半联结定义
当两张表进行联结的时候,如果表1中的数据行是否出现在结果集中需要根据表2中出现或不出现至少一个相匹配的数据行来判断,这种情况就会发生半联结;而反联结便是半联结的补集,它们会作为数据库中常见的联结方法如NESTED LOOPS,MERGE SORT JOIN,HASH JOIN的选项出现。
实际上半联结和反联结本身也可以被认同是两种联结方法;在CBO优化模式下,优化器能够根据实际情况灵活的转换执行语句从而实现半联结和反联结方法,毕竟没有什么SQL语法可以显式的调用半联结和反联结,它们只是SQL语句满足某些条件时优化器可以选择的选项而已,不过仍然有必要深入这两种选项在特定情况下带来的性能优势。
一、半联结必要条件
半联结是一种可以极大提升某些查询性能的优化方法。基于成本优化器决定使用半联结的必要条件
1、语句必须使用关键字in(=any)或exists
2、语句必须在in 或exists子句中有查询
3、如果语句使用exists语法。则必须使用相关子查询
4、in和exists子句不能包含在or分支中
二、半联结执行计划
实际上半联结本身并不是一种联结方法,而更像其他联结方法的一个选项。oracle 最常用的三种联结方法嵌套循环、合并联结、散列联结都可以应用到半联结。同时还要记住允许处理过程在子查询中找到第一条匹配记录时停止是一种优化方法。来看如下伪码:
Q1外层查询,Q2内层查询
open Q1
while Q1 still has records
fetch record from Q1
result=false
open Q2
while Q2 still has records
fetch record from Q2
if(Q1.record matchs Q2.record) then --半联结优化 不用遍历所有的内层记录
result=true
exit loop
end if
end loop
close Q2
if(result=true) reture Q1 record
end loop
close Q1
半联结提供子查询中找到第一条匹配记录时跳出内层循环(不用遍历所有的内层记录)的if语句。显然,对于大数据集,与对外层查询中的每一行数据都必须循环读取内层查询返回的所有记录的普通嵌套循环联结相比,这个技术可以节省大量时间。
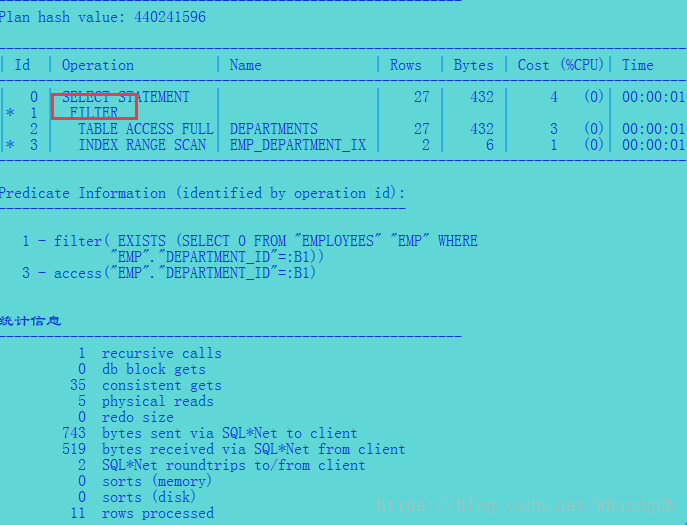
1、in 执行计划
select dept.department_id
from departments dept
where dept.department_id in (select emp.department_id from employees emp);
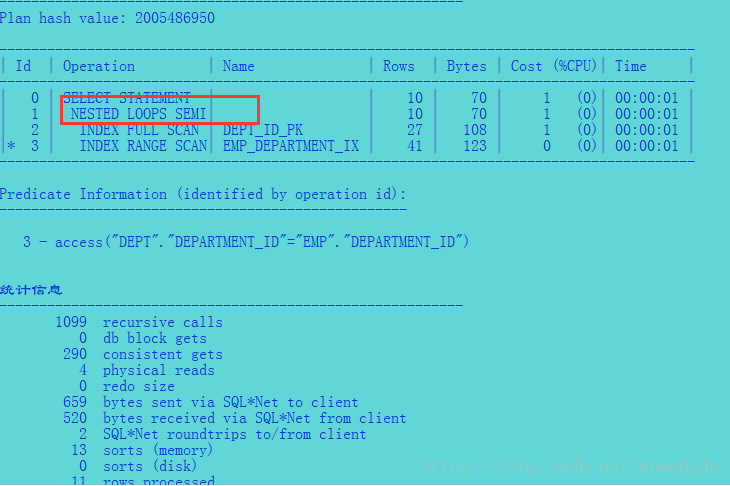
2、exists执行计划
select dept.department_id
from departments dept
where exists(select 1 from employees emp where emp.department_id=dept.department_id);
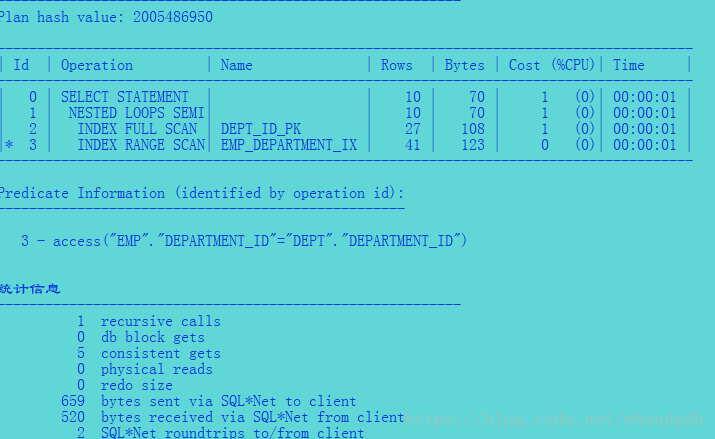
可以看到in和exists 的执行计划是一致的。统计信息也是一致的。在8i以后in和exists处理的方法就是一致的了。
3、自动追踪统计信息
可以通过自动追踪的统计信息的追踪文件来证明in exists 都转化成了相同的语句开启自动追踪命令:
alter session set events '10053 trace name context forever,level 1';
扩展 关闭跟踪事件
ALTER SESSION SET EVENTS '10053 trace name context off';
查看in exists 执行计划后
查找trace文件路径
SELECT value FROM v$diag_info WHERE name='Default Trace File';

搜索Cost-Based Subquery Unnesting
找到如下段落
截图中标红框标注可以证明in其实就是any。他们作用是一致的。 这里意思把any进行了子查询解嵌套继续
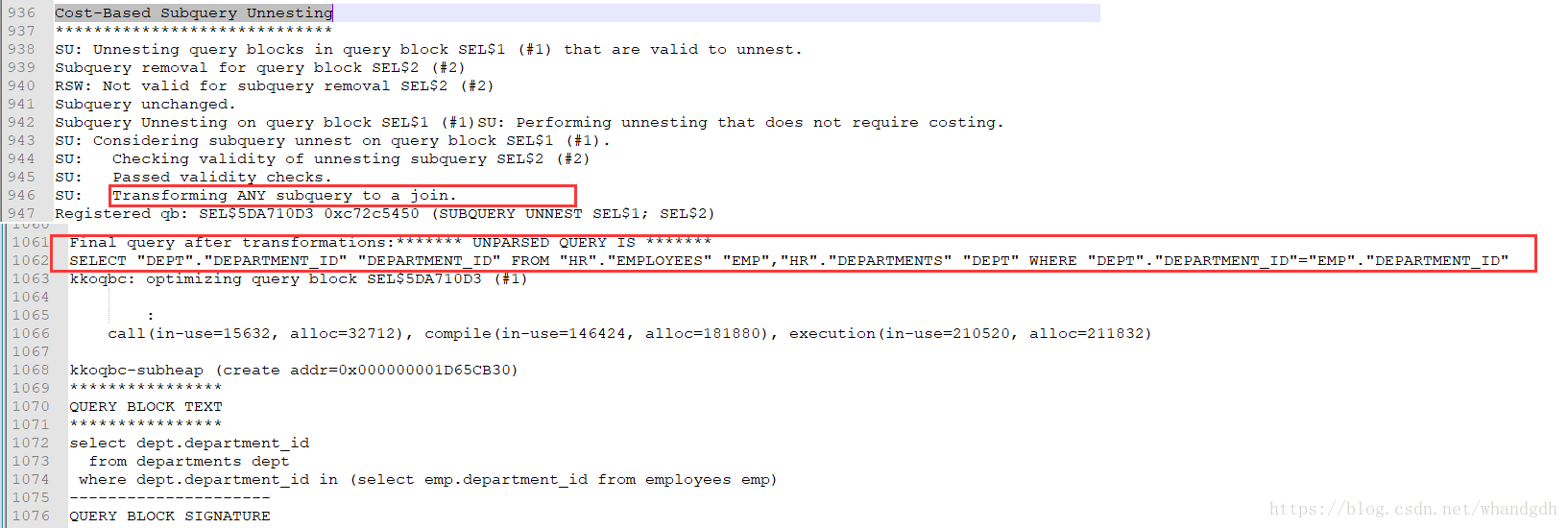
再来看exists的追踪文件
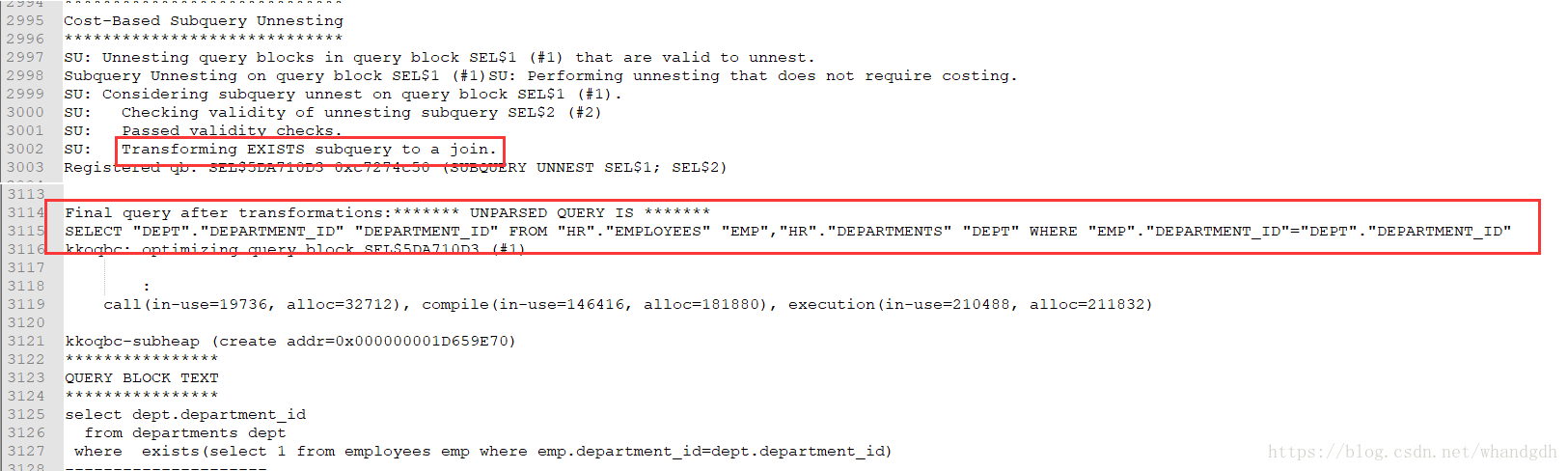
可以看到 in 和exists最终都进行了子查询解嵌套,转换为相同语句:
SELECT "DEPT"."DEPARTMENT_ID" "DEPARTMENT_ID" FROM "HR"."EMPLOYEES" "EMP","HR"."DEPARTMENTS" "DEPT" WHERE "EMP"."DEPARTMENT_ID"="DEPT"."DEPARTMENT_ID"
这与以前学习的内容子查询解嵌套结论是一致的。
三、控制半联结执行计划
1、提示控制半联结执行计划
从11gR2起就可以使用如下提示:
semijoin–半联结
no_semijoin–不使用半联结 (优化器选择使用哪种类型)
nl_sj --循环嵌套半联结(10g起弃用)
hash_sj --散列半联结 (10g起弃用)
merge_sg --合并半联结(10g起弃用)
–使用 no_semijoin 的exists语句
select dept.department_id
from departments dept
where exists(select /*+no_semijoin*/ 1 from employees emp where emp.department_id=dept.department_id);
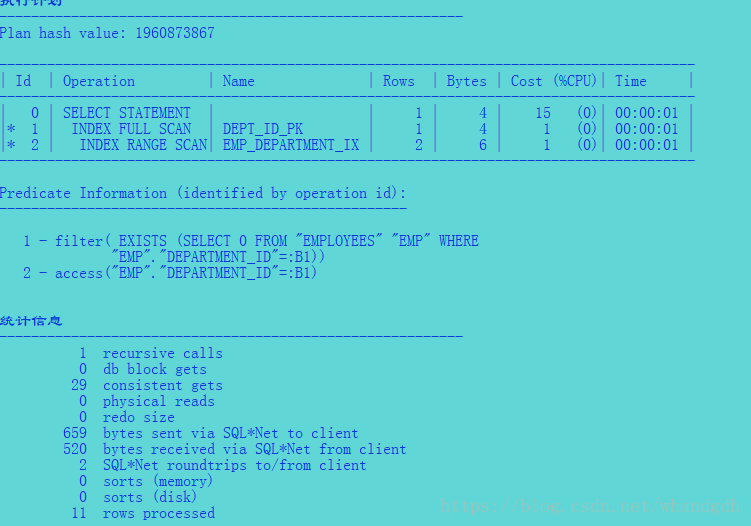
可以看到no_semijoin 提示关闭了优化器使用半联结的能力。查询使用了filter 运算来将两个行数据源结合起来。
注意解释执行计划的谓语部分是用filter运算执行exitsts子句。解释执行计划是独立于优化器的单独的代码路径,
它会与实际执行计划不同。
来看实际执行计划:
SELECT t.SQL_TEXT, t.SQL_ID, t.CHILD_NUMBER
FROM v$sql t
WHERE t.SQL_TEXT LIKE '%gather_plan_statistics%';

SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('5cupcamb9ts5d',0,'ALLSTATS LAST'));
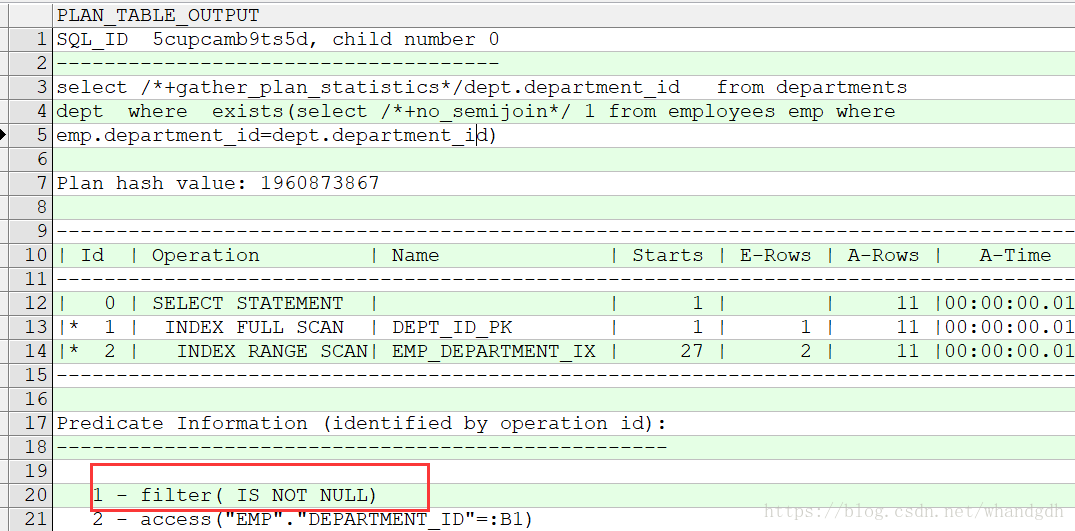
可以看到实际计划中的谓语部分比解释计划要少得多
2、使用always_semi_join参数控制半联结
隐藏参数对优化器选择半联结也可以进行控制。_always_semi_join 最开始是一个正常的参数,在9i开始变成隐藏参数。
_always_semi_join有效值
SELECT name_kspvld_values NAME, value_kspvld_values VALUE
FROM x$kspvld_values v
WHERE name_kspvld_values = '_always_semi_join';
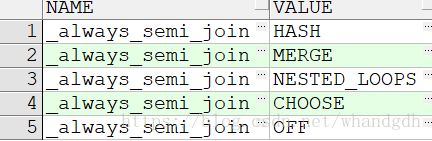
这个参数的名字容易引起误解,因为它并不是强制进行半联结。默认值为choose,允许优化器,对所有的半联结方法进行评估并选出它认为最高效的方法。off 则是禁用半联结。将优化器参数设置为merge。
alter session set "always_semi_join"= MERGE ;
再来看执行计划
select dept.department_name
from departments dept
where dept.department_id in (select emp.department_id from employees emp);

四、 半联结限制条件
对于优化器选择使用半联结文档中,只说明了一个主要限制条件(11gR2中)优化器不会为任何使用包含在or分支
中的子查询选择半联结。在之前的oracle版本中,包含distinct关键字时也会禁用半联结,但现在也没有这个限制了。
先设置_always_semi_join 参数为hash半联结
alter session set "_always_semi_join"=hash;
再来查看使用or子句时的执行计划
select dept.department_name
from departments dept
where 1=2 or dept.department_id in (select emp.department_id from employees emp);
很明显计划中的禁用了半联结,采用了filter算法。