1、缓冲区和subprocess模块
1.1 缓冲区
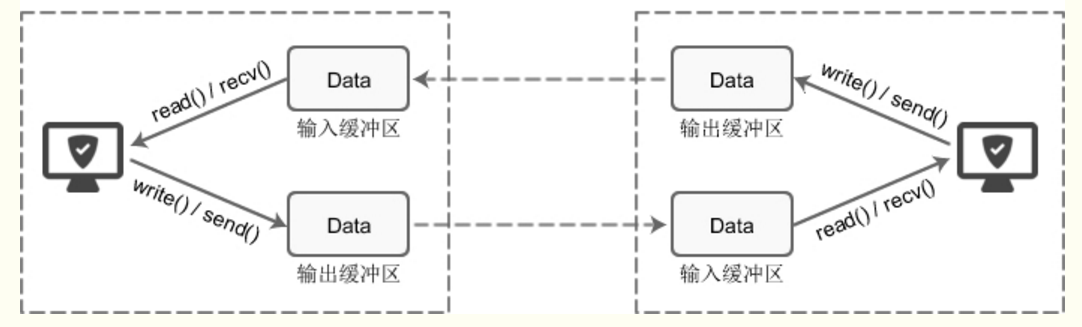
每个 socket 被创建后,都会分配两个缓冲区,输入缓冲区和输出缓冲区。
write()/send() 并不立即向网络中传输数据,而是先将数据写入缓冲区中,再由TCP协议将数据从缓冲区发送到目标机器。一旦将数据写入到缓冲区,函数就可以成功返回,不管它们有没有到达目标机器,也不管它们何时被发送到网络,这些都是TCP协议负责的事情。
TCP协议独立于 write()/send() 函数,数据有可能刚被写入缓冲区就发送到网络,也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络,这取决于当时的网络情况、当前线程是否空闲等诸多因素,不由程序员控制。
read()/recv() 函数也是如此,也从输入缓冲区中读取数据,而不是直接从网络中读取。
2.2 解释器调用系统指令----> subprocess


1 import subprocess # 解释器操作cmd的模块 2 recv_msg = input("输入cmd命令: ") 3 cmd_obj = subprocess.Popen( 4 recv_msg, # 输入的cmd指令,"dir", "ipconfig" ...... 5 shell=True, # shell = True, 即相当于使用cmd窗口 6 stdout=subprocess.PIPE, # 标准输出信息都在PIPE管道中 7 stderr=subprocess.PIPE, # 出错信息也在PIPE管道中 8 ) 9 cmd_msg = cmd_obj.stdout.read().decode("gbk") # 对象调用里面的stdout属性, 并读取出来.(和计算机交互一般都以GBK编码解码) 10 print(cmd_msg)
2、黏包
现象1: 连续send两个比较小点的数据时, TCP的Nagle算法和延迟ACK机制, 减少大量小包的连续发送, 所以会将比较小的连续发送的数据合并成一个比较大的包, 这是第一种黏包;
现象2: send()给缓冲区扔了太多数据, 超过缓冲区的大小就会报错, 每个IP包一般最大为1500b, 如果超过这个值就会被拆包发送, 第一次剩下的数据有可能和第二次发送的数据一起连在一起被接收, 这就是第二种黏包;
3、
4、
5、