前言
此篇随笔,参考了鼎鼎大名的《正则表达式30分钟入门》,原帖地址:http://deerchao.net/tutorials/regex/regex.htm
建议初学者可以玩玩正则表达式图解网站和表达式测试网站,可以更加直观的了解自己书写的正则表达式结构和作用。他们分别是
- 图解网站 https://regexper.com/
- 测试网站 http://tool.oschina.net/regex/# 当然这样的网站有很多,随便找一个就好。
如果您使用的是C#编程语言,那么可以参考的官方实例,便于您更好地去应用。
正文
此篇随笔的作用目的,简化教程。
第一节:
首先提问,正则表达式是用来干嘛的?
正则表达式是用来规定字符串形式的。所以正则表达式是一种规则。
比如 a 就是一个正则表达式,代表所有的 a 字符, ab 就代表所有的 ab 两个字母顺序组成的字符串。
点号.代表通配符(意思是随便某个字符)。星号*代表任意数量(大于等于0个)的*前面的元素。^代表字符串开头,$代表字符串结尾;
比如如果你想规定字符串是以A起始,Z结束的。那么就可以这么写正则表达式 A.*Z
这句正则表达式可以这么阅读:
A:就是规定这个字符串起始以一个大写的A作为开头。后面接着 一个 “ . ” 一个点号:代表A字符后面是任意字符。然后“.”后面又接着*代表前面的 . 通配符可以重复无数次。重复无数次之后,接着的是Z,说明字符串需要在Z之后结束。然后或许你可以去图解网站或者说测试网站,去看看他们的实际效果,是不是和我一样。

图解网站对于它的结构分析
如果以后遇到正则表达式,你可以试试自己心中所想的结构,心中所想的效果,是否与实际结构,实际效果相匹配。
第二节:
既然 . 和 * 分别代表不同的东西,那么我要规定的字符串里面有 . 和 * 怎么办?
就像很多编程语言一样,正则表达式也需要使用 \* 这种形式来表示 * 本意。 他的形式是在符号前,加上一个 \ 来表示这个符号的本身。需要转义的字符有很多,你可以去google一下都有哪些。我可以给出几个常见的,如同:\ / . * 你可以就扫两眼,知道有这么个特殊的存在就行了。当然, 如果你想使用 \ 的字符含义,可以使用 \\ 来表示一个 \ 。
当然 \ 后面也可以接字母,表示更多的含义,比如 \d 表示数字,即0~9。 \w 表示任意大小写字母或者下划线或者汉字, \s 表示一个空格。
现在如果你想在一段文字里面,匹配出所有的https://www.cnblogs.com/那应该怎么写呢?
答案是 https:\/\/www\.cnblogs\.com\/ 简直没难度好吗?就是需要注意 . 点号和 / 斜线需要转义。
像上面的正则表达式中的连续3个 w 可以使用 w{3} 表示,代表连续的3个 w ,这样正则表达式变成了这样:https:\/\/w{3}\.cnblogs\.com\/
那么,我们要引入一个新的概念 :“重复” 。比如之前接触过的 * ;它代表 * 之前的,能够重复0或者无数次。
还有{m,n}表示重复次数从m次到n次。{n} 表示重复n次;{n , }表示至少重复n次。除了这些以外还有 + 表示至少重复1次, ? 表示最多只能有1次,即可以有,可以没有。
第三节:
在进行第三节的开始,首先要问一个问题:如果想要匹配到所有的IP地址,那我应该怎么写呢?
也就是,一个形如 0~255.0~255.0~255.0~255 的字符串,他是0~255中的四个数字,中间以 . 隔开。如果要匹配这样的字符串,正则表达式要怎么写呢?
如果要匹配这样的字符串,我们就得引入新的概念,那就是:“分枝”和 “范围” ;
首先我们来看范围,他的形式是这样的:中括号,内部是一个字符集合,如[0-9],这是指一个0~9之间的一个数字,相同的[a-z]指小写的a到z的26个字符,[A-Z]表示大写的A到Z;他们也可以拼起来。像[0-9a-zA-Z]就表示数字,小写字母或者大写字母。补充一点,在方括号里面加入 ^ 可以表示否定,即[^2345]表示除了 2,3,4,5 以外的任意字符都满足。另外[0-9]只能表示一位,如果你想表示0~255,[0-2][0-5][0-5]或者[0-2][0-9][0-9]好像可行,但是都对范围进行了错误的表达。
这时候,我们就要用到"分枝"了。分枝就是 或条件“ | ”。就像我想表示0~3 或者 6~8 那我可以这么写:[0-36-8],也可以这么写:([0-3])|([6-8])代表,前面括号的内容,或者是后面括号的内容。
现在 [0-36-8] 和 ([0-3])|([6-8]) 效果一样,是因为位数都是一位。如果要表示0~255,只是一个单位的范围是解决不了的。要分250~255、200~249和000~199三种情况。分别是
- 25[0-5]
- 2[0-4]\d ( \d 前面提到过,表示0-9的数字,与[0-9]完全等价 )
- [0-1]?\d?\d
再使用分枝的形式合并:(25[0-5])|(2[0-4]\d)|([0-1]?\d?\d) 这就是表示0~255的一个正则表达式;它的结构如图所示:
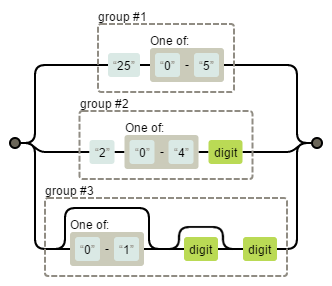
(25[0-5])|(2[0-4]\d)|([0-1]?\d?\d) 的结构
在匹配IP地址的时候,这个结构需要使用4次,中间分别用 . 隔开,你可以在 (25[0-5])|(2[0-4]\d)|([0-1]?\d?\d) 之后接上 \. 一个点号,再使用 {3},用到我们第二节学到的重复结构。变成这样:
((25[0-5])|(2[0-4]\d)|([0-1]?\d?\d)\.){3}((25[0-5])|(2[0-4]\d)|([0-1]?\d?\d))
这就是匹配IP地址的正则表达式,那么,它的结构是什么样的呢?实际效果如何呢?你可以动手试一试!
第四节:
好了,第四节是最后一节,让我们来挑战有点难度的东西。
就比如说下面这样一段字符串:BSABCMSTDMSSBAABSDFSMSTABCW
我们称连续3个字母的为一组,现在我们要找出这段字符串中从某一组起始,然后以相同组结尾的字符串。该怎么写正则表达式呢?
也许你心中已经有了想法,可能你是这么写的 \w{3}\w*\w{3}
很好理解嘛,三个字母起始三个字母结束。但是这样匹配到的是全部的字符串,因为“ 起始组和结尾组是相同的 ”这个要求没有体现。
如果有某种方法,能够让后面能够调用到前面匹配到的东西就好了。没错,这就要引出一个新概念,“ 后向应用 ”;
后向应用其实很简单,正则表达式中的括号和括号内的内容被视为一个分组,这个分组可以被引用。这些分组命名是从1开始递增的。
就像上面的问题的答案一样,(\w{3})\w*\1 这个正则表达式中第一个括号,代表1号分组,后续可以使用 \1 表示调用第1分组的相同内容。
有些才思敏捷的小可爱早已经发现,在正则表达式的图解网站,就有分组的标识。
好了,如果你已经掌握了后向应用的内容,那么我们来点刺激的实践吧。你看 [\u4e00-\u9fa5] 代表的是汉字字符,中国有一篇古文叫 《千字文》。闲来无事,你可以去找找无标点版本的千字文,看看千字文有没有重复的汉字。
好了,关于这一节,还有一个小知识点,按惯例,还是抛出一个问题:如果我想匹配一个以 abc 结尾的字符串,但是我不要abc这三个结尾字符,我该怎么写?
你应该知道到在正则表达式后面接 abc 表示的就是 abc 结尾的字符串。问题是,我只是想设置不以a开头的条件,并不想要其他的字符。
因此我们要加入新的知识点:断言。
断言:断言是一种特殊的分组,他有四种基本形式。比如
(?=abc) 表示匹配的字符串必须以abc结尾,但是不要abc这个尾巴。
(?<=abc) 表示匹配的字符串必须以abc开头,但是不要abc这个开头。
(?!abc) 表示匹配的字符串只要不以abc结尾都行
(?<!abc) 表示匹配的字符串只要不以abc开头都行
他们都不占字符串,被称为 “零宽断言”
(?=abc) 这种形式的专业说法称为 “零宽度正预测先行断言”。专业名称没必要记,感兴趣可以去了解一下。
当然,括号内的abc可以是任何 正则表达式。
补充:贪婪和懒惰
因为贪婪和懒惰用也挺多,特来补充一点点知识:
正则表达式在匹配字符串时,默认是贪婪的,意思是,尽可能多的把全部相匹配的东西列举出来。
如果你需要更短,更少的字符串,需要在限制符号后面加上 ? 表示尽可能短的匹配。
最近发现懒惰在某些环境下不被支持了(例如上面我给出的测试网站),但是又不会报错,期待您的评论与我探讨各种特定的情况。
若有任何言语不当或者错误的地方,欢迎批评指正。感谢您的阅读。