机、人脸识别开门禁、刷脸坐高铁,还有识别人脸虚拟化妆、美颜,甚至支付宝还推出了刷脸支付、建设银行还实现了刷脸取钱……,可见人脸识别的用处非常广。
既然人脸识别这么有用,那我们能否自己来实现一个人脸识别模型呢?
答案是肯定的。
接下来将在之前我们搭建好的AI基础环境上(见文章:搭建AI基础环境),实现人脸识别模型。
0、人脸识别主要流程
要识别一张人脸,一般需要经过以下步骤:(1)通过摄像头或上传图片等方式采集图像;(2)检测图像里面有没有人脸,如果有就把人脸所在的区域圈出来;(3)对人脸图像进行灰度处理、噪声过滤等预处理;(4)提取人脸的特征数据出来;(5)将提取的人脸特征数据与人脸库进行匹配,输出识别结果。主要流程如下图所示:

下面将按步骤逐个介绍实现方式。
1、图像采集
本文采用OpenCV采集图像。

OpenCV是处理图像的流行工具,具备多种图像处理的能力,可跨平台运行在Linux、Windows、Mac OS等多个平台,使用C++编写,提供Python、C++、Ruby等语言的接口。在Python环境中,OpenCV和Tensorflow能很好地相互配合,利用OpenCV可方便快速地采集、处理图像,配合Tensorflow能很好地实现图像的建模工作。
(1)安装OpenCV
在conda虚拟环境中,OpenCV的安装方式如下:
conda install --channel https://conda.anaconda.org/menpo opencv3(2)采集图像
在OpenCV中调用摄像头采集图像的方式如下:
# 1、调用摄像头进行拍照
cap = cv2.VideoCapture(0)
ret, img = cap.read()
cap.release()
如果已经是有现成的图片,则在OpenCV中直接读取就可以:
# 2、根据提供的路径读取图像
img=cv2.imread(img_path)
2、人脸检测
人脸检测的主要目的是检测采集的图像中有没有人脸,并确定出人脸所在的位置和大小。检测人脸有很多种方式,下面介绍几种常用的方法:
(1)使用OpenCV检测人脸
OpenCV中自带了人脸检测器,基于Haar算法进行人脸检测。Haar算法的基本思路是这样的,通过使用一些矩形模板对图像进行扫描,例如下图中的两个矩形模板,中间一幅在扫描到眼睛时发现眼睛区域的颜色比周边脸颊区域的颜色深,表示符合眼睛的特征;右边一幅在扫描到鼻梁时发现鼻梁两侧比鼻梁的颜色要深,符合鼻梁的特征。同样地,再通过其它的矩形模板进行扫描,当发现具备眼睛、鼻梁、嘴巴等特征且超过一定的阈值时,则判定为是一张人脸。

使用OpenCV检测人脸,要先加载人脸分类器
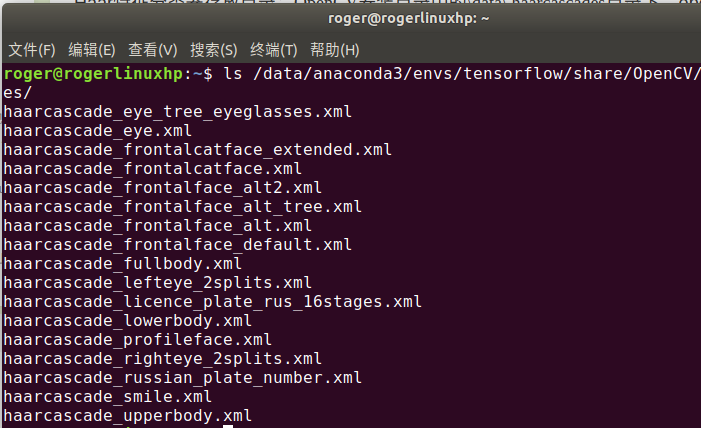
代码如下:
# 1、使用 opencv 检测人脸
# 加载人脸检测分类器(正面人脸),位于OpenCV的安装目录下
face_cascade=cv2.CascadeClassifier('/data/anaconda3/envs/tensorflow/share/OpenCV/haarcascades/haarcascade_frontalface_default.xml')
# 转灰度图
img_gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# 检测人脸(可能有多张),返回人脸位置信息(x,y,w,h)
img_faces=face_cascade.detectMultiScale(img_gray)
(2)使用Dlib检测人脸
Dlib是一个包含机器学习算法开源工具包,基于C++编写,同样也提供了Python语言接口。使用Dlib也能很方便地检测出人脸,检测的效果要比OpenCV好,安装方式如下:
# 安装 Dlib
# 激活 conda 虚拟环境
conda activate tensorflow
# 安装 Dlib
conda install -c menpo dlib代码如下:
# Dlib 人脸检测
detector = dlib.get_frontal_face_detector()
dets = detector(img, 1)
# 获取人脸所在的位置
img_faces=[]
for i in range(len(dets)):
x = dlib.rectangle.left(dets[i])
y = dlib.rectangle.top(dets[i])
h = dlib.rectangle.height(dets[i])
w = dlib.rectangle.width(dets[i])
img_faces.append([x,y,w,h])(3)使用face_recognition检测人脸

face_recognition是基于dlib的深度学习人脸识别库,在户外脸部检测数据库基准(Labeled Faces in the Wild benchmark,简称LFW)上的准确率达到了99.38%。
使用face_recognition检测人脸,安装方式如下:
# 安装 face_recognition
# 需要先安装dlib , 还有 CMake ( sudo apt-get install cmake )
# 激活 conda 虚拟环境
conda activate tensorflow
# 由于 face_recognition 在 conda 中没有相应的软件包,因此通过 pip 安装
pip install face_recognition代码如下:
# 检测人脸
face_locations = face_recognition.face_locations(img)
# 获取人脸的位置信息
img_faces = []
for i in range(len(face_locations)):
x = face_locations[i][3]
y = face_locations[i][0]
h = face_locations[i][2] - face_locations[i][0]
w = face_locations[i][1] - face_locations[i][3]
img_faces.append([x, y, w, h])(4)使用FaceNet检测人脸

FaceNet是谷歌发布的人脸检测算法,发表于CVPR 2015,这是基于深度学习的人脸检测算法,利用相同人脸在不同角度、姿态的高内聚性,不同人脸的低耦合性,使用卷积神经网络所训练出来的人脸检测模型,在LFW人脸图像数据集上准确度达到99.63%,比传统方法的准确度提升了将近30%,效果非常好。
使用FaceNet检测人脸,安装方式如下:
a. 到FaceNet的github上将源代码和相应的模型下载下来(https://github.com/davidsandberg/facenet)
b. 将要用到的python文件导入到本地的 facenet 库中,如下图所示:
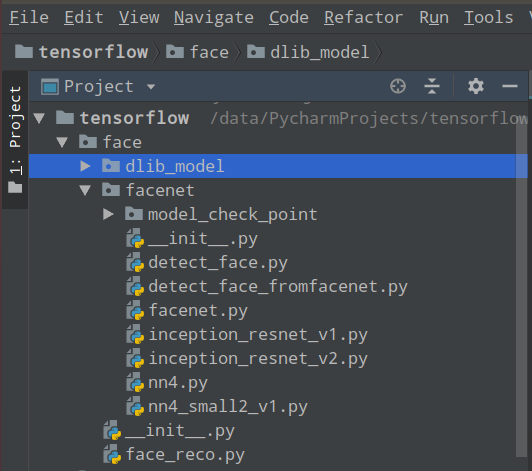
代码如下:
with tf.Graph().as_default():
sess = tf.Session()
with sess.as_default():
pnet, rnet, onet = facenet.detect_face_fromfacenet.create_mtcnn(sess, './facenet/model_check_point/')
minsize = 20
threshold = [0.6, 0.7, 0.7]
factor = 0.709
bounding_boxes, _ = facenet.detect_face_fromfacenet.detect_face(img, minsize, pnet, rnet, onet, threshold, factor)
img_faces = []
for face_position in bounding_boxes:
face_position = face_position.astype(int)
x = face_position[0]
y = face_position[1]
h = face_position[3] - face_position[1]
w = face_position[2] - face_position[0]
img_faces.append([x, y, w, h])
3、预处理
在做完图像的人脸检测后,得到了人脸所在的位置和大小,但由于受到各种条件的限制和随机干扰,需要根据实际采集的图像质量情况进行预处理,以提升图像的质量。主要的预处理有:
(1)调整尺寸:根据网络传输带宽、电脑处理性能等相关的要求,对检测的人脸图像进行尺寸调整;
(2)直方图均衡化:根据实际情况,对图像作直方图均衡,避免因光线问题,导致人脸上出现明显阴影的情况,从而影响了识别的准确率;
(3)噪声过滤:通过使用中值滤波器、高斯滤波器等对图像进行噪声过滤,以提升图像质量;
(4)锐化:由于摄像头对焦的问题,导致某些采集的照片出现模糊,通过锐化操作,提升图像的清晰度;
(5)光线补偿:对于一些光线不足的图像进行光线补偿,提升照片的亮度,便于后续更加准确地提取特征。
4、特征提取
人脸是由眼睛、鼻子、嘴、下巴等局部构成,这些局部之间的结构关系,便是作为人脸的重要特征。人脸特征的提取,是对人脸进行特征建模的过程。
下面介绍提取人脸特征的几种方法:
(1)使用Dlib提取人脸特征(68维)
使用Dlib可提取人脸的68个特征点,这些特征点描述了眉毛、眼睛、鼻子、嘴巴,以及整个脸部的轮廓,如下图所示:

使用Dlib提取人脸特征的代码如下:
# 1、dlib 提取人脸特征
# opencv 无法直接提取人脸特征,在这里设置 opencv 也采用 dlib 的特征提取方式
# 下载模型:http://dlib.net/files/
# 下载文件:shape_predictor_68_face_landmarks.dat.bz2
# 解压文件,得到 shape_predictor_68_face_landmarks.dat 文件
# 获取人脸检测器
predictor = dlib.shape_predictor('./dlib_model/shape_predictor_68_face_landmarks.dat')
for index,face in enumerate(dets):
face_feature = predictor(face_img,face)(2)使用face_recognition提取人脸特征(128维)
face_recognition提取的人脸特征比Dlib更加细致,达到128个点,同样也是描述了眉毛、眼睛、鼻子、嘴巴等局部的关系。
使用face_recognition提取人脸特征的代码如下:
# 2、face_recognition 提取人脸特征
face_feature = face_recognition.face_encodings(face_img)(3)使用FaceNet提取人脸特征(128维)
使用FaceNet提取的人脸特征同样也有128维,代码如下:
with tf.Graph().as_default():
sess = tf.Session()
with sess.as_default():
batch_size=None
image_size=160
images_placeholder = tf.placeholder(tf.float32, shape=(batch_size,image_size,image_size, 3), name='input')
phase_train_placeholder = tf.placeholder(tf.bool, name='phase_train')
model_checkpoint_path = './facenet/model_check_point/'
input_map = {'input': images_placeholder, 'phase_train': phase_train_placeholder}
model_exp = os.path.expanduser(model_checkpoint_path)
meta_file, ckpt_file = get_model_filenames(model_exp)
saver = tf.train.import_meta_graph(os.path.join(model_exp, meta_file), input_map=input_map)
saver.restore(sess, os.path.join(model_exp, ckpt_file))
face_img = cv2.resize(face_img, (image_size, image_size), interpolation=cv2.INTER_CUBIC)
data = np.stack([face_img])
embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0")
feed_dict = {images_placeholder: data, phase_train_placeholder: False}
face_feature = sess.run(embeddings, feed_dict=feed_dict)
5、匹配识别
在提取好人脸特征后,便是要用于识别这个人是谁。
将提取的人脸特征与数据库中存储的人脸特征数据进行检索匹配,当匹配的相似度超过一定的阈值后,便将匹配结果输出。
一般常用以下方式进行匹配:
(1)基于距离判断(欧氏距离)
将提取出来的人脸特征(68维或128维),逐个与数据库中的人脸特征计算距离,一般使用欧氏距离,然后取最小的距离,当超过阈值时便输出识别结果。
这种方式简单易用,但却经常会误判,这是由于人的表情很丰富,数据库中并不一定会把所有表情都存储起来。
基于欧氏距离的人脸识别代码如下:
# 1、欧氏距离
min_dis=99999
min_idx=-1
for i in range(len(features)):
dis=np.sqrt(np.sum(np.square(face_feature-features[i])))
if dis<min_dis:
min_dis=dis
min_idx=i
name=labels[min_idx]
(2)基于分类算法(KNN)
人脸特征的匹配本质上也是一个分类过程,即将属于同一个人的分类出来。采用K近邻(KNN)算法进行分类,这是数据挖掘中最简单的方法之一。所谓K近邻,就是K个最近邻居,就是说每个样本都可以用它最接近的K个邻居来代表。因此,KNN算法的核心思想是如果一个样本的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别。
基于KNN的人脸识别代码如下:
# 2、KNN
knn = neighbors.KNeighborsClassifier(n_neighbors=2)
knn.fit(features, labels)
name = knn.predict([face_feature])
name = name[0]
通过以上步骤,我们了解了几种常见的人脸检测、识别算法,并掌握了一个完整的人脸识别程序的编写过程。
后面将陆续推出更多AI实战内容,敬请留意。
推荐相关阅读
- 【AI实战】快速掌握TensorFlow(一):基本操作
- 【AI实战】快速掌握TensorFlow(二):计算图、会话
- 【AI实战】快速掌握TensorFlow(三):激励函数
- 【AI实战】快速掌握TensorFlow(四):损失函数
- 【AI实战】搭建基础环境
- 【AI实战】训练第一个模型
- 【AI实战】编写人脸识别程序
- 【AI实战】动手训练目标检测模型(SSD篇)
- 【AI实战】动手训练目标检测模型(YOLO篇)
- 【精华整理】CNN进化史
- 大话卷积神经网络(CNN)
- 大话循环神经网络(RNN)
- 大话深度残差网络(DRN)
- 大话深度信念网络(DBN)
- 大话CNN经典模型:LeNet
- 大话CNN经典模型:AlexNet
- 大话CNN经典模型:VGGNet
- 大话CNN经典模型:GoogLeNet
- 大话目标检测经典模型:RCNN、Fast RCNN、Faster RCNN
- 大话目标检测经典模型:Mask R-CNN
- 27种深度学习经典模型
- 浅说“迁移学习”
- 什么是“强化学习”
- AlphaGo算法原理浅析
- 大数据究竟有多少个V
- Apache Hadoop 2.8 完全分布式集群搭建超详细教程
- Apache Hive 2.1.1 安装配置超详细教程
- Apache HBase 1.2.6 完全分布式集群搭建超详细教程
- 离线安装Cloudera Manager 5和CDH5(最新版5.13.0)超详细教程