今天是另外一个html/xml解析器的使用–BeautifulSoup
到这里我们已经接触过了三个可以解析网页文本的方式:re(正则), Ixml, 以及今天学的BeautifulSoup,它们三个的特点如下:
- re:速度最快(C写的), 使用难度最大
- Ixml:速度较快, 使用难度一般
- BeautifulSoup:速度三者相比较慢,但不影响使用,使用最为方便容易
基本使用
步骤:
- 1.导入模块:
from bs4 import BeautifulSoup - 2.创建soup对象,将字符串类型的网页文本传入:
soup=BeautifulSoup(<网页数据>) - 3.使用soup.find()/soup.findall()/soup.select()对数据进行匹配返回
- 4.对返回的数据进行展示/存储
四个对象
- Tag:就是标签整体
- NavigationSting:标签的文本内容
- comment:标签去除注释符号的文本内容
BeautifulSoup:整个内容本身
感觉有点抽象,标签就是标签呗,内容就是内容呗,为什么起这么几个不太好理解的名字?
# -*- coding:utf-8 -*-
import bs4
def tag():
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
# 创建一个soup对象
soup = bs4.BeautifulSoup(html, 'lxml')
# 提取标签对象
# <p ; <a; <body
print soup.p # 返回第一个p标签
print soup.body # 返回第一个body标签
print soup.a # 返回的第一个a 标签
print type(soup.p) # <class 'bs4.element.Tag'>
print type(soup.body) # <class 'bs4.element.Tag'>
print type(soup.a) # <class 'bs4.element.Tag'>
print soup.p.attrs
# 第一个p标签的所有属性,一个字典,属性名位key,属性值为value,
# 注意class属性的值为一个列表,因为class可能不只一个值
print soup.a['href'] # 获取到第一个a标签的'href' 属性的值
print soup.a.get('href') # 效果同上
soup.a['href'] = 'http://www.baidu.com'
print soup.a['href'] # 可以修改标签的属性值
del soup.a['href'] # 可以删除某个属性的值
print soup.a
# <a class="sister" id="link1"><!-- Elsie --></a>
print soup.p.string
# The Dormouse's story
print type(soup.p.string)
# <class 'bs4.element.NavigableString'>
# BeautifulSoup对象:标签本身
print soup.name
# [document]
print type(soup.name)
# <type 'unicode'>
# Comment对象:一种特殊的NavigationString对象,忽略注释符号
print soup.a.string
# Elsie
print type(soup.a.string)
# <class 'bs4.element.Comment'>
三个方法
find
- 返回条件匹配的第一个标签/文本等内容
用法如下:
from bs4 import BeautifulSoup
import re
# 有关find方法的使用
def find_method():
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html, 'lxml')
soup.prettify()
# find(),参数可以传递 一.标签名tag 二.属性名attr 三.标签内容 text
# 注意find只返回匹配出结果的第一个
# 一:匹配标签可以匹配:1.单个标签名 2.标签名列表 3.正则表达式pattern对象
# 1.1 单个标签名
p = soup.find('p')
print p
# 返回第一个p标签
print '-----' * 20
# 1.3 正则表达式pattern对象
# 匹配标签名以'h'开头的标签
startwith_h = soup.find(re.compile(r'^h'))
print startwith_h
# 返回html标签
print '-----'*20
# 二. 属性名attr
# 2.1 直接传递属性名
# 匹配 class_="title" 的标签
res = soup.find(class_="title")
print res
#
print '-----'*20
# 2.2 传递多个属性
# 匹配属性有class="title"和 class="story"的标签
res = soup.find(attrs={'class':"title", 'class':"story"})
print res
# 返回出第一个匹配到的class='story'的标签
print '-----' * 20
# 2.3 属性名正则表达
# 匹配 属性名为t开头的标签
res = soup.find(class_=re.compile(r'^t'))
print res
# [<p class="title" name="dromouse"><b>The Dormouse's story</b></p>]
print '-----' * 20
# 三.以标签里的test来匹配
# 3.1 匹配一个内容
# 匹配内容'The Dormouse's story'
res = soup.find(text="The Dormouse's story")
print res
# The Dormouse's story
# 3.2 匹配多个内容
print '-----' * 20
# 匹配人名:Elsie,Lacie,Tillie
res = soup.find(text=['Elsie', 'Lacie', 'Tillie'])
print res
# Lacie
if __name__ == '__main__':
find_method()
结果:
/Users/mengxing/.virtualenvs/py2_spider/bin/python2.7 /Users/mengxing/Desktop/code/spider/day03_beautiful_soup_4/05.find.py
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
----------------------------------------------------------------------------------------------------
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
----------------------------------------------------------------------------------------------------
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
----------------------------------------------------------------------------------------------------
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
----------------------------------------------------------------------------------------------------
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
----------------------------------------------------------------------------------------------------
The Dormouse's story
----------------------------------------------------------------------------------------------------
Lacie
findall()
- 返回条件匹配的所有的标签/文本等内容,以列表的形式存储
用法如下:
# findall(),参数可以传递 一.标签名tag 二.属性名attr 三.标签内容 text
# 一:匹配标签可以匹配:1.单个标签名 2.标签名列表 3.正则表达式pattern对象
# 1.1 单个标签名
# 匹配出所有的p标签
p = soup.find_all ('p')
print p
# 返回所有p标签的组成的列表
print '-----'*20
# 1.2 标签名列表
# 匹配出所有的p标签和a标签
P_a= soup.find_all(['p', 'a'])
print P_a
# 返回所有的p标签和a标签组成的列表
print '-----' * 20
# 1.3 正则表达式pattern对象
# 匹配所有标签名以'h'开头的标签
startwith_h = soup.find_all(re.compile(r'^h'))
print startwith_h
# 返回html标签(整个soup)和head标签组成的列表
print '-----'*20
# 二. 属性名attr
# 2.1 直接传递属性名
# 匹配 class_="title" 的标签 为什么加一个'_'才能获取到?
res = soup.find_all(class_="title")
print res
print '-----'*20
# 2.2 传递多个属性
# 匹配属性有class="title"和 class="story"的标签
res = soup.find_all(attrs={'class':"title", 'class':"story"})
print res
print '-----' * 20
# 2.3 属性名正则表达
# 匹配 属性名为t开头的标签
res = soup.find_all(class_=re.compile(r'^t'))
print res
# [<p class="title" name="dromouse"><b>The Dormouse's story</b></p>]
print '-----' * 20
# 三.以标签里的test来匹配
# 3.1 匹配一个内容
# 匹配内容'The Dormouse's story'
res = soup.find_all(text="The Dormouse's story")
print res
#[u"The Dormouse's story", u"The Dormouse's story"]
# 3.2 匹配多个内容
print '-----' * 20
# 匹配人名:Elsie,Lacie,Tillie
res = soup.find_all(text=['Elsie', 'Lacie', 'Tillie'])
print res
# [u'Lacie', u'Tillie'] ?
print '-----' * 20
# 3.3 正则匹配
# 匹配内容中含有'e'的所有单词
res = soup.find_all(text=re.compile(r'^ .*?e.*? $'))
print res
# [u' Elsie '] ?正则表达式有问题
结果如下
[<p class="title" name="dromouse"><b>The Dormouse's story</b></p>, <p class="story">Once upon a time there were three little sisters; and their names were\n <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,\n <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and\n <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;\n and they lived at the bottom of a well.</p>, <p class="story">...</p>]
----------------------------------------------------------------------------------------------------
[<p class="title" name="dromouse"><b>The Dormouse's story</b></p>, <p class="story">Once upon a time there were three little sisters; and their names were\n <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,\n <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and\n <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;\n and they lived at the bottom of a well.</p>, <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, <p class="story">...</p>]
----------------------------------------------------------------------------------------------------
[<html><head><title>The Dormouse's story</title></head>\n<body>\n<p class="title" name="dromouse"><b>The Dormouse's story</b></p>\n<p class="story">Once upon a time there were three little sisters; and their names were\n <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,\n <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and\n <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;\n and they lived at the bottom of a well.</p>\n<p class="story">...</p>\n</body></html>, <head><title>The Dormouse's story</title></head>]
----------------------------------------------------------------------------------------------------
[<p class="title" name="dromouse"><b>The Dormouse's story</b></p>]
----------------------------------------------------------------------------------------------------
[<p class="story">Once upon a time there were three little sisters; and their names were\n <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,\n <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and\n <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;\n and they lived at the bottom of a well.</p>, <p class="story">...</p>]
----------------------------------------------------------------------------------------------------
[<p class="title" name="dromouse"><b>The Dormouse's story</b></p>]
----------------------------------------------------------------------------------------------------
[u"The Dormouse's story", u"The Dormouse's story"]
----------------------------------------------------------------------------------------------------
[u'Lacie', u'Tillie']
----------------------------------------------------------------------------------------------------
[u' Elsie ']
select()
- 类选择器 方法
- 返回条件匹配的所有标签/文本内容,以列表的形式存储,跟findall()比,好处是可以直接使用属性选择器,而不用写全属性内容。
用法如下:
# css选择器的种类:类选择器,id选择器, 层级选择器, 属性选择器, 伪类选择器,标签选择器,组选择器
# css选择器查找的方法为:.select(), 返回类型为一个list,跟findall()比较像,好处是,在写选择器时,
# 和前端的CSS选择器语法一致,比较简单
# 1.类选择器:
# 选择类属性为'title'的标签
res = soup.select('.title')
print res
# [<p class="title" name="dromouse"><b>The Dormouse's story</b></p>]
# 2.id选择器:
# 选择id属性为link1的标签
res = soup.select('#link1')
print res
# [<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
# 3.通过标签名查找:
# 查找所有的a标签
res = soup.select('a')
print res
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
# 4.属性查找
# 查找属性有 href="http://example.com/lacie 的a标签
res = soup.select('a[href="http://example.com/lacie"]') # 注意要把a写在''里面
print res
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
# 5.组选择器
# 选择 href="http://example.com/lacie" ,class="sister"的标签
res = soup.select(".sister,href='http://example.com/lacie' ")
print res
# 6.层级选择器
# 选择head下面的title标签
res = soup.select('head title')
print res
# 获取内容,因为返回的是列表,所以可以直接使用下标获取列表内的部分标签,用get_text()
# 方法获取标签的值
# 获取class='title'下的b标签里的值
text = soup.select('.title b')[0].get_text()
print text
# The Dormouse's story
结果如下:
[<p class="title" name="dromouse"><b>The Dormouse's story</b></p>]
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
[<title>The Dormouse's story</title>]
The Dormouse's story
实例
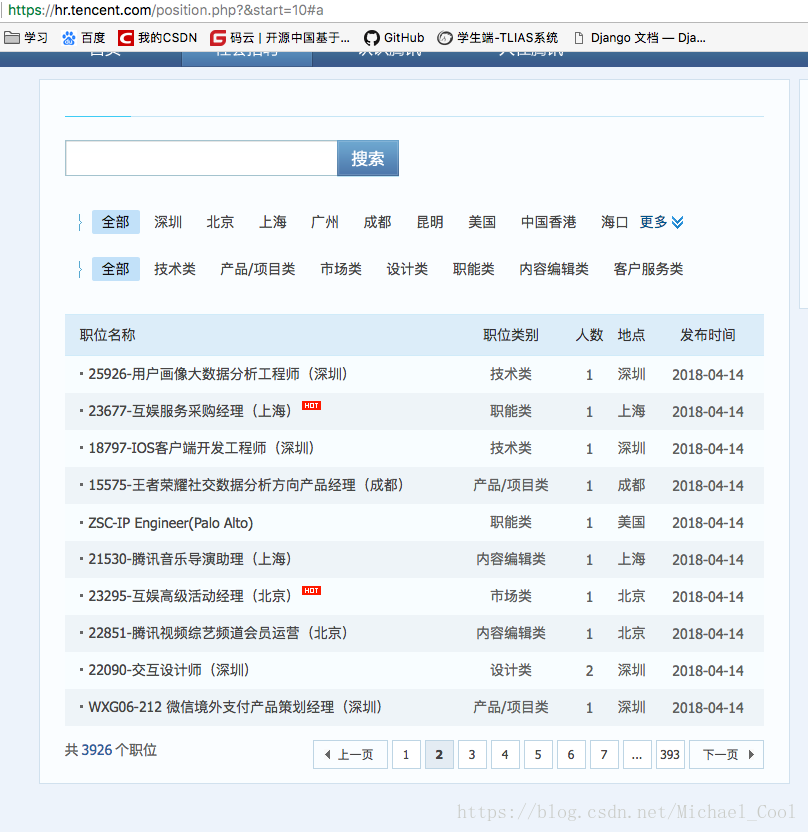
实例1:爬取腾讯招聘网站的所有招聘信息并处理存储
代码:
# -*- coding:utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
# 爬取 https://hr.tencent.com/ 上的所有招聘信息
import requests, re, json
from bs4 import BeautifulSoup
import logging
class SpiderTencentEmployPage(object):
def __init__(self):
self.base_url = 'https://hr.tencent.com/position.php?'
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"}
self.list_data=[]# 每一行数据为一个单位,放在字典里,所有的数据单位放在一个列表里,这样后期可以转json
# 请求数据
def send_request(self, params):
try:
response = requests.get(url=self.base_url, params=params, headers=self.headers)
data = response.content
return data
except Exception as err:
logging.error(err)
print err
# 获取总页数
def get_amount_pages(self):
params = {
'start': '0',
'lid': '2175'
}
data = self.send_request(params)
# get_amount_page_judge_num 传给filter_data,在函数内验证,如果为1,说明是为了获取最大页数
# 为0 说明为正常筛选数据
get_amount_page_judge_num = 1
amount_page_num = self.filter_data(data, get_amount_page_judge_num)
print type(amount_page_num) # <type 'unicode'>
return int(amount_page_num)
# 分析过滤数据
def filter_data(self, data, get_amount_page_judge_num):
soup = BeautifulSoup(data, 'lxml')
# 补全数据
soup.prettify()
# 获取最大页数
if get_amount_page_judge_num == 1:
# 筛选数据
amount_page_num = soup.select('.pagenav a')[9].get_text()
return amount_page_num # 类型为unicode,数字使用前需要int下
else:
# 1.一行元素的内容一个大标签,匹配出所有行元素的大标签,返回一个列表
datas = soup.select('.even, .odd')
# 2.每一行元素要以字典的形式存储,遍历所有大标签的列表
for data in datas:
# 3. 大标签,提取出每一个小标签的text值,存到局部字典里
dict = {}
dict['name']=data.select('td a')[0].get_text()
dict['type']=data.select('td')[1].get_text()
dict['count']=data.select('td')[2].get_text()
dict['addr']=data.select('td')[3].get_text()
dict['date']=data.select('td')[4].get_text()
# 将完整的一行数据(字典)存放在总的数据列表里
self.list_data.append(dict)
# 不用返回,将list_data 直接保存数据即可
# 将数据保存到本地
def save_data(self):
# 将list 数据转换为json数据后存储
json_data = json.dumps(self.list_data) # dumps是转换为json格式数据(字符串)
# 存储到本地
with open('08.tencent_employ_data_02.json', 'w') as f:
f.write(json_data)
# 主逻辑
def main(self):
# 先爬取第一页,获取总页数
amount_page_num = self.get_amount_pages()
# 循环所有页数,爬取每一页的数据
page_num = 1
while page_num <= amount_page_num:
params = {
'start':(page_num-1)*10,# 注意不要使用占位符,直接填入数字!
'lid':'2175'
}
# 请求数据
data = self.send_request(params)
# 解析处理数据
get_amount_page_judge_num = 0
self.filter_data(data, get_amount_page_judge_num)
print '已经爬好第%s页'%page_num
page_num += 1
# 保存数据到本地
self.save_data()
if __name__ == '__main__':
spider_tencent = SpiderTencentEmployPage()
spider_tencent.main()
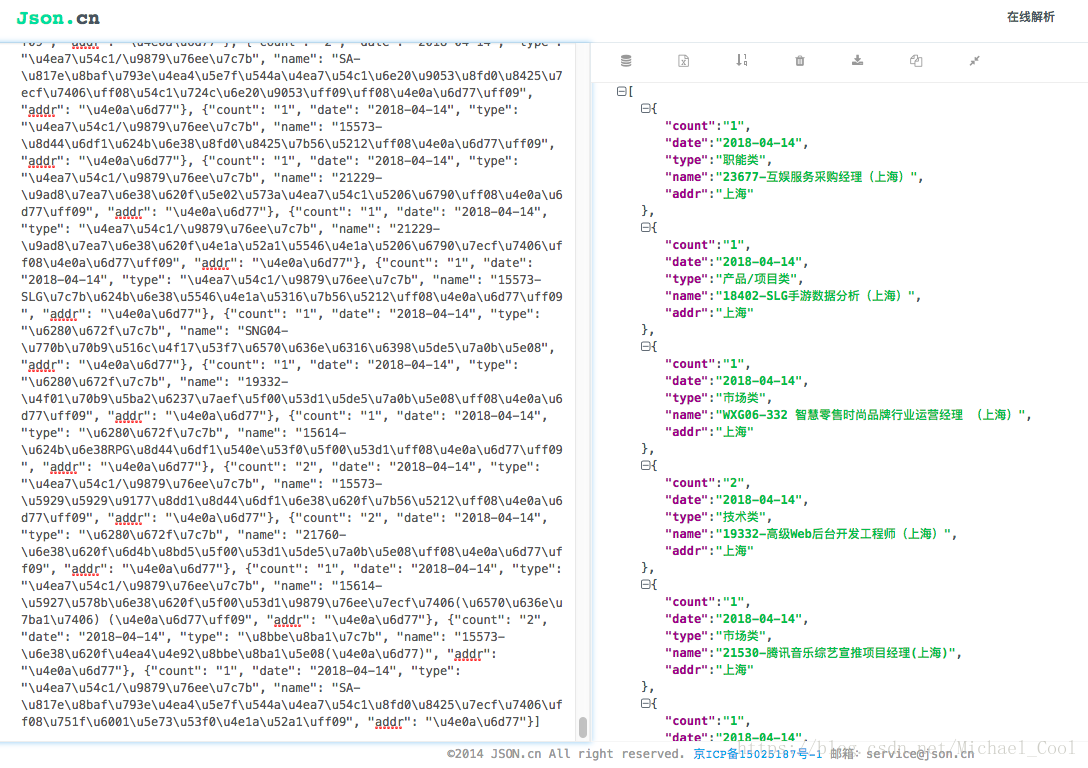
结果
json数据需要在一些解析器中才能看清,工作中,为了给相关人员展示结果,应该转换成更直接的界面。此时,可是将json数据转换为csv格式的文件
csv 是一种文件格式,是能够在文本中展示表结构的文件类型。
使用步骤及上一个案例的转换代码
# -*- coding:utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
import csv, json
# 步骤:
# 1. 导入csv模块, json模块: import csv,json
# 2. 打开源文件(json文件),csv文件(没有就新建)
# 3. 创建csv读写器:csv.writer(<文件名>)
# 4. 将需要转换的数据先转换成list格式:json.load(<源文件对象>) # 打开的json文件这种状态,是一个对象,对象转换为list格式就是用json.load()
# 5. 使用csv读写器将转换格式后的list格式的文件写入csv文件里:.writerow(<单层列表>),表示写入单层列表的每一个值,在一行
# .writerows(<两层列表>),表示写入两层列表中的每一个元素,一个元素(一个列表)占一行,自动换行
# 6. 关闭文件:<文件名>.close()
def json_to_csv():
# 1.json文件 读取
json_file = open('08.tencent_employ_data_02.json', 'r')
print type(json_file) # <type 'file'>
# 2.csv文件 写入
csv_file= open('08.tencent_employ_data_02.csv', 'w')
print type(csv_file) # <type 'file'>
# 3.将json_file状态对象的jsons数据转换为原list类型
data_list = json.load(json_file) # json.load()是讲对象转换为原数据类型的方法
print type(data_list) # <type 'list'>
# 4.取出表头
sheets = data_list[0].keys()
print sheets # [u'count', u'date', u'type', u'name', u'addr']
# 5. 取出内容
content_list = []
for data_dict in data_list:
content_list.append(data_dict.values())
print content_list # 大列表套每一条数据的小列表
# 6. 创建csv读写器
csv_writer = csv.writer(csv_file)
print csv_writer # <_csv.writer object at 0x10cf2f1b0>
print type(csv_writer) # <type '_csv.writer'>
# 7.写入表头数据
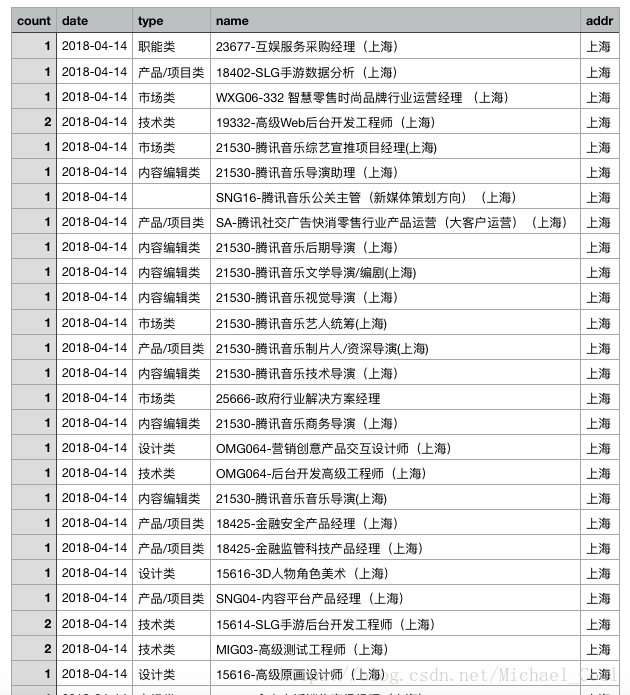
csv_writer.writerow(sheets)
# 8.写入内容
csv_writer.writerows(content_list)
# 一个列表一行数据,自动换行,自动转换成表格
# 9.关闭csv文件
csv_file.close()
# 10.关闭json文件
json_file.close()
if __name__ == '__main__':
json_to_csv()
转换后结果:
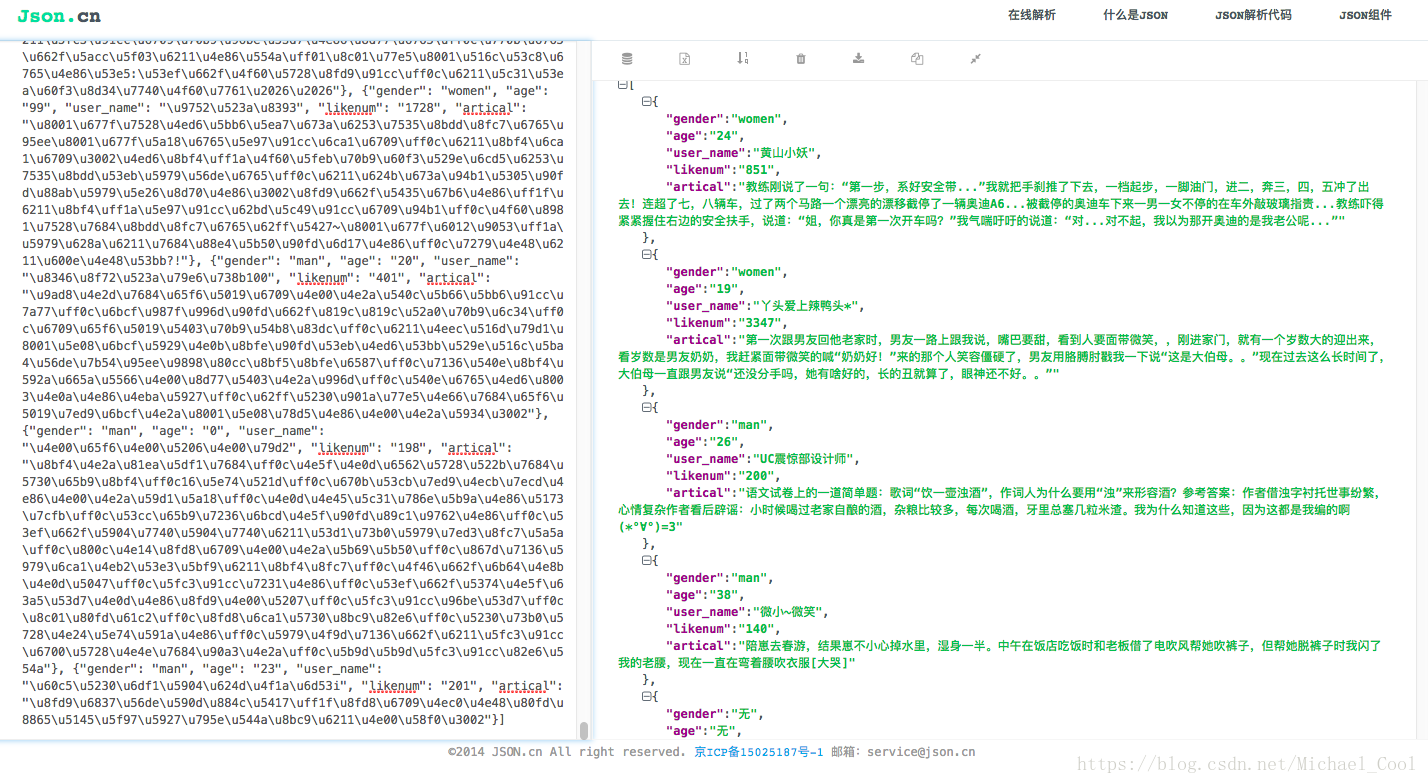
实例2:抓取糗事百科的部分需求信息
代码:
# -*- coding:utf-8 -*-
# 抓取糗事百科网页的每一个单元的:用户名,性别,年龄,正文,点赞数,抓取前10页
import requests, bs4, json, logging
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
class SpiderQiushibaike(object):
def __init__(self):
self.base_url = 'https://www.qiushibaike.com/8hr/page/'
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"}
self.data_list = [] # 用来存放获取的所有数据单元
# 发送请求
def send_request(self, url):
try:
response = requests.get(url=url, headers=self.headers)
except Exception as err:
logging.error(err)
print err
return response.content
# 过滤数据
def filter_data(self, data):
# 创建soup对象
soup = bs4.BeautifulSoup(data, 'lxml')
# 完整化数据
soup.prettify()
# 取出所有的单元数据
div_list = soup.select('#content-left .article')
print '单元数据块数量:%d' % len(div_list)
# 取出每一个单元的需求数据
for div in div_list:
temp_dict = {} # 临时存储一个单元的所有所需数据
temp_dict['user_name'] = div.select('.author img')[0]['alt']
author_div = div.select('.author div')
if author_div:
temp_dict['age'] = author_div[0].string
temp_dict['gender'] = author_div[0]['class'][1].replace('Icon', '')
else:
temp_dict['age'] = '无'
temp_dict['gender'] = '无'
temp_dict['artical'] = div.select('.content span')[0].get_text().strip()
temp_dict['likenum'] = div.select('.stats-vote i')[0].get_text().strip()
self.data_list.append(temp_dict)
# 保存数据到本地
def save_data(self):
# 将列表转换成json数据
data_json = json.dumps(self.data_list)
with open('10_qiushibaike_data.json', 'w') as f:
f.write(data_json)
# 主逻辑
def main(self):
# 参数准备
for page in range(1, 11):
url = self.base_url + '%d/' % page
# 发送请求
data = self.send_request(url)
# 过滤数据
self.filter_data(data)
# 保存数据到本地
self.save_data()
if __name__ == '__main__':
spider_qiushibaike = SpiderQiushibaike()
spider_qiushibaike.main()
结果