我们已经看到了,where条件可以筛选我们的记录,符合要求的记录,接下来还可以加上另外一个group by它呢是对我们的记录做一个分组。
我们可以看到,我们可以按照字段分组也可以按照字段的位置进行分组。
GROUP BY分组:它是把记录值相同的放到一个组里,最终的查询出的结果只会显示组中的一条记录。
#测试分组
#按照性别分组
SELECT id,username,age,sex FROM user1
GROUP BY sex;#按照地址分组
#会把值相同的放到一个组里
SELECT username,age,sex,addr FROM user1
GROUP BY addr;想看到分组中详细信息,group可以套着一个函数使用:配合group_concat()查看组中某个字段的详细信息。
#测试分组
#按照性别分组,查询组中的用户名有哪些
SELECT GROUP_CONCAT(username),age,sex,addr FROM user1
GROUP BY sex;
#因为要查看username的详细信息,所以要把username放到group_concat()函数中显示分组配合聚合函数使用。
常用的聚合函数:
count():是统计数据表中记录总数
SUM():它是求和的
MAX():求最大值
MIN():求最小值
AVG():求平均值
扫描二维码关注公众号,回复:
4186980 查看本文章

一半呢都是配合上我们的聚合函数一起使用的。
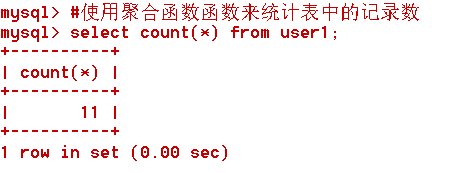
#测试聚合函数统计数据表中的记录数
#并对它起一个别名
SELECT COUNT(*)AS total_users FROM user1;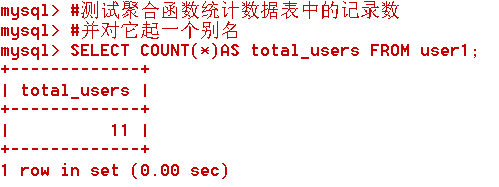
之后我们就可以取出这个字段对应的值了;
#测试聚合函数统计数据表中的记录数
SELECT COUNT(id) FROM user1;
但是注意id和*是有区别的,请看下面
#测试聚合函数统计数据表中的记录数
SELECT COUNT(userDesc) FROM user1;

如果直接写字段的话,它在统计的时候如果这个字段为空的话它不记录进来。这就是它和*的区别。
字段中的值为NULL时,不统计进来。写*的话会统计进来。
#按照sex分组,得到用户名详情,并且分别显示组中总人数
SELECT sex,GROUP_CONCAT(username),COUNT(*)AS totalusers FROM user1
GROUP BY sex;
使用到了我们的聚合函数
#按照addr分组,得到用户名的详情,总人数,得到组中年龄的总和,年龄的最大值、最小值、平均值和
SELECT addr,GROUP_CONCAT(username) AS userDetail,
COUNT(*)AS totalUsers,
SUM(age)AS sum_age,
MAX(age)AS max_age,
MIN(age)AS min_age,
AVG(age)AS avg_age
FROM user1
GROUP BY addr;
#按照sex分组,统计组中总人数、用户名详情、得到薪水综合、薪水最大值、最小值、平均值
SELECT sex,
#当然了,你写到一行也是可以的,但是不建议你写到一行,看起来不方便
GROUP_CONCAT(username)AS userDetail,
COUNT(*)AS totalUsers,
SUM(salary)AS sum_salary,
MAX(salary)AS max_salary,
MIN(salary)AS min_salary,
AVG(salary)AS avg_salary
FROM user1
GROUP BY sex;
配合with rollup关键字使用:它会在记录末尾添加一行记录,是上面所有记录的总和。
SELECT GROUP_CONCAT(username)AS userDetail,
COUNT(*)AS totalUsers
FROM user1
GROUP BY sex
WITH ROLLUP;
前面是按照字段名称进行分组,也可以按照字段位置进行分组。
#按字段位置进行分组
GROUP_CONCAT(username)AS userDetail,
COUNT(*)AS totalUsers,
SUM(salary)AS sum_salary,
MAX(salary)AS max_salary,
MIN(salary)AS min_salary,
AVG(salary)AS avg_salary
FROM user1
GROUP BY 1;
这就是筛选后得到的结果集。
where相当于对结果的第一次筛选,然后再用分组进行二次处理。
#查询age>=30的用户并且按照sex分组
SELECT sex,GROUP_CONCAT(username)AS userDetail,
COUNT(*)AS totalUsers
FROM user1
WHERE age>=30
GROUP BY sex;
相当于对这个结果再进行分组。
having字句对分组结果进行二次筛选
#按照addr分组,统计总人数
SELECT addr,
GROUP_CONCAT(username)AS userDetail,
COUNT(*) AS totalUsers
FROM user1
GROUP BY addr
HAVING COUNT(*)>=3;
#通过having字句对于分组结果进行二次筛选,要求组中总人数>=3
#按照addr分组,统计总人数
SELECT addr,
GROUP_CONCAT(username)AS userDetail,
COUNT(*) AS totalUsers
FROM user1
GROUP BY addr
HAVING totalUsers>=3;
#这也体现了别名的好处

#按照addr分组
SELECT addr,
GROUP_CONCAT(username) AS usersDetail,
COUNT(*)AS totalUsers,
SUM(salary)AS sum_salary,
MAX(salary)AS max_salary,
MIN(salary)AS min_salary,
AVG(salary)AS avg_salary
FROM user1
GROUP BY addr;
加上二次删选的条件,要求平均薪水大于等于40000
#按照addr分组
SELECT addr,
GROUP_CONCAT(username) AS usersDetail,
COUNT(*)AS totalUsers,
SUM(salary)AS sum_salary,
MAX(salary)AS max_salary,
MIN(salary)AS min_salary,
AVG(salary)AS avg_salary
FROM user1
GROUP BY addr
HAVING avg_salary>=40000;
#这就是我们having字句的使用
