选择排序(Selection sort)是一种简单直观的排序算法。无论什么数据进去都是 O(n²) 的时间复杂度。所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。
简单排序处理流程
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
重复第二步,直到所有元素均排序完毕。
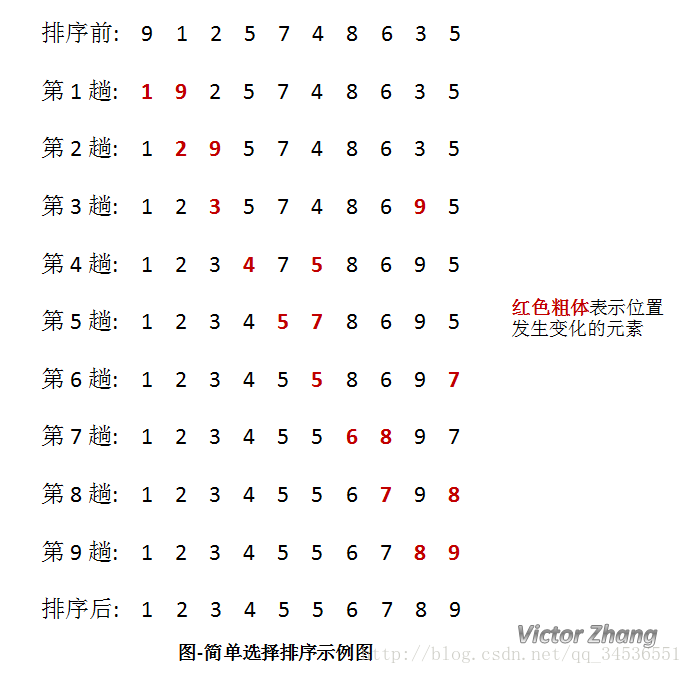
算法演示

如图所示,每趟排序中,将当前第 i 小的元素放在位置 i 上。
选择排序的主要优点与数据移动有关。如果某个元素位于正确的最终位置上,则它不会被移动。选择排序每次交换一对元素,它们当中至少有一个将被移到其最终位置上,因此对n个元素的表进行排序总共进行至多n-1次交换。在所有的完全依靠交换去移动元素的排序方法中,选择排序属于非常好的一种。
下面看我的代码示例: 该代码中添加了一个标志flag, 这样当 数据是有序的时候,一次循环比较就可以了, 否则的话, 循环比较 N-1次, 大家可以我的代码。复制到编译器上学, 效率更好。
#include<iostream>
#include<cassert>
using namespace std;
class SqList
{
public:
SqList(size_t sizeElem);
~SqList();
void printElem();
void swapElem(int &a, int &b);
void selectSort();
void create(const size_t length);
private:
int *m_base; //指向数组
int m_length; //记录数组中的个数
};
SqList::SqList(size_t sizeElem)
{
m_base = new int[sizeElem];
assert(m_base != nullptr);
m_length = 0;
}
SqList::~SqList()
{
delete m_base;
m_base = nullptr;
}
void SqList::create(const size_t length)
{
m_length = length;
cout << "请分别输入你想排序的这" << length << "个元素,中间以回车键隔开:\n";
for (size_t i = 0; i != length; ++i)
{
cin >> m_base[i];
}
cout << endl;
}
void SqList::printElem()
{
for (size_t i = 0; i != m_length; ++i)
{
cout << m_base[i] << " ";
}
cout << endl;
}
void SqList::swapElem(int &a, int &b)
{
int temp = a;
a = b;
b = temp;
}
void SqList::selectSort()
{
int count = 0;
bool flag = true;
for (int i = 0; i < m_length - 1 && flag; ++i) //m_length - 1是因为数组的下标是从0开始的
{
flag = false;
int min = i; //每次将min设置成无序数组起始的位置元素的下标
for (int j = i + 1; j < m_length; ++j) /*遍历无序数组,找到最小元素。
一开始j从下标1开始,就是第二个数
j一开始循环的时候,就是无须数组的第二个位置,i是无须数组的第一个位置
j会随着循环不断的跟下标为i的数据进行比较
,如果j位置的数据小,就跟i位置的数据交换*/
{
if (m_base[min] > m_base[j])
{
min = j; //如果发现比当前最小元素还小的元素,则更新记录最小元素的下标,min始终记录当前遵循中最小的元素下标
}
}
if (min != i) /*如果最小元素不是无序数组起始位置元素,则与起始元素交换位置 ,
交换后当前最小的元素是到无序数组的第一个数字,
那么原来无序数组的第一个数字则被交换到以前当前最小元素的位置*/
{
swap(m_base[min], m_base[i]);
flag = true;
}
++count;
}
cout << " 选择排序花了" << count << "趟完成了排序!" << endl;
}
int main()
{
{
int sizeCapacity(0);
cout << "输入数组的最大容量:";
cin >> sizeCapacity;
SqList mySqList(sizeCapacity);
while (true)
{
{
cout << "\n************************ 欢迎来到来到标志选择排序的世界!**********************\n" << endl
<< "输入0,退出程序!" << endl
<< "输入1,进行选择排序!" << endl
<< "输入2,清屏!" << endl;
}
cout << "************************* 请输入你想要使用的功能的序号 **********************" << endl;
int select(0);
cout << "请输入你的选择:";
cin >> select;
if (!select)
{
cout << "程序已退出,感谢你的使用!" << endl;
break;
}
switch (select)
{
case 1:
{
cout << "请输入你想排序数组元素的个数:";
int arraySize(0);
cin >> arraySize;
assert(arraySize != 0);
mySqList.create(arraySize);
cout << "先输出排序前的元素:";
mySqList.printElem();
mySqList.selectSort();
cout << "再输出排序后的元素:";
mySqList.printElem();
break;
}
case 2:
system("cls");
cout << "程序已清屏!可以重新输入!" << endl;
break;
default:
cout << "输入的序号不正确,请重新输入!" << endl;
}
}
}
system("pause");
return 0;
}
该数组序列,花了5次循环比较,数据就正序了, 如果没有flag, 要花8次。
不过下面的复杂度分析,写的是简单的选择排序的复杂度, 上面的代码灵感,是来自标志冒泡排序, 所以我就在选择排序上,也加了个flag。 大家凑合着看吧。
复杂度分析
选择排序的交换操作介于和 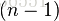

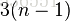
比较次数O(n^2),比较次数与关键字的初始状态无关,总的比较次数N=(n-1)+(n-2)+…+1=n*(n-1)/2。 交换次数O(n),最好情况是,已经有序,交换0次;最坏情况是,逆序,交换n-1次。 交换次数比冒泡排序少多了,由于交换所需CPU时间比比较所需的CPU时间多,n值较小时,选择排序比冒泡排序快。
平均时间复杂度:O(n2), 这就意味值在n比较小的情况下,算法可以保证一定的速度,当n足够大时,算法的效率会降低。并且随着n的增大,算法的时间增长很快。因此使用时需要特别注意。
稳定性:不稳定 (比如序列【5, 5, 3】第一趟就将第一个[5]与[3]交换,导致第一个5挪动到第二个5后面)
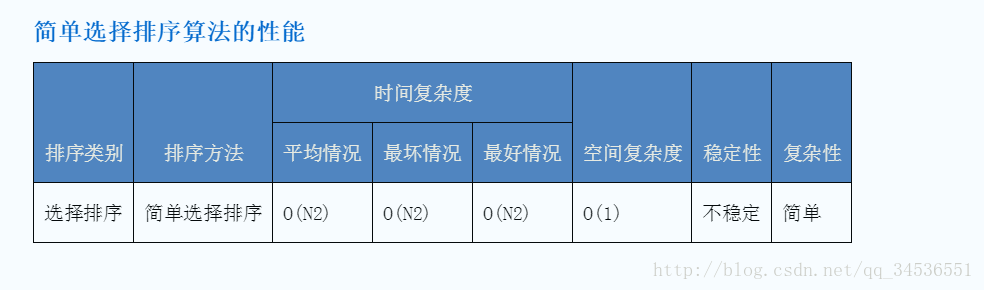
时间复杂度
简单选择排序的比较次数与序列的初始排序无关。 假设待排序的序列有 N 个元素,则比较次数总是N (N - 1) / 2。
而移动次数与序列的初始排序有关。当序列正序时,移动次数最少,为 0.
当序列反序时,移动次数最多,为3N (N - 1) / 2。
所以,综合以上,简单排序的时间复杂度为 O(N2)。
空间复杂度
简单选择排序需要占用 1 个临时空间,在交换数值时使用,O(1) (用于交换和记录索引)