% Create a cascade detector object.
faceDetector = vision.CascadeObjectDetector();
% Read a video frame and run the face detector.
videoFileReader = vision.VideoFileReader(infilename);
videoFrame = step(videoFileReader);
bbox = step(faceDetector,videoFrame);上面code中,第二个step会call CascadeObjectDetector.m
%CascadeObjectDetector Detect objects using the Viola-Jones algorithm
% DETECTOR = vision.CascadeObjectDetector creates a System object
% that detects objects using the Viola-Jones algorithm. The DETECTOR
% is capable of detecting a variety of objects, including faces and a
% person's upper body. The type of object to detect is controlled by
% the ClassificationModel property. By default, the DETECTOR is
% configured to detect faces.
%
% …………
%
% BBOXES = step(DETECTOR,I) performs multi-scale object detection on
% the input image, I, and returns, BBOXES, an M-by-4 matrix defining
% M bounding boxes containing the detected objects. Each row in
% BBOXES is a four-element vector, [x y width height], that specifies
% the upper left corner and size of a bounding box in pixels. When no
% objects are detected, BBOXES is empty. I must be a grayscale or
% truecolor (RGB) image.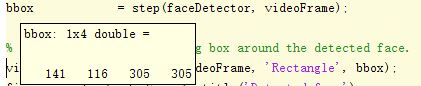
如说明,bbox是1*4向量,分布表示[x y width height],即边界框的左上角像素点坐标和边界框的size
% Create a point tracker and enable the bidirectional error constraint to
% make it more robust in the presence of noise and clutter.
pointTracker = vision.PointTracker('MaxBidirectionalError', 2);
% Initialize the tracker with the initial point locations and the initial% video frame.points = points.Location;initialize(pointTracker, points, videoFrame);
% get the next frame
videoFrame = step(videoFileReader);
% Track the points. Note that some points may be lost.
[points, isFound] = step(pointTracker , videoFrame);上面code中,step会call PintTracker.m
% [POINTS, POINT_VALIDITY] = step(H, I) tracks the points in the input
% frame, I. The output POINTS contain an M-by-2 array of [x y]
% coordinates that correspond to the new locations of the points in the
% input frame, I. The output, POINT_VALIDITY provides an M-by-1 logical
% array, indicating whether or not each point has been reliably tracked.
% The input frame, I must be the same size and data type as the video
% frames passed to the initialize method.其实points是xx * 2数组,xx表示特征点数目,points是所有特征的的坐标
isFound是xx * 1数组,表示特征点是否有track ok。ok是1,否则为0