MapReduce-提交job源码分析
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.环境准备
1>.顺手的IDE,大家可以根据自己的喜好选择你喜欢的IDE
博主推荐以下2款IDE,大家可以自行百度官网,也看看我之前调研的笔记:
eclipse:https://www.cnblogs.com/yinzhengjie/p/8733302.html
idea:https://www.cnblogs.com/yinzhengjie/p/9080387.html(我比较推荐它,挺好使的,而且我们公司的好多开发也在用它开发呢~)
2>.编写Wordcount代码


/* @author :yinzhengjie Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/ EMAIL:[email protected] */ package mapreduce.yinzhengjie.org.cn; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ Text k = new Text(); IntWritable v = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 获取一行 String line = value.toString(); // 2 切割 String[] words = line.split(" "); // 3 输出 for (String word : words) { k.set(word); context.write(k, v); } } }
/* @author :yinzhengjie Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/ EMAIL:[email protected] */ package mapreduce.yinzhengjie.org.cn; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> value, Context context) throws IOException, InterruptedException { // 1 累加求和 int sum = 0; for (IntWritable count : value) { sum += count.get(); } // 2 输出 context.write(key, new IntWritable(sum)); } }
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/ 4 EMAIL:[email protected] 5 */ 6 package mapreduce.yinzhengjie.org.cn; 7 8 import java.io.IOException; 9 import org.apache.hadoop.conf.Configuration; 10 import org.apache.hadoop.fs.Path; 11 import org.apache.hadoop.io.IntWritable; 12 import org.apache.hadoop.io.Text; 13 import org.apache.hadoop.mapreduce.Job; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 17 public class WordcountDriver { 18 19 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 20 21 //配置Hadoop的环境变量,如果没有配置可能会抛异常:“ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path”,还有一件事就是你的HADOOP_HOME的bin目录下必须得有winutils.exe 22 System.setProperty("hadoop.home.dir", "D:/yinzhengjie/softwares/hadoop-2.7.3"); 23 24 //获取配置信息 25 Configuration conf = new Configuration(); 26 Job job = Job.getInstance(conf); 27 28 //设置jar加载路径 29 job.setJarByClass(WordcountDriver.class); 30 31 //设置map和Reduce类 32 job.setMapperClass(WordcountMapper.class); 33 job.setReducerClass(WordcountReducer.class); 34 35 //设置map输出 36 job.setMapOutputKeyClass(Text.class); 37 job.setMapOutputValueClass(IntWritable.class); 38 39 //设置Reduce输出 40 job.setOutputKeyClass(Text.class); 41 job.setOutputValueClass(IntWritable.class); 42 43 //设置输入和输出路径 44 FileInputFormat.setInputPaths(job, new Path(args[0])); 45 FileOutputFormat.setOutputPath(job, new Path(args[1])); 46 47 //等待job提交完毕 48 boolean result = job.waitForCompletion(true); 49 50 System.exit(result ? 0 : 1); 51 } 52 }
Kafka is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.
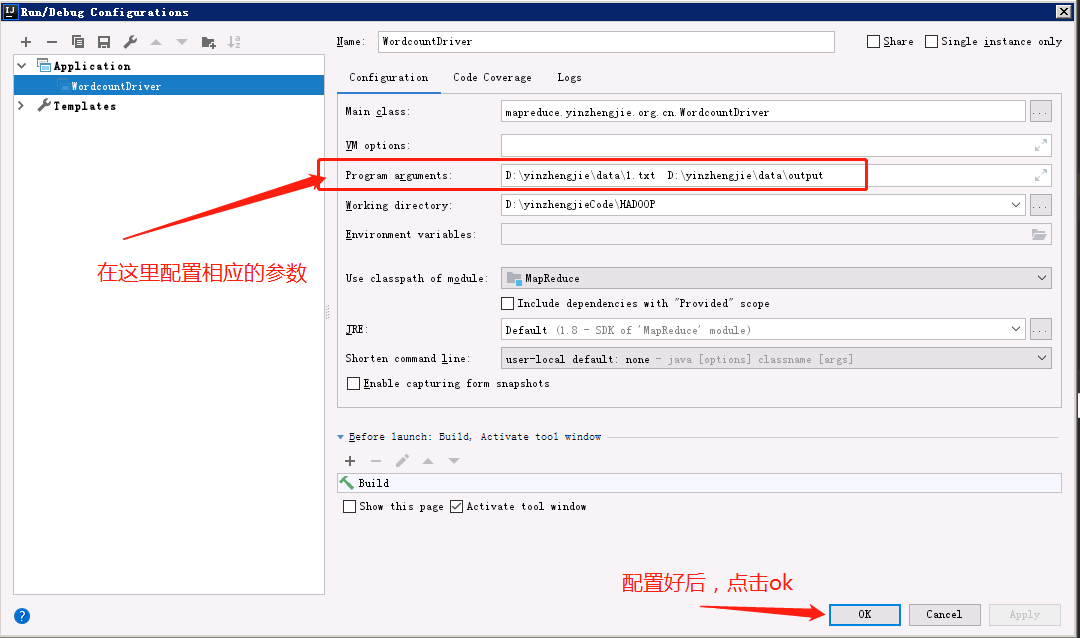
3>.配置相关参数
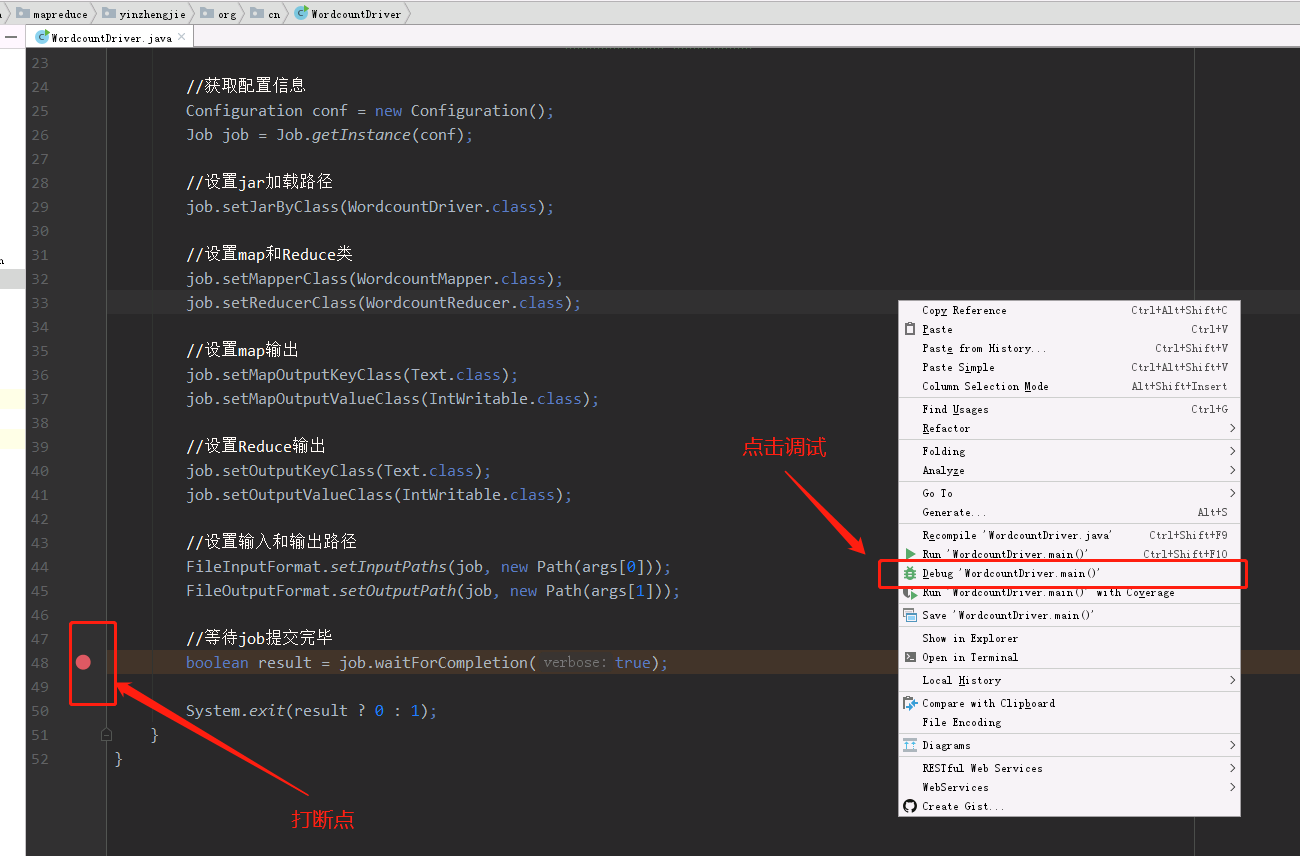
4>.打断点,点击debug进行调试
二.代码调试过程
1>.单步进入

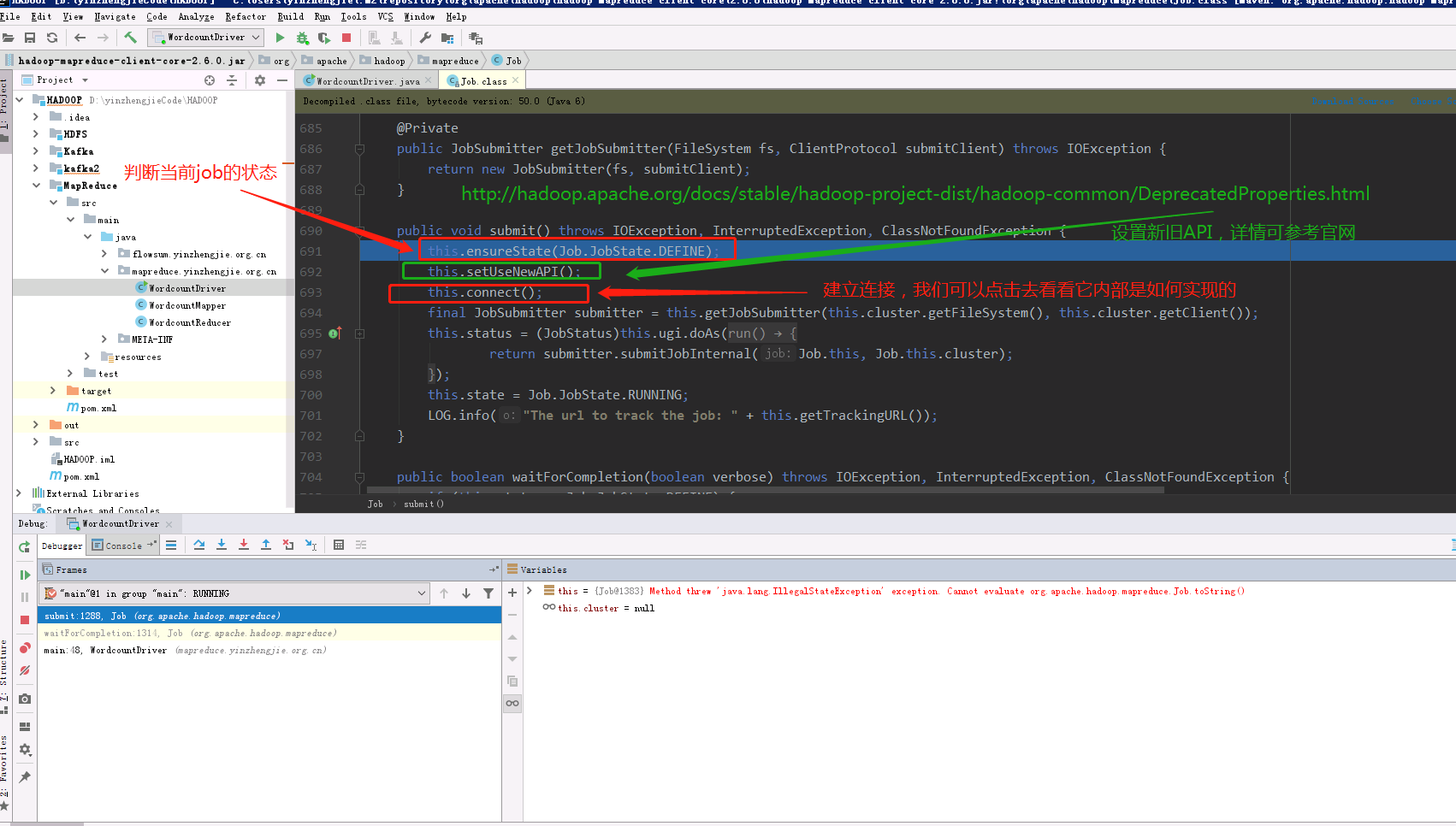
2>.进入submit()方法
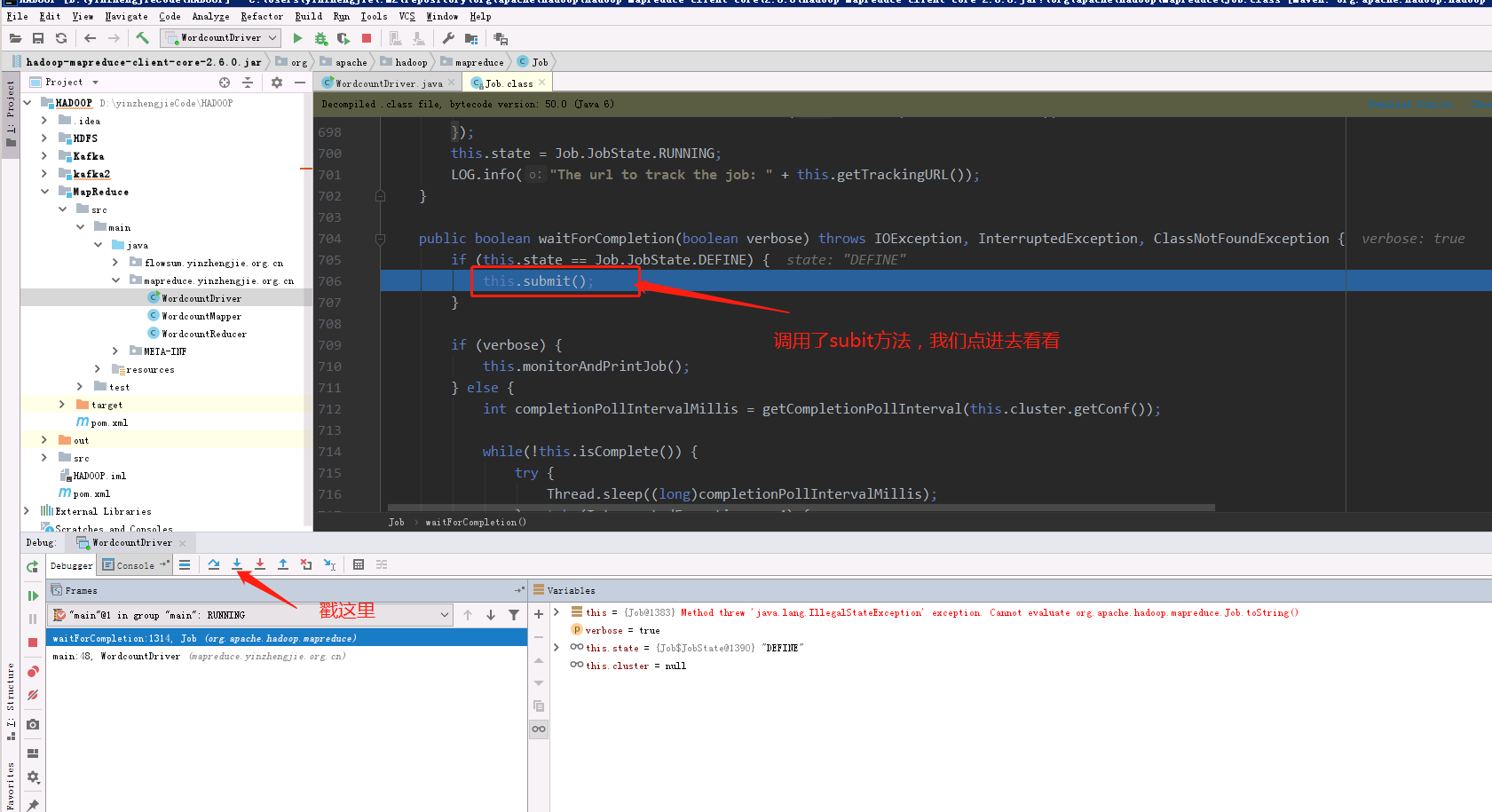
3>.进入connect()的方法
新旧的API对比,可查看官网:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/DeprecatedProperties.html
4>.
5>.
6>.
7>.
三.总结
1>.简介job提交源码分析
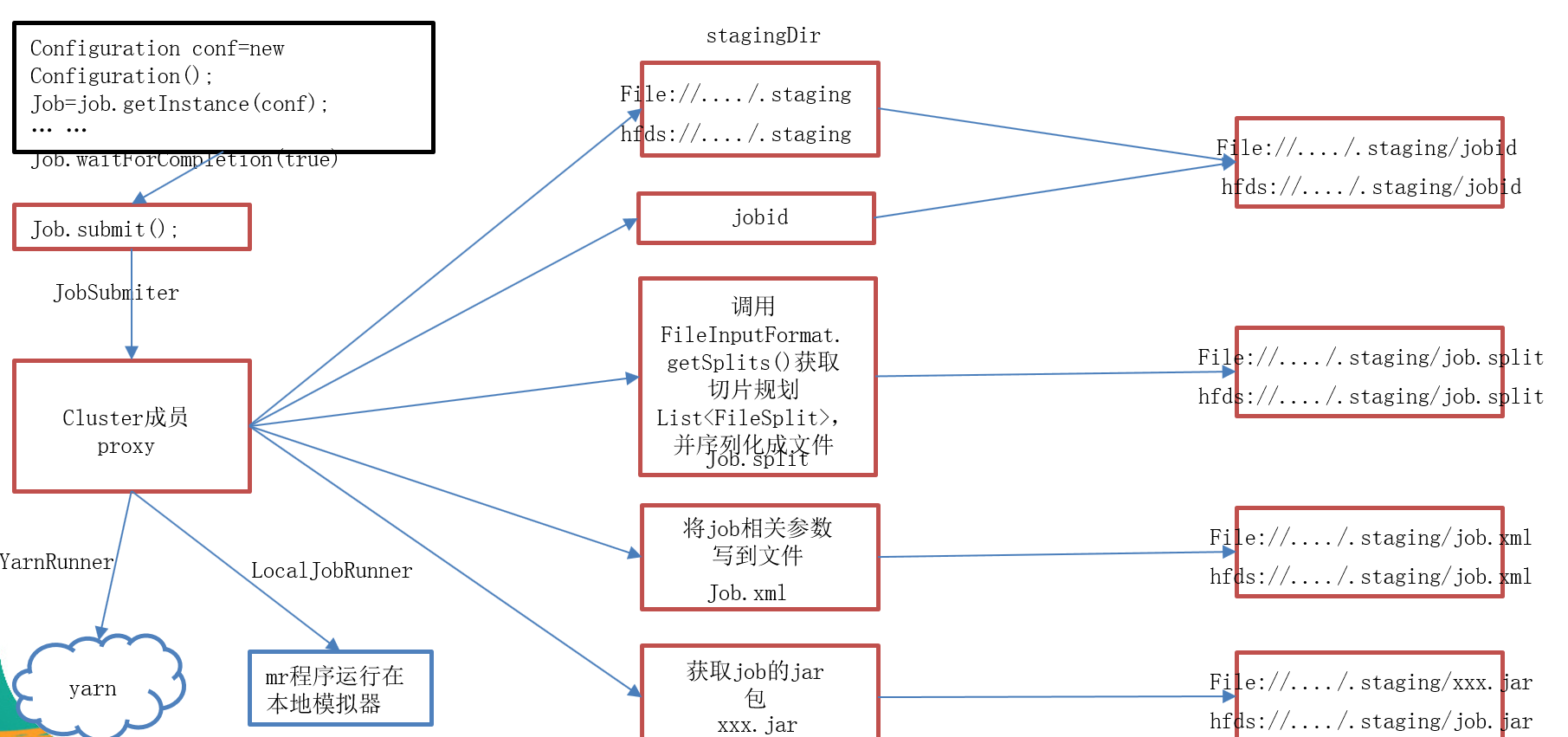
waitForCompletion() submit(); // 1建立连接 connect(); // 1)创建提交job的代理 new Cluster(getConfiguration()); // (1)判断是本地yarn还是远程 initialize(jobTrackAddr, conf); // 2 提交job submitter.submitJobInternal(Job.this, cluster) // 1)创建给集群提交数据的Stag路径 Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf); // 2)获取jobid ,并创建job路径 JobID jobId = submitClient.getNewJobID(); // 3)拷贝jar包到集群 copyAndConfigureFiles(job, submitJobDir); rUploader.uploadFiles(job, jobSubmitDir); // 4)计算切片,生成切片规划文件 writeSplits(job, submitJobDir); maps = writeNewSplits(job, jobSubmitDir); input.getSplits(job); // 5)向Stag路径写xml配置文件 writeConf(conf, submitJobFile); conf.writeXml(out); // 6)提交job,返回提交状态 status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
2>.网上找的一张流程图,画得挺命令,摘下来方便自己以后理解