基本概念
- Spring Data JPA是Spring公司开发的Java Persistence API 相对于 sun公司开发的JPA
- Spring Data JPA 整合了Hibernate,换句话说,Spring Data JPA 的默认实现是用的Hibernate
一个疑问:为什么JPA没有实现类?
在项目中观察到前辈们自定义的repository层接口没有实现类,查阅源码和资料得知,这是因为 我们自定义的接口继承了JpaRepository接口,而此接口有一个自带的实现类SimpleJpaRepository,它实现了部分常用的CRUD持久化方法。
我们用自定义接口对象调用JpaRepository接口中的方法时,在自定义接口中若没有找到重写的方法,便会去调用父类的方法,而父类只有一个自带的实现类SimpleJpaRepository,便会去调用此类的实现。这类型的方法常见的有save、saveAll等。
但是同时我又发现,有一些查询方法单纯靠方法名查询,比如findByNameAndPassword(),第一次见到时感觉自己要失业了,居然只看方法名就知道要怎么查询…于是深入探究总结了一下。
Spring Data JPA的查询方式
- SimpleJpaRepository实现的自带方法 如save和saveAll等
- 在继承了JpaRepository自定义接口中按照下图语法编写的方法
- 使用@Query在自定义的接口上编写所需要的SQL语句
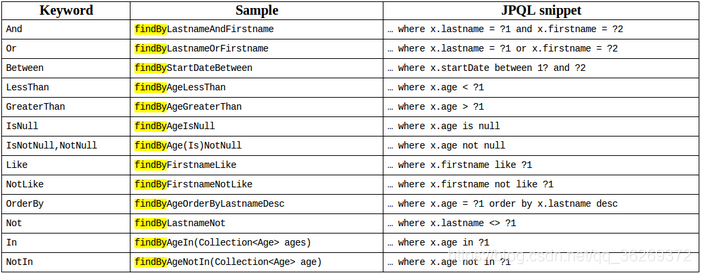
三种查询方式的实现原理
- 第一种如上所述,是由SimpleJpaRepository实现的。那么SimpleJpaRepository是怎么实现的呢?拿save()举例,找一下源代码就可以发现,在运用模板类的基础上,调用了EntityManager类的perisist()方法,如图所示。
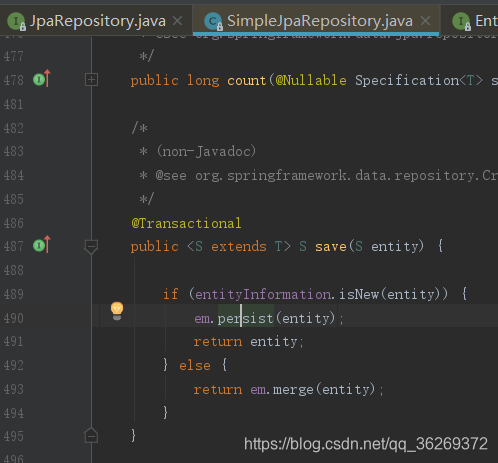
- 而EntityManager是在javax.persistence包中的内容,应该是原生JPA的内容
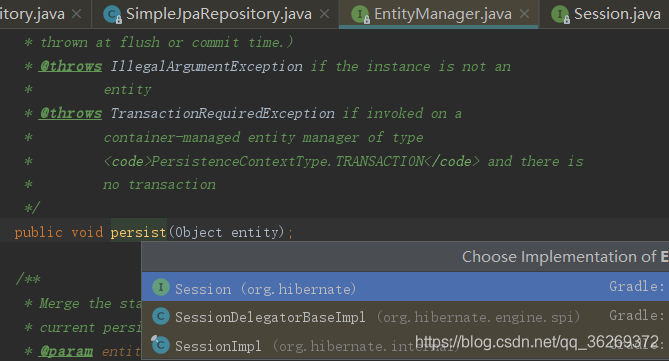
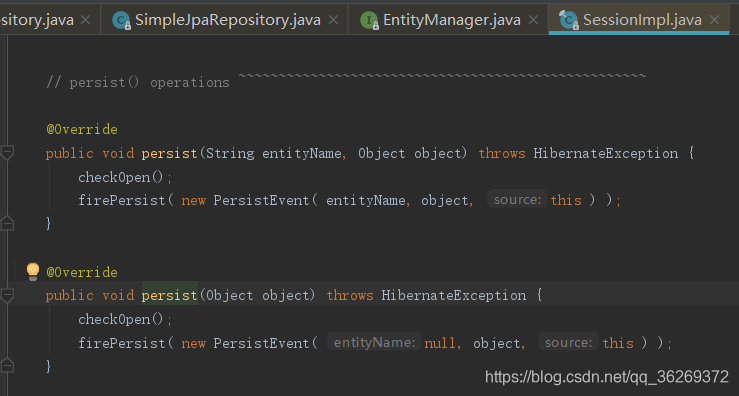
- 再跟踪一下persist(),可以发现persist()的实现是由hibernate中Session接口定义的
- 如图为其实现,看来是调用了hibernate的内容,hibernate具体内容我还不是很熟练,留待将来回顾。
-
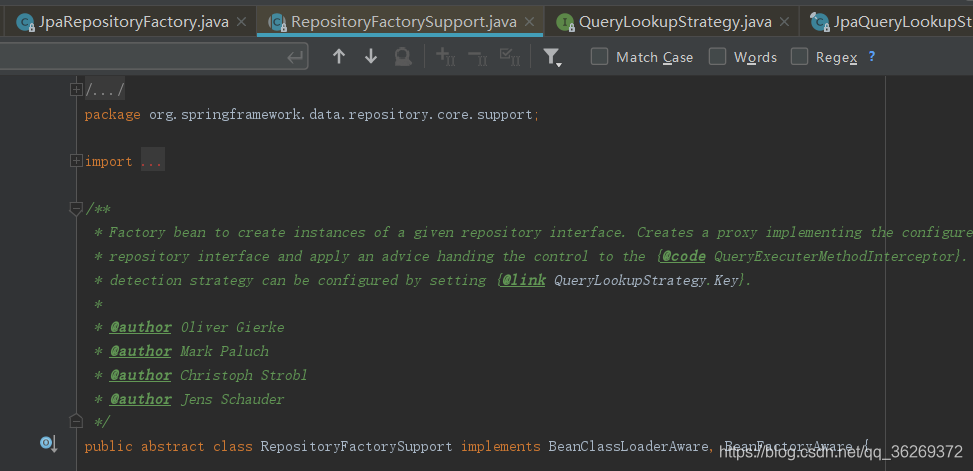
第二种方法是最让我摸不到头脑的,没有实现类,单靠方法名就可以实现查询。经过源码的阅读和资料的查阅,我发现它的实现是通过拦截器实现的。在真正的方法体调用之前,使用拦截器获取当前方法,并解析其方法名,实现根据方法名执行查询。在spring-data-commons-xxxx-RELEASE-sources.jar中,springframework–>data–>repository–>core–>support包里的RepositoryFactorySupport类,如图所示。
-
重点关注注释中:在创建接口时,此类对Repository接口创建实现了配置的代理,然后将控制权交给QueryExecuterMethodInterceptor,让拦截器根据查询策略QueryLookupStrategy.Key解析其内部是否有需要配置的查询方法。
-
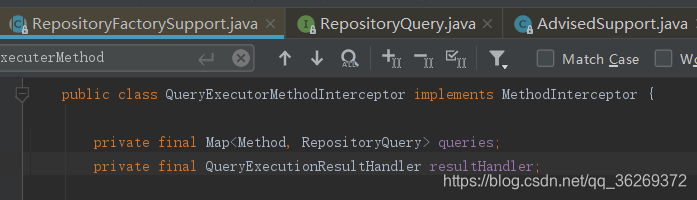
QueryExecuterMethodInterceptor就是上文提到的拦截器,是实现了MethodInterceptor接口的RepositoryFactorySupport的一个内部类,如图所示,其中的queries属性将拦截的自定义方法Method类和查询RepositoryQuery利用Map关联起来。
-
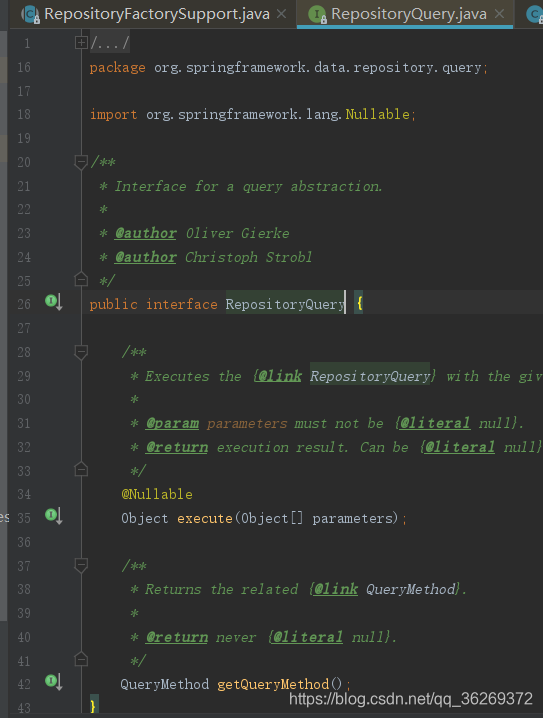
接下来到了拨云见日的时刻了,我们跟踪RepositoryQuery,发现其是一个“爷爷”级别的接口,类似Repository接口,其中只有两个方法,如图所示,execute()和getQueryMethod()。
-
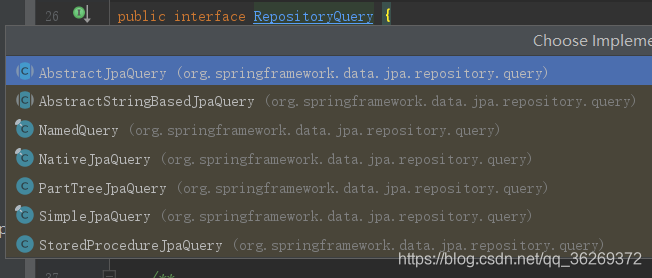
只有这么两个方法是一定完不成各种具体的复杂工作的,它的实现类必定各种各样。经过资料的查阅和来回来去一顿乱翻,我找到了它的实现类中的PartTreeJpaQuery。
-
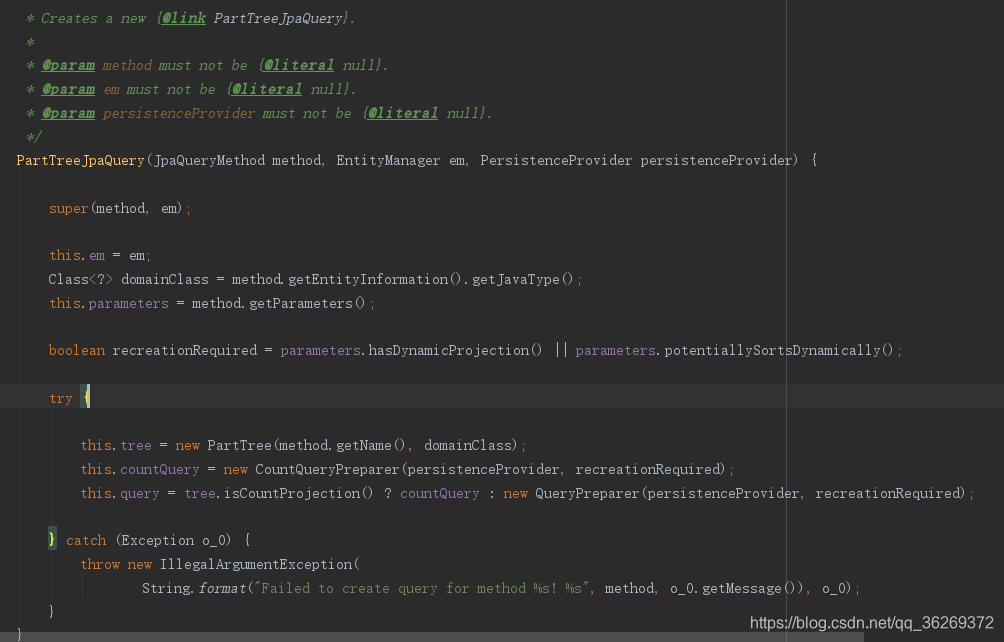
在PartTreeJpaQuery里,有一条属性叫做tree,类型是PartTree,如图所示。PartTreeJpaQuery的构造函数中,调用了PartTree的构造函数,传入了方法名称,在PartTree的构造函数里,完成了对方法名称的解析。
-
上图是PartTreeJpaQuery的构造函数,重点关注try里的第一行。
-
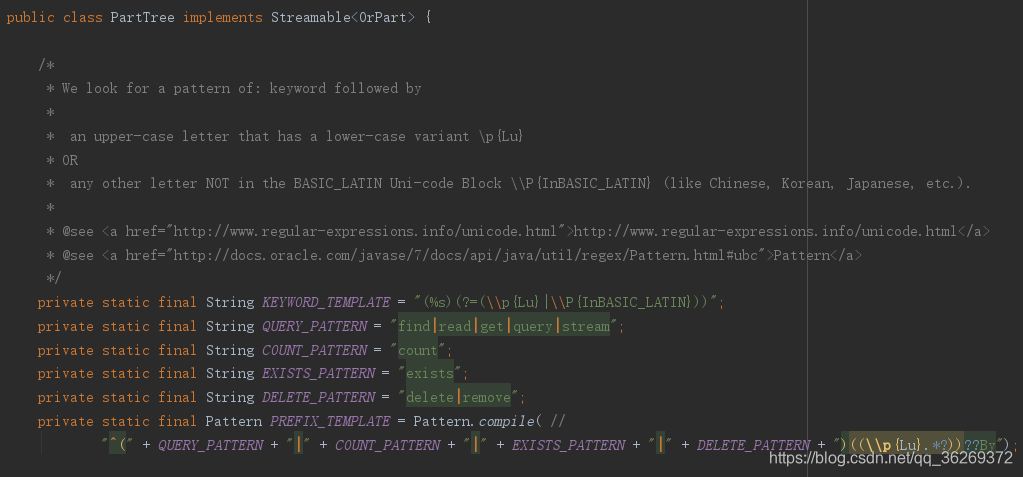
上图是PartTree类的属性,可以看到,利用正则表达式来匹配方法名。
-
现在,我们已经知道:
-
首先,在自定义Repository接口被创建时,由RepositoryFactorySupport创建代理,并在其构造函数中对此代理加入一个拦截器;
-
之后,此拦截器,根据查询策略,对该接口的自定义方法进行解析,根据查询策略选取不同的RepositoryQuery实现进行处理,即得到可执行的持久化语句。
到这里可以推断出,第三种采用显示JPQL/SQL语句查询的方法也是类似的思路,因为这两种查询都可以在查询策略中设置
还有一些不明朗的问题,比如RepositoryFactorySupport是怎么创建代理的;怎么根据查询策略选取不同的RepositoryQuery实现的,具体处理过程是怎么样的,还有待后续学习…(立个flag 等我学会了就更新)