over(order by salary) 按照salary排序进行累计,order by是个默认的开窗函数
over(partition by deptno)按照部门分区
如何使用Oracle Round 函数 (四舍五入)
描述 : 传回一个数值,该数值是按照指定的小数位元数进行四舍五入运算的结果。
SELECT ROUND( number, [ decimal_places ] ) FROM DUAL
参数:
number : 欲处理之数值
decimal_places : 四舍五入 , 小数取几位 ( 预设为 0 )
Sample :
select round(123.456, 0) from dual; 回传 123
select round(123.456, 1) from dual; 回传 123.5
ratio_to_report主要完成对百分比的计算,语法为
ratio_to_report(exp) over()
也就是根据over窗口函数的作用区间,求出作用区间中的单个值在整个区间的总值的比重
比如要求scott用户下emp表中每个员工的工资占本部门的比重
select ename,sal,deptno,ratio_to_report(sal) over(partition by deptno) ratio from emp;
select deptno,
ename,

sal,
sum(sal) over (partition by deptno order by sal, ename) cum_sal,
round(100*ratio_to_report(sal) over (partition by deptno), 1) pct_dept,
round(100*ratio_to_report(sal) over (), 1) pct_over_all
from emp order by deptno, sal;

Oracle 的体系结构

Oracle的服务由数据库和实例组成
实例就是一组操作系统进程(或者是一个多线程的进程)和一些内存,这些进程可以操作数据库。数据库只是一个文件集合(包括数据文件、控制文件、重做日志文件)。
实例可以在任何时间点装载和打开一个数据库。实际上,准确地讲,实例在其整个生存期中最多能装载和打开一个数据库!
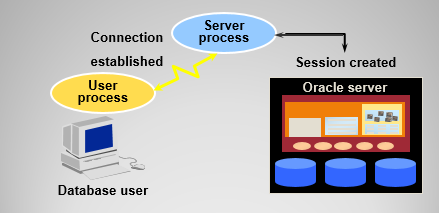
连接数据库实例: 建立用户连接和创建会话
物理存储结构包括存储在磁盘上的数据文件、控制文件、重做日志文件
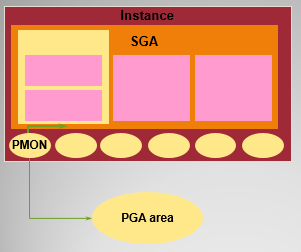
内存结构:SGA和PGA
SGA:System Global Area是Oracle Instance的基本组成部分,在实例启动时分配;系统全局域SGA主要由三部分构成:共享池、数据缓冲区、日志缓冲区等包括两个可选的(大型池和java池)。
SGA_MAX_SIZE指的是可动态分配的最大值﹐而SGA_TARGET是当前已分配的最大SGA。
共享池:Shared Pool用于缓存最近被执行的SQL语句和最近被使用的数据定义,主要包括:Library cache(共享SQL区)和Data dictionary cache(数据字典缓冲区)。 共享SQL区是存放用户SQL命令的区域,数据字典缓冲区存放数据库运行的动态信息。内存大小由参数SHARED_POOL_SIZE指定。Library cache(共享SQL区)存储了最近使用的SQL和PL/SQL语句。数据字典缓冲区是最近在数据库中使用的定义的集合。
缓冲区高速缓存:Database Buffer Cache用于缓存从数据文件中检索出来的数据块,可以大大提高查询和更新数据的性能。块的大小由参数DB_BLOCK_SIZE决定。
重做日志缓冲区:redo log buffer cache 记录了在数据库数据块中做的所有改变。
大型池:Large Pool是SGA中一个可选的内存区域,它只用于shared server环境。
Java池:Java Pool为Java命令的语法分析提供服务。
PGA:Process Global Area是为每个连接到Oracle database的用户进程保留的内存。

进程是操作系统中的一种机制,它可执行一系列的操作步。
Oracle进程中有三类:用户进程,服务进程,后台进程
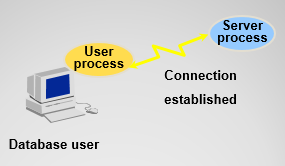
用户进程: 当用户请求连接oracle服务时启动。它必须首先建立一个连接,它不能和oracle 服务直接交互。
服务进程:可以直接和oracle 服务进行交互。

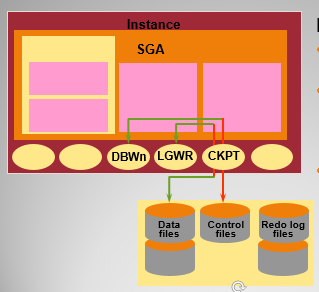
后台进程:
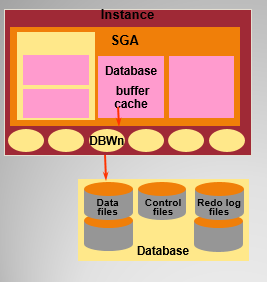
DBWR 数据库写入程序
该进程执行将缓冲区写入数据文件,是负责缓冲存储区管理的一个OR
ACLE后台进程。
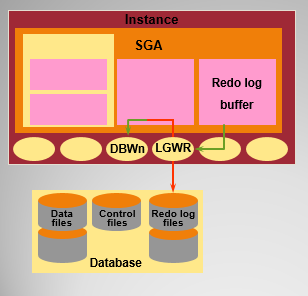
LGWR 日志写入程序
该进程将日志缓冲区写入磁盘上的一个日志文件,它是负责管理日志
缓冲区的一个ORACLE后台进程。
在数据库写入程序之前
SMON 系统监控
该进程实例启动时执行实例恢复,还负责清理不再使用的临时段。

PMON 进程监控
该进程在用户进程出现故障时执行进程恢复,负责清理内存储区和释
放该进程所使用的资源。
CKPT 检查点
该进程在检查点出现时,对全部数据文件的标题进行修改,指示该检
查点。
使用检查点的原因:
检查点确保在内存中频繁改变的数据块可以正常的写入数据文件
可以快速的进行实例的恢复
ARCH 归档
该进程将已填满的在线日志文件拷贝到指定的存储设备。当日志是为
ARCHIVELOG使用方式、并可自动地归档时ARCH进程才存在。

Oracle的逻辑结构表明了数据库的物理结构是如何被使用的
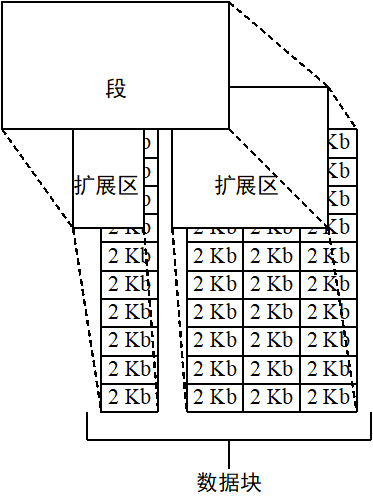
数据库->表空间->段->区->数据块

表空间:
保留相关数据库对象的组
Oracle数据库中典型表空间包括
SYSTEM表空间
DATA表空间
USER表空间
TOOLS表空间
TEMP表空间

数据库的控制空间分配
为数据库用户设置空间配额
备份或恢复数据
段:定义为分配给逻辑数据库结构的扩展区集合
不同类型的段:
数据段
索引段
回滚段
临时段
模式:所谓模式是指一系列逻辑数据结构或对象的集合。
模式与用户相对应,一个模式只能被一个数据库用户所拥有,并且模式的名称和用户的名称相同。
Oracle数据库中并不是所有的对象都是模式对象。表,索引,约束,索引,视图,序列,存储过程,同义词,用户自定义数据结构,数据库连接。而表空间,用户,角色,目录,概要文件及上下文等数据库对象不属于任何模式,称为非模式对象。
Oracle语句的处理过程
解析->优化->行资源生成->执行
解析:对提交的语句进行语法和语义检查
将已经提交的语句分解,判定属于那种类型,并在其上执行各种检验操作
语法检查:正确表述,符合SQL规则
语义检查:正确应用SQL对象?授权?歧义?
检查Shared Pool:已被其他Session处理过
优化:生成一个可在oracle中用来执行语句的最佳计划
行资源生成:为回话取得最佳计划和建立执行计划
执行:完成实际执行查询的行资源生成步骤的输出
存储在常规表中行采用没有特定的次序存储
Oracle将获取的名字与ROWID进行关联。ROWID是表中行的物理地址,可以告知对象的来源,所处的文件以及文件中特定数据块。
Oracle常用的有两种索引类型:B树索引和位图索引
B树索引:B树索引是最常用的索引,它的存储结构类似于书的目录索引结构,有分支节点和叶子节点,分支节点相当于书的大目录,叶子节点相当于具体到页的索引。B树索引是oracle数据库的默认索引类型。
只有几个不同的值供选择。例如,一个"类型"列中,只有四个不同的值(A,B,C,和D)。该索引是一个低效的选择。如果你有一个Oracle数据库,那么为这些选择范围小的的列建立位图索引是更好的选择。
数据库启动和关闭
为了满足数据库管理的需要,Oracle数据库的启动和关闭是分步骤进行的

STARTUP
ALTER DATABASE db01 MOUNT
ALTER DATABASE db01 READ ONLY
STARTUP RESTPICT
ALTER SYSTEM ENABLE RESTRICTED SESSION
当数据库被创建的时候,oracle 服务在数据文件创建额外的对象结构
数据字典表
动态性能表
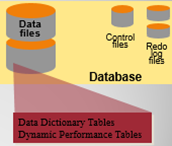
Oracle数据字典是由表和视图组成,存储有关数据库结构信息的一些数据库对象。
数据字典按照存在的形式分为数据字典表和数据字典视图。
数据字典
基表是存储有关数据库的信息的底层表。基表是在任何 Oracle 数据库中首先创建的对象。在使用 CREATE DATABASE 创建数据库时,只要 Oracle 服务器运行 sql.bsq 脚本,就会自动创建这些对象。
数据字典视图
数据字典视图是基表的汇总,可以更有效地显示基表信息。
数据字典内容包括:
1,数据库中所有模式对象的信息,如表、视图、簇、索引、集群、同义词、序列、过程、方法、包、触发器等。
2,分配多少空间,当前使用了多少空间等。
3,列的缺省值。
4,约束信息的完整性。
5,Oracle用户的名字。
6,用户及角色被授予的权限。
7,用户访问或使用的审计信息。
8,其它产生的数据库信息。
数据字典有三个主要的用途
Oracle服务器使用它来发现关于使用者,模式对象,存储结构的信息。
Oracle 服务器修改它当DDL语句执行时。
用户和DBAs可以把它当作只读表来查看数据库的信息。
为了便于用户对数据字典表的查询, Oracle对这些数据字典都分别建立了用户视图,这样即容易记住,还隐藏了数据字典表表之间的关系,Oracle针对这些对象的范围,分别为:
DBA:所有方案中的视图(可以看到所有数据字典里的信息)
ALL:用户可以访问的视图(可以看到所有这个用户可以看到的信息)
USER:用户方案中的视图(仅仅是这个用户拥有的信息)
三者直接的关系:

动态性能视图记录当前数据库的活动
只要数据库正在操作视图就会持续的更新
信息是从内存和控制文件中获得的
DBAs使用动态视图来监视和调整数据库
SYS 用户才能使用动态视图
不允许有DML操作
在oracle数据库中,用户权限分为下列两个类
系统权限
允许用户在数据库中执行特定的操作
对象权限
允许用户读取和操作特定的对象
总共有超过100个不同的系统权限
ANY关键字 可以拥有所有的权限
GRANT关键字 可以增加权限
REVOKE关键字 回收权限
Eg:GRANT CREATE SESSION TO emi;
GRANT CREATE SESSION TO emi WITH ADMIN OPTION;
只用授权时带有WITH ADMIN OPTION 子句时,用户才可以将获得的系统权限再授予其他用户,即系统权限的传递性。
系统权限的回收
REVOKE CREATE TABLE FROM emi;
不管师是否有 WITH ADMIN OPTION,它都不会产生连级的影响
对象权限
回收对象权限使用WITH GRANT OPTION将会有连级的影响。
角色

角色的好处
更简单的权限管理
动态的权限管理
选择可供使用的权限
可以通过操作系统授权
提高性能
Eg:CREATE ROLE oe_clerk;
ALTER ROLE oe_clerk IDENTIFIED BY order;
GRANT oe_clerk TO scott;
ALTER USER scott DEFAULT ROLE hr_clerk,oe_clerk
CREATE ROLE admin role IDENTIFIED USING hr.employee
SET ROLE hr_clerk;
SET ROLE oe_clerk IDENTIFIED BY order;
REVOKE oe_clerk FROM scott;
REVOKE hr_manager FROM PUBLIC;
DROP ROLE hr_manager;
Oracle提供的语句
条件语句
CASE 表达式
CASE expr WHEN comparison_expr1 THEN return_expr1
[WHEN comparison_expr2 THEN return_expr2
WHEN comparison_exprn THEN return_exprn
ELSE else_expr]
END
DECODE 函数
decode(条件,值1,返回值1,值2,返回值2,...值n,返回值n,缺省值)
该函数的含义如下:
IF 条件=值1 THEN
RETURN(翻译值1)
ELSIF 条件=值2 THEN
RETURN(翻译值2)
......
ELSIF 条件=值n THEN
RETURN(翻译值n)
ELSE
RETURN(缺省值)
END IF
decode(字段或字段的运算,值1,值2,值3)
这个函数运行的结果是,当字段或字段的运算的值等于值1时,该函数返回值2,否则返回值3
当然值1,值2,值3也可以是表达式,这个函数使得某些sql语句简单了许多
使用方法:
1、比较大小
select decode(sign(变量1-变量2),-1,变量1,变量2) from dual; --取较小值
sign()函数根据某个值是0、正数还是负数,分别返回0、1、-1
例如:
变量1=10,变量2=20
则sign(变量1-变量2)返回-1,decode解码结果为"变量1",达到了取较小值的目的。
Merge命令
通过这个merge你能够在一个SQL语句中对一个表同时执行inserts和updates操作. 当然是update还是insert是依据于你的指定的条件判断的,Merge into可以实现用B表来更新A表数据,如果A表中没有,则把B表的数据插入A表. MERGE命令从一个或多个数据源中选择行来updating或inserting到一个或多个表
merge into products p using newproducts np on (p.product_id = np.product_id)
when matched then
update set p.product_name = np.product_name
when not matched then
insert values(np.product_id, np.product_name, np.category)
TRUNC(number,num_digits)
Number 需要截尾取整的数字。
Num_digits 用于指定取整精度的数字。Num_digits 的默认值为 0。
Read Consistency(读一致性)
集合类型
使用条件:
a. 单行单列的数据,使用标量变量 。
b. 单行多列数据,使用记录
c. 单列多行数据,使用集合
*集合:类似于编程语言中数组也就是。pl/sql集合类型包括关联数组Associative array(索引表 pl/sql table)、嵌套表(Nested Table)、变长数组(VARRAY)。
Nested table与VARRY既可以被用于PL/SQL,也可以被直接用于数据库中,但是Associative array不行
Associative array是不能通过CREATE TYPE语句进行单独创建,只能在PL/SQL块(或Package)中进行定义并使用(即适用范围是PL/SQL Block级别)
Nested table与VARRAY则可以使用CREATE TYPE进行创建(即适用范围是Schema级别),它们还可以直接作为数据库表中列的类型
数字有三种基本类型:
NUMBER可以描述整数或实数
PLS_INTEGER和BINARY_INTENER只能描述整数
NUMBER,是以十进制格式进行存储的,但在计算中系统会自动转换成为二进制进行运算。例如:NUMBER(5,2)可以用来存储表示-999.99...999.99间的数值
BINARY_INTENER用来描述不存储在数据库中,但是需要用来计算的带符号的整数值。它以2的补码二进制形式表述。循环计数器经常使用这种类型。
PLS_INTEGER和BINARY_INTENER唯一区别:
在计算当中发生溢出时,BINARY_INTENER型的变量会被自动指派给一个NUMBER型而不会出错,PLS_INTEGER型的变量将会发生错误
DECLARE
TYPE ib_planguage IS TABLE OF VARCHAR2(10) INDEX BY PLS_INTEGER;
lang ib_planguage;
idx PLS_INTEGER;
BEGIN
lang(1):='java';
lang(9):='c#';
lang(3):='c++';
idx:=lang.FIRST;
WHILE(idx IS NOT NULL) LOOP
DBMS_OUTPUT.PUT_LINE(lang(idx));
idx:=lang.NEXT(idx);
END LOOP;
END;
与Associative array不同,Nested table变量需要显式初始化。Nested table初始化之后还需要调用EXTEND过程,扩展集合的"容量"
DECLARE
TYPE nt_planguage IS TABLE OF VARCHAR2(10);
lang nt_planguage;
BEGIN
lang:=nt_planguage('java','c#','c++');
FOR i IN 1..lang.COUNT LOOP
DBMS_OUTPUT.PUT_LINE(lang(i));
END LOOP;
END;
VARRAY可以在声明时限制集合的长度。其索引总是连续的,而Nested table的索引在初始化赋值时是连续的,不过随着集合元素被删除,可能变得不连续
DECLARE
TYPE va_planguage IS VARRAY(8) OF VARCHAR2(10);
lang va_planguage;
BEGIN
lang:=va_planguage('java','c#','c++');
FOR i IN 1..lang.COUNT LOOP
DBMS_OUTPUT.PUT_LINE(lang(i));
END LOOP;
END;
首选是Associative array,因为它不需要初始化或者EXTEND操作,并且是迄今为止最高效的集合类型。唯一不足的一点是它只能用于PL/SQL而不能直接用于数据库。
如果你需要允许使用负数索引,应该选择Associative array;
如果你需要限制集合元素的个数,应该选择VARRAY
DUAL表
dual是一个虚拟表,用来构成select的语法规则
select user from dual;
select to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss') from dual;--获得当前系统时间
select SYS_CONTEXT('USERENV','TERMINAL') from dual;--获得主机名
select SYS_CONTEXT('USERENV','language') from dual;--获得当前 locale
select dbms_random.random from dual;--获得一个随机数
select your_sequence.nextval from dual;--获得序列your_sequence的下一个值
select your_sequence.currval from dual;--获得序列your_sequence的当前值
select 7*9 from dual; --用做计算器
ASCII 返回与指定的字符对应的十进制数
CHR 给出整数,返回对应的字符
CONCAT 连接两个字符串
INITCAP 返回字符串并将字符串的第一个字母变为大写
INSTR(C1,C2,I,J) 在一个字符串中搜索指定的字符,返回发现指定的字符的位置
LENGTH 返回字符串的长度
LOWER 返回字符串,并将所有的字符小写
UPPER 返回字符串,并将所有的字符大写
RPAD和LPAD 粘贴字符
ADD_MONTHS增加或减去月份
LAST_DAY 返回日期的最后一天
MONTHS_BETWEEN 给出date2-date1的月份
PL/SQL基础
概述:
PL/SQL是Oracle对SQL的一种扩充,集成了程序化设计语言中的许多特性
PL/SQL的特点
过程化和模块化
使用过程化语言的控制结构
错误处理
可移植性
集成
改善性能
支持所有的事物控制命令
支持所有SQL的DML命令
支持所有SQL的DDL命令
支持所有SQL的DCL命令
支持所有SQL的数据类型、函数、各种运算符
PL/SQL程序块可以存储在服务器中,被其他程序或SQL命令调用
对PL/SQL程序块可以进行权限管理
PL/SQL中的Select语句
SELECT 列名,列名 . . . INTO 变量1,变量2 . . .
FROM 表 WHERE 条件 . . . ;
在使用SELECT …INTO…时,结果只能有一条,如果返回了多条数据或没有数据,则将产生错误。(对于多条记录的遍历,可以使用游标)
PL/SQL程序结构
-
PL/SQL程序的单元由逻辑块(BLOCK)组成
- 块可以顺序出现,也可以相互嵌套
- 每一个块分成三部分
[DECLEAR]
-- 说明部分(可选的)
BEGIN
-- 语句执行部分(必需的)
[EXCEPTION]
-- 出错处理程序(可选的)
END ;
/
PL/SQL类型
无名块:嵌入在应用内或交互式发出的无名块
有名块(应用的过程、函数):可以接受参数,并返回结果的有名块,存储在应用程序中。可以被反复调用。
存储过程、函数:可以接受参数,并返回结果的有名块,存储在服务器端。可以被反复调用
包:有名的PL/SQL模块,是相关的过程、函数、标识符的集合。存储在服务器端。可以被反复调用。
数据库出发器:与数据库表相关的PL/SQL块,存储在服务器端。在客户与服务器触发事件发生时自动触发。
应用触发器:与一个应用事件相关的PL/SQL块,存储在服务器端。在应用程序的触发事件时自动触发。
变量定义
变量 [CONSTANT] 数据类型 [NOT NULL] [:= DEFAULT PL/SQL 表达式];
V_num number(2) := 12 ;
没有赋初值的变量,初值都是NULL
变量类型
%TYPE和%ROWTYPE 类型
%TYPE:表示已经定义的变量类型定义
%ROWTYPE:表示已经定义的表、视图中的纪录的类型或游标的结构类型
优点
不必了解数据库中列的个数和数据类型
如果表结构改变,PL/SQL程序可以不变,减少程序的维护工作
V_EMPNO EMP.EMPNO%TYPE; /*EMP表名,EMPNO列名*/
V_REC EMP%ROWTYPE; /*EMP可以是表名或游标名*/
用户定义的类型
create or replace type student_type as object(
id number(5) ,
firstname varchar2(20) ,
lastname varchar2(20) ,
major varchar2(30) ,
current_credits number(3));
v_stu student_type ;
变量赋值
变量名:=常量 或 PL/SQL表达式
可在说明部分赋值,也可在执行部分赋值
DECLEAR
num_var number(5):=5; /*说明部分赋值*/
v_emp emp%rowtype;
BEGIN
v_emp.empno := 11011 ; /*执行部分赋值*/
……
select sal into num_var from emp where empno = 7788 ;
变量的作用范围
变量如果不在子块中重新定义,则在PL/SQL块的所有子块中有效
如果变量在子块内重新定义,子块内定义的变量优先,此变量的作用范围仅在本子块内有效。
如果主块中的变量A和子块变量A中同时定义时,在子块中要用主块的变量A时,必须在变量前加块的标识符(如:块的标识符.A)。
常用内置函数
函数 说明 转换前的类型
TO_CHAR 转换成VARCHAR类型 数字型、日期型
TO_DATE 转换成DATE 字符型
TO_NUMBER 转换成number类型 字符型
SELECT TO_CHAR (current_credits) INTO v_1 FROM student2 WHERE id = 1002
条件语句:
IF语句
DECLARE
v_sal emp.sal%type ;
BEGIN
SELECT sal INTO v_sal FROM emp WHERE empno = 7788;
IF v_sal < 500 THEN
UPDATE emp SET sal = sal * 1.5 WHERE empno = 7788;
ELSIF v_sal < 1500 THEN
UPDATE emp SET sal = sal * 1.3 WHERE empno = 7788;
ELSE
UPDATE emp SET sal = sal * 1.0 WHERE empno = 7788;
END IF;
COMMIT;
END;
/
<条件>是一个布尔型变量或表达式,取值只能是TRUE/FALSE/NULL
CASE语句:
CASE
WHEN grade= 'A' THEN dbms_output.put_line('excellent');
WHEN grade= 'B' THEN dbms_output.put_line('very good');
WHEN grade= 'C' THEN dbms_output.put_line('good');
WHEN grade= 'D' THEN dbms_output.put_line('fair');
WHEN grade= 'F' THEN dbms_output.put_line('poor);
ELSE dbms_output.put_line(' no such grade');
END CASE;
循环语句
Loop语句
DECLARE
v_counter number :=1;
BEGIN
LOOP
INSERT INTO temp_table VALUES(v_counter, 'loop index') ;
v_counter := v_counter + 1;
IF v_counter > 50 THEN
exit
END IF;
END LOOP;
END;
/
WHILE语句
DECLARE
v_counter number := 1 ;
BEGIN
WHILE v_counter <= 50 LOOP
INSERT INTO temp_table VALUES(v_counter, 'loop_index');
v_counter := v_counter + 1 ;
END LOOP;
END;
/
FOR语句
DECLARE
v_counter number :=1 ;
BEGIN
FOR v_counter IN 1..50 LOOP
INSERT INTO temp_table VALUES(v_counter,'loop index');
END LOOP ;
END;
/
FOR v_counter IN REVERSE 1..50 LOOP
其中:IN:表示索引变量的值小到大 IN REVERSE:表示索引变量的值从大到小
GOTO语句
DECLARE
v_vonter number := 1;
BEGIN
LOOP
INSERT INTO temp_table VALUES(v_counter, 'loop count');
v_counter := v_counter + 1 ;
IF v_counter > 50 THEN
GOTO ENDOFLOOP ;
END IF ;
END LOOP ;
<<ENDOFLOOP>>
INSERT INTO temp_table(char_col) VALUES('done!') ;
END;
对于块、循环或IF语句而言,想要从外层跳到内层是非法的
从一个IF子句调转到IF的另一个子句中是非法的
出错处理块不能实行跳转
异常处理
一个PL/SQL块的出错处理(EXCEPTION)部分包含程序处理多个错误的代码。当一个错误发生时,程序控制离开PL/SQL块的执行部分转移到出错处理部分。
. . .
BEGIN
. . .
EXCEPTION
WHEN 错误1 [ OR 错误2 ] THEN 语句序列 1 ;
WHEN 错误3 [ OR 错误4 ] THEN 语句序列 2 ;
. . .
WHEN OTHERS THEN 语句序列 3 ;
END ;
系统预定义错误 :在PL/SQL中经常出现的25个系统定义的错误,不必定义,允许服务器隐式地出发它们,只需要在出错处理部分处理它们
用户自定义错误:开发者认为是非正常的一个条件,必须在说明部分定义,在执行部分显示触发它们,在出错处理部分处理它们。
异常代码 异常名称 说明
ORA-01403 NO_DATA_FOUND 查询没有返回数据
ORA-01422 TOO_MANY_ROWS SELECT….INTO 语句返回多行结果
DECLARE
v_comm emp.comm%type ;
BEGIN
SELECT comm INTO v_comm
FROM emp WHERE empno = 7788 ;
EXCEPTION
WHEN no_data_found THEN
dbms_output.put_line( 'no data ! ' ) ;
WHEN too_many_rows THEN
dbms_output.put_line( 'too many row ! ' ) ;
WHEN others THEN
null ;
END ;
用户自定义的错误有三个步骤:定义错误,触发错误,处理错误
DECLARE
e_toomanystudent exception; /*定义错误*/
v_currentstudent number(3);
v_maxstudent number(3);
v_errorcode number;
v_errortext varchar2(200);
BEGIN
SELECT current_student , max_students INTO
v_currentstudent , v_maxstudent
FROM classe WHERE department = 'HIS' and course = 101 ;
IF v_currentstudent > v_maxstudent THEN
RAISE e_toomanystudent ; /*触发错误*/
END IF ;
EXCEPTION
WHEN no_data_found or too_many_rows THEN
dbms_output.putline('发生系统预定义错误') ;
WHEN e_toomanystudent THEN /*处理错误*/
INSERT INTO log_table(info)
VALUES('history 101 has' || v_currentstudent);
WHEN others THEN
v_errorcode = sqlcode ;
v_errortext = substr(sqlerrm,1,200)
INSERT INTO log_table(code , message , info )
VALUES(v_errorcode , v_errortext ,'Oracle error occured');
END ;
/
游标
游标是一个指向内存区域的指针,一个PL/SQL结构
游标有两种类型:显示游标和隐式游标
显示游标:是由程序员定义和命名的,并且在块的执行部分中通过特定语句操作的内存工作区。
隐式游标:是由PL/SQL为DML语句和SELECT语句隐式定义的工作区
显示游标的处理步骤
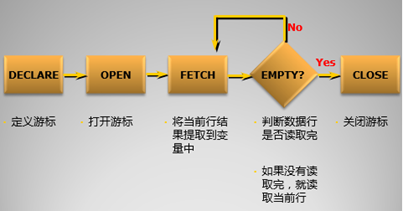
游标是一个不含INTO子句的SELECT语句
SELECT语句允许带WHERE,ORDER BY,GROUP BY等子句。
游标的定义
DECLARE
CURSOR emp_cursor IS
SELECT empno, ename
FROM emp;
CURSOR dept_cursor IS
SELECT *
FROM dept
WHERE deptno = 10;
BEGIN
...
打开游标
OPEN 游标名;
游标的处理
FETCH游标名INTO [变量1, 变量2, ...]| 纪录名];
FETCH emp_cursor INTO v_empno, v_ename;
DECLARE
CURSOR c_classes IS SELECT * FROM class;
v_classes c_classes%rowtype ;
BEGIN
. . .
OPEN c_classes;
FETCH c_classes INTO v_classes ;
. . .
END;
/
完成对行数据处理后,可以关闭游标,如果需要,还可以再次打开游标,关闭游标后,系统释放与该游标关联的资源,不能再对游标进行FETCH操作。
CLOSE c_classes;
显示游标的一些属性
%ISOPEN,%NOTFOUND,%FOUND,%ROWCOUNT
%ROWCOUNT Number 值是当前为止返回的记录数,初值为0,每取一条记录,该属性值加1。
LOOP
FETCH emp_cursor INTO v_ename , v_sal;
EXIT WHEN emp_cursor%ROWCOUNT>5 or emp_cursor%NOTFOUND;
...
END LOOP;
DECLARE
v_deptno emp.deptno%type :=&p_deptno;
v_ename emp.ename%type;
v_sal emp.sal%type;
CURSOR emp_cursor IS SELECT ename ,sal FROM emp
WHERE deptno = v_deptno;
BEGIN
OPEN emp_cursor;
LOOP
FETCH emp_cursor INTO v_ename , v_sal;
EXIT WHEN emp_cursor%NOTFOUND;
INSERT INTO temp(ename, sal) VALUES(v_ename,v_sal);
END LOOP;
CLOSE emp_cursor;
COMMIT;
END;
/
游标的FOR循环
使用游标的FOR循环,可以简化游标的操作步骤
游标的FOR循环隐式(自动)地完成三个步骤:打开游标;(FETCT)取数据;关闭游标
记录名师系统隐式定义的游标名%ROWTYPE类型的记录变量,不必事先定义
FOR 纪录名 IN 游标名 LOOP
语句1;
语句2;
...
END LOOP;
DECLARE
v_deptno emp.deptno%type := &p_deptno;
CURSOR emp_cursor IS SELECT ename ,sal FROM emp
WHERE deptno = v_deptno;
BEGIN
FOR emp_record IN emp_cursor LOOP
INSERT INTO temp(ename , sal)
VALUES(emp_record.ename , emp_record.sal);
END LOOP;
COMMIT; /*在本段程序中,没有打开游标、取数据、关闭游标语句*/
END;
/
要操纵数据库中数据,在定义游标的查询语句时,必须加上FOR UPDATE OF从句,表示要对表加锁。
表加锁后,在UPDATE或DELETE语句中,加WHERE CURRENT OF子句,既可以对锁定的数据进行修改
CURSOR 游标名IS
SELECT 列1,列2 … FORM 表 WHERE 条件
FOR UPDATE [OF column][NOWAIT];
带WHERE CURRENT O 从句的UPDATE语句和DELETE语句
DELETE FROM 表 WHERE CURRENT OF 游标名;
UPDATE 表 SET 列1=值1,列2=值2... WHERE CURRENT OF 游标名;
Eg:查询emp表某部门的雇员情况,如果雇员的工资小于800,则将其工资改为800
DECLARE
v_deptno emp.deptno%type :=&p_deptno;
v_empno emp.empno%type;
v_job emp.job%type;
v_sal emp.sal%type;
CURSOR emp_cursor IS SELECT ename,job,sal FROM emp
WHERE deptno = v_deptno FOR UPDATE OF sal;
BEGIN
FOR emp_record IN emp_cursor LOOP
IF emp_record.sal < 800 THEN
UPDATE emp SET sal=800 WHERE CURRENT OF emp_cursor;
END IF;
dbms_output.put_line(emp_record.empno||emp_record.sal);
END LOOP;
COMMIT;
END;
Eg:为职工增加10%的工资,从最低工资开始长,增加后工资总额限制在50万以内
DECLARE
emp_num number :=0; s_sal emp.sal%type;
e_sal emp.sal%type; e_empno emp.empno%type;
CURSOR c1 IS SELECT empno,sal FROM emp ORDER BY sal
FOR UPDATE OF sal;
BEGIN
OPEN c1;
SELECT sum(sal) INTO s_sal FROM emp;
WHILE s_sal < 500000
LOOP
FETCH c1 INTO e_empno,e_sal;
EXIT WHEN c1%NOTFOUND;
s_sal := s_sal + e_sal*0.1;
UPDATE emp SET sal=sal*1.1 WHERE CURRENT OF c1;
emp_num := emp_num + 1;
END LOOP;
CLOSE c1;
INSERT INTO msg VALUES(emp_num,s_sal);
COMMIT;
END;
带参数的游标
此参数只能在游标的查询语句中使用
只能向游标传递参数数值,不能通过参数带出结果
可以有选择地给参数提供一个默认值
CURSOR 游标名(参数1 数据类型[{:=|DEFAULT}值]
[,参数2 数据类型[{:=|DEFAULT]值] ...]
IS SELECT 语句 ;
DECLARE
CURSOR emp_cursor
(p_deptno NUMBER, p_job VARCHAR2) IS
SELECT empno, ename FROM emp
WHERE deptno = p_deptno
AND job = p_job;
BEGIN
OPEN emp_cursor(10, 'CLERK');
...
Eg:首先查询DEPT表取出所有的部门号,然后根据DEPT表中返回的每一个部门号,从emp表查询该部门的雇员信息
DECLARE
CURSOR dept_cursor IS SELECT deptno FROM dept;
v_ename emp.ename%type;
v_sal emp.sal%type;
CURSOR emp_cursor(v_deptno number) IS
SELECT ename, sal FROM emp WHERE deptno = v_deptno;
BEGIN
FOR dept_record IN dept_cursor LOOP
EXIT WHEN dept_cursor%NOTFOUND ;
OPEN emp_cursor(dept_record.deptno);
LOOP
FETCH emp_cursor INTO v_ename,v_sal;
EXIT WHEN emp_cursor%NOTFOUND;
dbms_output.put_line(dept_record.deptno ||' '||
' '||v_sal);
END LOOP;
CLOSE emp_cursor;
END LOOP;
COMMIT;
END;
隐式游标
由系统定义,不需要用户定义
用来处理INSERT,UPDATE,DELETE和单行的SELECT…INTO语句
游标名为SQL
游标的属性存储有关最近一次SQL命令的状态信息
BEGIN
UPDATE emp SET sal=10000,deptno=30 WHERE empno=9998;
IF SQL%NOTFOUND THEN
INSERT INTO emp(empno,sal,deptno) VALUES(9998,10000,30);
END IF;
COMMIT;
END;
隐式游标的游标属性%ISOPEN总是FALSE,因为当语句执行完后立即关闭隐式游标
SELEC….INTO语句只能执一行
存储过程
CREATE [OR REPLACE] PROCEDURE 过程名
[(参数名 [ IN | OUT | IN OUT ] 数据类型,... )]
{IS | AS}
[说明部分]
BEGIN
语句序列
[EXCEPTION 出错处理]
END [过程名];
OR REPLACE 是一个可选的关键字,表示替代原有的过程
IS或AS后面是一个完整的PL/SQL块的三部分(说明部分,执行部分,异常处理部分)
IN表示输入变量,OUT表示输出变量,IN OUT表示输入输出变量,缺省表示IN
CREATE OR REPLACE PROCEDURE modetest(
p_inpara IN number,
p_outpare OUT number,
p_inoutpara IN OUT number)
IS
v_local number;
BEGIN
v_local := p_inpara; /* IN类型参数不能出现在:=的左边 */
p_outpara := 7; /* OUT类型参数不能出现在:=的右边 */
v_local := p_inoutpara;
p_inoutpara := 7;
END;
CREATE PROCEDURE raise_salary(emp_id interger,v_increase integer)
IS /* 缺省IN */
BEGIN
UPDATE emp SET sal = sal + v_increase
WHERE empno = emp_id;
COMMIT;
END;
如果IN OUT参数的值在过程中没有被更改,则它返回到调用环境时值不变
如果IN OUT 参数是字符型,不能指定长度。长度有调用环境决定
函数
参数都是IN类型,存储函数必须返回并且只返回一个结果
函数体的可执行部分必须有RETURN语句(RETURN 表达式)
表达式的数值类型与RETURN子句定义要一致
CREATE OR REPLACE FUNCTION get_sal (p_emp_no IN empno%TYPE)
RETURN NUMBER
IS
v_emp_sal emp.sal%TYPE :=0;
BEGIN
SELECT sal INTO v_emp_sal FROM emp WHERE empno=p_emp_no;
RETURN(v_emp_sal);
EXCEPTION
WHEN no_data_found or too_many_rows THEN
dbms_output.put_line('System Error');
WHEN others THEN
dbms_output.put_line(sqlerrm);
END get_sal;
/
CREATE OR REPLACE FUNCTION average_sal(v_n IN number(3))
RETURN NUMBER
IS
CURSOR c_emp IS SELECT empno ,sal FROM emp;
v_total_sal emp.sal%TYPE;
v_counter number;
v_emp_no emp.empno%TYPE;
BEGIN
FOR r_emp IN c_emp LOOP
EXIT WHEN c_emp%ROWCOUNT > v_n OR c_emp%NOTFOUND;
v_total_sal := v_total_sal + r_emp.sal;
v_counter := c_emp%ROWCOUNT;
v_emp_no := r_emp.empno;
dbms_output.putline('loop='||v_counter||
';empno='||v_emp_no);
END LOOP;
RETURN(v_total_sal/v_counter);
END average_sal;
/
过程和函数
参数类型不同:函数只有IN类型参数,而存储有IN,OUT,IN OUT三个类型参数
返回值的方法不同:函数返回只有一个值,而存储过程返回值由OUT参数带出来
调用方法不同:
过程(实际参数1,实际参数2……);
变量名:=函数名(实际参数1,实际参数2….);
过程/函数中的异常处理
CREATE OR REPLACE PROCEDURE fire_emp(
p_emp_no IN emp.empno%TYPE)
IS
invalid_employee EXCEPTION; /*定义错误*/
BEGIN
DELETE FROM emp WHERE empno = p_emp_no ;
IF SQL%NOTFOUND THEN
RAISE invalid_employee; /*触发错误*/
END IF;
EXCEPTION
WHEN invalid_employee THEN ROLLBACK;
INSERT INTO exception_table(line_nr,line)
VALUES(1,'employee does not exist.');
WHEN others THEN
dbms_output.putline(sqlerrm);
END fire_emp;
/
在SQL*Plus中使用过程/函数
在SQL*Plus中,用VARIABLE定义的变量在引用时,必须前面加冒号(:)。用ACCEPT接受的变量在引用时,前面加&符号。
SET SERVEROUTPUT ON
ACCEPT p_emp_no PROMPT 'please enter the employee number:'
VARIABLE v_emp_name varchar2(14);
VARIABLE v_emp_sal number;
VARIABLE v_emp_comm number;
EXECUTE query_emp(&p_emp_no,:v_emp_name,
:v_emp_sal,:v_emp_comm);
EXECUTE dbms_output.putline('Infomation for employee:'
|| to_char(&p_emp_no));
EXECUTE dbms_output.putline('The name is:'|| :v_emp_name);
EXECUTE dbms_output.putline('The salary is:'
|| to_char(:v_emp_sal));
EXECUTE dbms_output.putline(The commission is:'
|| to_char(:v_emp_comm));
包
包是一个可以将相关对象存储在一起的PL/SQL结构
它包含了两个分离的组成部分:包说明和包主体
包的组成
可以将相关的若干程序单元组织到一块,用一个包名来标识这个集合
包中可以包含的程序单元
过程,函数,变量,游标,类型,常量,出错情况
CREATE [OR REPLACE] PACKAGE 包名
{IS | AS}
公共变量的定义 |
公共类型的定义 |
公共出错处理的定义 |
公共游标的定义 |
函数说明 |
过程说明
END;
/
CREATE PACKAGE sal_package IS
PROCEDURE raise_sal(v_empno emp.empno%TYPE,
v_sal_increment emp.sal%TYPE);
PROCEDURE reduce_sal(v_empno emp.empno%TYPE,
v_sal_reduce emp.sal%TYPE);
v_raise_sal emp.sal%TYPE :=0;
v_reduce_sal emp.sal%TYPE :=0;
END;
/
CREATE [OR REPLACE] PACKAGE BODY 包名
{IS | AS}
私有变量的定义 |
私有类型的定义 |
私有出错处理的定义 |
私有游标的定义 |
函数定义 |
过程定义
END ;
/
CREATE PACKAGE BODY sal_package IS
PROCEDURE raise_sal(v_empno emp.empno%TYPE,
v_sal_increment emp.sal%TYPE)
IS
BEGIN
UPDATE emp SET sal = sal + v_sal_increment
WHERE empno = v_empno;
COMMIT WORK;
v_raise_sal := v_raise_sal + v_sal_increment;
END;
PROCEDURE reduce_sal(v_empno emp.empno%TYPE,
v_sal_reduce emp.sal%TYPE)
IS
BEGIN
UPDATE emp SET sal = sal – v_sal_reduce
WHERE empno = v_empno;
COMMIT WORK;
v_reduce_sal := v_reduce_sal + v_sal_reduce;
END;
END;
所有提供的Package由SYS所拥有,对于不是SYS的用户,必须拥有EXCEUTE权限才能调用
所有Oracle提供的程序包都是以DBMS_或UTL_开头
静态SQL
静态SQL指直接嵌入在PL/SQL块中的SQL语句,静态SQL用于完成特定或固定的任务。
select sal from emp where empno=4000;
动态SQL
动态SQL运行PL/SQL块时动态输入的SQL语句。如果在PL/SQL需要执行DDL语句,DCL语句,或则需要执行更加灵活的SQL语句(select中有不同where条件),需要用到用到动态SQL。
编写动态SQL语句时,需要将SQL语句存放到字符串变量中,而且SQL语句可以包含占位符(以冒号开始)。
v_sql varchar2(100);
v_sql:='delete from emp where empno =:v_empno';
//删除某个表
create or replace procedure pro_drop_table(v_table_name varchar2)
is
v_sql varchar2(100);
begin
v_sql := 'drop table ' || v_table_name;
execute immediate v_sql;
end;
BEGIN
FOR I IN 1 .. 100 LOOP
BEGIN
EXECUTE IMMEDIATE 'DROP TABLE T'||I;
EXCEPTION
WHEN OTHERS THEN NULL;
END;
EXECUTE IMMEDIATE 'CREATE TABLE T'||I||' ( DUMMY CHAR(1) )';
EXECUTE IMMEDIATE 'INSERT INTO T'||I||' VALUES ( ''X'' )';
END LOOP;
END;
/
将字符串每个逗号字符用方括号进行封装
declare
t_vararray dbms_utility.lname_array;
vc_stringlist varchar2(4000);
n_idx binary_integer;
begin
--comma to table
vc_stringlist := 'dkf,dddl,fewe,klkj';
dbms_utility.comma_to_table(vc_stringlist, n_idx, t_vararray);
dbms_output.put_line('Total Num : '||to_char(n_idx));
for i in 1..n_idx loop
dbms_output.put_line(t_vararray(i));
t_vararray(i) := '['||t_vararray(i)||']';
end loop;
--table to comma
dbms_utility.table_to_comma(t_vararray, n_idx, vc_stringlist);
dbms_output.put_line('');
dbms_output.put_line(vc_stringlist);
end;
结果
Total Num : 4
dkf
dddl
fewe
klkj
[dkf],[dddl],[fewe],[klkj]
DECLARE
l_temp NUMBER;
BEGIN
l_temp := DBMS_UTILITY.get_time;
dbms_output.put_line('before=' || l_temp);
dbms_lock.sleep(5);
l_temp := DBMS_UTILITY.get_time;
dbms_output.put_line('after=' || l_temp);
END;
/
before=59955835
after=59956335
DECLARE
l_temp NUMBER;
BEGIN
l_temp := DBMS_UTILITY.get_cpu_time;
dbms_output.put_line('before=' || l_temp);
dbms_lock.sleep(5);
l_temp := DBMS_UTILITY.get_cpu_time;
dbms_output.put_line('after=' || l_temp);
END;
/
before=10
after=10
触发器
触发器由说明部分,语句执行部分和出错处理部分三部分组成的PL/SQL有名块(类似于存储过程和函数)
触发器不接受参数,不能再程序中调用
当触发事件发生时隐式地(自动地)执行
触发事件包括:在数据库中执行如下操作
INSERT
UPDATE
DELETE
将超过某工种工资范围的员工信息纪录到aduit_message表中。sal_guide表纪录了每一工种的工资范围
CREATE OR REPLACE TRIGGER check_sal
BEFORE INSERT OR UPDATE OF sal,job ON emp FOR EACH ROW
WHEN (new.job <> 'PRESIDENT')
DECLAER
v_minsal sal_guide.minsal%TYPE;
v_maxsal sal_guide.maxsal%TYPE;
e_sal_out_of_range EXCEPTION;
BEGIN
SELECT minsal , maxsal INTO v_minsal , v_maxsal
FROM sal_guide WHERE job = :new.job;
IF (:new.sal < v_minsal) OR (:new.sal > v_maxsal) THEN
RAISE e_sal_out_of_range;
END IF;
EXCEPTION
WHEN e_sal_out_range THEN
INSERT INTO audit_message(line_nr,line)
VALUES(1,'salary'||to_char(:new.sal)||
'is out of range for employee'||to_char(:new.empno));
END ;
触发器类型:语句级和行级
触发事件:表的插入,更新,删除
触发时间:BEFORE和AFTER
触发器分语句级和行级触发器两个级别
行级触发器与语句级触发器的区别主要在于触发次数不同
如果DML语句只影响一行,则语句级和行级触发器效果一样
如果该DML语句影响多行,则行级触发器触发的次数比语句级触发器触发的次数多
语句之前触发->行之前触发->插入、更新、删除一条记录->行之后出发->语句之后触发
在触发器体内禁止使用COMMIT,ROLLBACK语句
事件指明触发事件的数据操纵语句,有三种可能的值:INSERT,UPDATE,UPDATE OF 列名1,DELETE
该触发器在一个数据操作语句发生时只触发一次
CREATE [OR REPLACE] TRIGGER 触发器名
{BEFORE | AFTER} 事件1 [OR 事件2 ...] ON 表名
PL/SQL 块;
Eg:创建一个BEFORE型语句级触发器。限制一周内向emp表插入数据的时间,如果是周六、周日,或晚上6点到第二天早上8点之间插入,则中断操作,并提示用户不允许在此时间向emp表插入
CREATE OR REPLACE TRIGGER secure_emp
BEFORE INSERT ON emp
BEGIN
IF (TO_CHAR(sysdate,'DY') IN( 'SAT','SUN')
OR (TO_CHAR(sysdate,'HH24') NOT BETWEEN '8' AND '18')
THEN RAISE_APPLICATION_ERROR(-20500,'you may only
insert emp during normal hours.');
END IF;
END;
使用触发谓词(INSERTING,UPDATING,DELETING)
触发器可以包含多个触发事件,在触发器中使用谓词判断是哪个触发了触发器
谓词 行为和值
INSERTING 如果触发事件是INSERTING,则谓词的值为TRUE,否则为FALSE
CREATE OR REPLACE TRIGGER secure_emp
BEFORE DELETE OR INSERT OR UPDATE ON emp
BEGIN
IF (TO_CHAR(sysdate,'DY') IN( 'SAT','SUN') OR
(TO_CHAR(sysdate,'HH24') NOT BETWEEN '8' AND '18') THEN
IF DELETING THEN
RAISE_APPLICATION_ERROR(-20502,'you may only
delete emp during normal hours.');
ELSIF INSERTING THEN
RAISE_APPLICATION_ERROR(-20500,'you may only
insert emp during normal hours.');
ELSE THEN
RAISE_APPLICATION_ERROR(-20504,'you may only
update emp during normal hours.');
END IF;
END IF;
END;
通过在CREATE TRIGGER 语句中指定FOR EACH ROW 子句创建一个行触发器
CREATE [OR REPLACE] TRIGGER 触发器名
{BEFORE | AFTER} 事件1 [OR 事件2 ...] ON 表名
FOR EACH ROW [WHEN 限制条件]
PL/SQL 块;
Eg:将每个用户对数据库emp表进行数据操纵(插入、更新、删除)的次数纪录到audit_table表中
CREATE OR REPLACE TRIGGER audit_emp
AFTER DELETE OR INSERT OR UPDATE ON emp FOR EACH ROW
BEGIN
IF DELETING THEN
UPDATE audit_table SET del = del + 1
WHERE user_name = user AND table_name = 'emp'
AND colun_name IS NULL;
ELSIF INSERTING THEN
UPDATE audit_table SET ins = ins + 1
WHERE user_name = user AND table_name = 'emp'
AND colun_name IS NULL;
ELSE THEN
UPDATE audit_table SET upd = upd + 1
WHERE user_name = user AND table_name = 'emp'
AND colun_name IS NULL;
END IF;
END;
使用行级触发器的标识符(:OLD和:NEW)
在行级触发器中,列名前加上:OLD标识符表示该列变化前的值,加上:NEW标识符表示变化后的值
在BEFORE型行级触发器和AFTER型行级触发器中使用这些标识符
在语句级触发器中不要使用这些标识符
在触发器体的SQL语句或PL/SQL语句中使用这些标识符时,前加冒号(:)
在行级触发器的WHEN限制条件中使用这些标识符时,前面不要加冒号(:)
Eg:在行级触发器中获取某列的新值和旧值,为emp表中的所有数据保留一个历史档案
CREATE OR REPLACE TRIGGER audit_emp_values
AFTER DELETE OR INSERT OR UPDATE ON emp FOR EACH ROW
BEGIN
INSERT INTO audit_emp(user_name,timestamp,empno,
old_ename,new_ename,old_job,new_job,
old_sal,new_sal)
VALUES(USER,SYSDATE,:old.empno,:old.ename,
:new.ename,:old.job,:new.job,:old.sal,:newsal);
END;
Eg:在行级触发器加WHEN限制条件。根据销售员工资的改变自动计算销售员的奖金
CREATE OR REPLACE TRIGGER derive_comm
BEFORE UPDATE OF sal ON emp FOR EACH ROW
WHEN (new.job = 'SALESMAN')
BEGIN
:new.comm := :old.comm * (:new.sal/:old.sal);
END;
CREATE TIGGER
CREATE OR REPLACE TRIGGER
DROP TRIGGER
SYSTEM触发器
DDL触发器
INSTEAD OF 触发器
instead of trigger 是基于视图建立的,不能建在表上,为什么要建在视图上,一般的视图如果其数据来源一个表并且包含该表的主键,就可以对视图进行DML操作.另外一种情况是 从多个表查询出来的.这样我们就不能对视图进行操作了,也就是只能查询.instead of trigger可以解决建在多表上视图的更新操作.

BULK DML
Oracle引入了两个DML语句: BUKL COLLECT 和 FORALL
这两个语句在PL/SQL内部进行以一种数据处理
BUKL COLLECT 提供对数据的高速检索
FORALL 可大大改进INSERT,UPDATE和DELETE操作的性能
Oracle数据库使用这些语句大大减少了PL/SQL与SQL语句执行引擎的环境切换次数,从而使其性能有了显著提高
DECLARE
TYPE books_aat IS TABLE OF book%ROWTYPE
INDEX BY PLS_INTEGER;
my_books books_aat;
BEGIN
SELECT * BULK COLLECT INTO my_books
FROM book WHERE title LIKE '%PL/SQL%';
...
END;
CREATE TYPE books_nt
IS TABLE OF book%ROWTYPE;
CREATE OR REPLACE PROCEDURE add_books ( books_in IN books_nt)
IS
BEGIN
FORALL book_index
IN books_in.FIRST .. books_in.LAST
INSERT INTO book VALUES books_in(book_index);
...
END;
DECLARE
Type region_id_tbl IS TABLE of NUMBER INDEX BY BINARY_INTEGER;
Type region_name_tbl IS TABLE of VARCHAR2(20) INDEX BY BINARY_INTEGER;
region_ids region_id_tbl; region_names region_name_tbl; ret_code NUMBER;
ret_errmsg VARCHAR2(1000);
Procedure load_regions_bulk_bind (region_ids IN region_id_tbl, region_names IN region_name_tbl,
retcd OUT NUMBER, errmsg OUT VARCHAR2)
IS
BEGIN
-- clean up the region_tab table initially.
DELETE FROM region_tab;
FORALL i IN region_ids.FIRST..region_ids.LAST
INSERT INTO region_tab values (region_ids(i), region_names(i));
Retcd := 0;
EXCEPTION
WHEN OTHERS THEN
COMMIT;
Retcd := SQLCODE;
Errmsg := SQLERRM;
END;
BEGIN
FOR i IN 1..5 LOOP
Region_ids(i) := i; Region_names(i) := 'REGION'||i;
END LOOP;
Load_regions_bulk_bind(region_ids, region_names, ret_code, ret_errmsg);
EXCEPTION WHEN OTHERS THEN
RAISE_APPLICATION_ERROR(-20112, SQLERRM);
END;
什么时候使用FORALL
FORALL可以大量的提高从源表或者视图到目标表的插入,更新,删除,合并操作
如果FORALL的调用集合中缺失一个元素那么错误将会发生
如果一个行级别的发生那么整个进程将会停止
DECLARE
t_outtab_type IS TABLE OF input_table%ROWTYPE;
v_outtab t_outtab_type;
BEGIN
SELECT * BULK COLLECT INTO v_outtab
FROM input_table
WHERE key_col = '<val1>';
FOR i IN 1..v_outtab.COUNT LOOP
-- Process the rows one by one according to required logic.
END LOOP;
END;
/
DECLARE
t_outtab_type IS TABLE OF input_table%ROWTYPE;
v_outtab t_outtab_type;
CURSOR c_in IS SELECT * FROM input_table
WHERE key_col = '<val1>';
BEGIN
OPEN c_in;
FETCH c_in BULK COLLECT INTO v_outtab;
FOR i IN 1..v_outtab.COUNT LOOP
-- Process the rows one by one according to required logic.
END LOOP;
CLOSE c_in;
END;
/
DECLARE
t_outtab_type IS TABLE OF input_table%ROWTYPE;
v_outtab t_outtab_type;
CURSOR c_in IS SELECT * FROM input_table
WHERE key_col = '<val1>';
BEGIN
OPEN c_in;
FETCH c_in BULK COLLECT INTO v_outtab;
FOR i IN 1..v_outtab.COUNT LOOP
-- Process the rows one by one according to required logic.
END LOOP;
CLOSE c_in;
END;
/
用bulk query的主要有点,
减少运行的时间,更少的延时
如果取得的数据很大的话,那么回增加内存的消耗
可以通过特定的limite数量来控制取得的数量
DECLARE
t_outtab_type IS TABLE OF input_table%ROWTYPE;
v_outtab t_outtab_type;
CURSOR c_in IS SELECT * FROM input_table WHERE key_col = '<val1>';
BEGIN
OPEN c_in;
LOOP
FETCH c_in BULK COLLECT INTO v_outtab LIMIT 100;
FOR i IN 1..v_outtab.COUNT LOOP
-- Process the rows one by one according to required logic.
NULL;
END LOOP;
EXIT WHEN c_in%NOTFOUND;
END LOOP;
CLOSE c_in;
END;
/
自治事物
自治事物允许你在一个事务中创建一个事务,这个事务将会独立于父事务进行提交,回滚等改变
允许你挂起现在正在执行的事务,开始一个新的事务,做一些工作,提交回滚,所有的这些事情不会影响当前正在执行事务的状态
通过pragma autonomous_transaction将一个pl/sql程序结构设定为自治事务,pragma是编译器指令,可以将procedure function package等顶级匿名块定义成自治的程序结构。
create or replace trigger EMP_AUDIT
before update on emp for each row
declare
pragma autonomous_transaction;
l_cnt number;
begin
select count(*) into l_cnt from dual
where EXISTS ( select null from emp where empno = :new.empno
start with mgr = ( select empno from emp where ename = USER )
connect by prior empno = mgr );
if ( l_cnt = 0 ) then
insert into audit_tab ( msg )
values ( 'Attempt to update ' || :new.empno );
commit;
raise_application_error( -20001, 'Access Denied' );
end if;
end;
/
绑定变量
下面的代码每次都要硬编码
create or replace procedure dsal(p_empno in number)
as
begin
execute immediate
'update emp set sal = sal*2
where empno = '||p_empno;
commit;
end;
通过如下改变就可以了
create or replace procedure dsal(p_empno in number)
as
begin
execute immediate
'update emp set sal = sal*2
where empno = :x' using p_empno;
commit;
end;
游标变量 : 声明游标实际上是创建一个指针 , 指针具有数据类型 REF X.REF 是 REFERENCE ,X 是表示类对象 . 因此 , 游标变量具有数据类型 REF CURSOR.
注 : 游标总是指向相同的查询工作区 , 游标变量能够指向不同的工作区 , 因此游标和游标变量不能互操作 .
DECLARE
TYPE empcurtyp IS REF CURSOR RETURN employees%ROWTYPE;
emp empcurtyp;
-- after result set is built, process all the rows inside a single procedure
-- rather than calling a procedure for each row
PROCEDURE process_emp_cv (emp_cv IN empcurtyp)
IS
person employees%ROWTYPE;
BEGIN
DBMS_OUTPUT.PUT_LINE('-----');
DBMS_OUTPUT.PUT_LINE('Here are the names from the result set:');
LOOP
FETCH emp_cv INTO person;
EXIT WHEN emp_cv%NOTFOUND;
DBMS_OUTPUT.PUT_LINE('Name = ' || person.first_name || ' ' || person.last_name);
END LOOP;
END;
BEGIN
-- First find 10 arbitrary employees.
OPEN emp FOR SELECT * FROM employees WHERE ROWNUM < 11;
process_emp_cv(emp);
CLOSE emp;
-- find employees matching a condition.
OPEN emp FOR SELECT * FROM employees WHERE last_name LIKE 'R%';
process_emp_cv(emp);
CLOSE emp;
END;