一、引言
神经网络中,损失函数的选择希望能够有以下效果:
1、不同的预测结果能够产生不同的损失,越好的结果损失要越小
2、在损失较大的情况下,学习的速率要相对较快
二、对比
1、区分性
假设有以下两组数据,computed代表计算出来的概率,targets代表实际的标签,correct代表分类结果是否正确
数据组1:

数据组2:

Classification Error
可以看到数据组1的分类损失为:1/3=0.33,其中样本1和样本2只是刚刚好达到正确分类的概率值,而样本3就偏离正确分类非常远;
而数据组2的分类损失为:1/3=0.33,其中样本1和样本2相对较好的分到了正确的类别,而样本3距离正确的类别也不是相当远。
但以上两者的损失均为0.33,实际并没有体现出两者的区别,放到模型中,即是体现不出训练的效果。
Mean Squared Error
对于MSE,同样可以计算其损失:
在数据组1中,样本1的平方损失为:(0.3 - 0)^2 + (0.3 - 0)^2 + (0.4 - 1)^2 = 0.09 + 0.09 + 0.36 = 0.54
相当于数据组1的MSE损失为:(0.54 + 0.54 + 1.34) / 3 = 0.81;
同样,数据组2的MSE损失为:(0.14 + 0.14 + 0.74) / 3 = 0.34。
相比于分类损失,均方损失较好的体现了两组数据的不同。
Cross-Entropy Error
对于交叉熵,同样计算其损失,具体计算公式就不列举了,如下:
数据组1的平均交叉熵损失为:-(ln(0.4) + ln(0.4) + ln(0.1)) / 3 = 1.38;
数据组2的平均交叉熵损失为:-(ln(0.7) + ln(0.7) + ln(0.3)) / 3 = 0.64。
交叉熵损失同样能够体现出两组数据的区别。
从区分性可以得到,分类损失表现最差,均方损失与平均交叉熵损失表现较为良好。
2、学习速率
Mean Squared Error
在谈及学习速率时,实际上谈论的是什么呢?在神经网络中,抛开learning rate这个参数,假设存在一个简单网络:
在反向传播时,通过计算代价函数的偏导
和
来改变权重与偏置,所以实际上说学习速率慢说的是偏导很小。
对于上述简单网络,其表达式为z=wx+b,激活函数选择sigmoid,则有a=σ(z),假设存在样本x=1,y=0,根据均方根损失函数有,

对损失函数求偏导,可得,
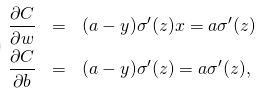
可以看到,最终偏导的大小有a与σ的偏导同时决定,再看看σ的图形:
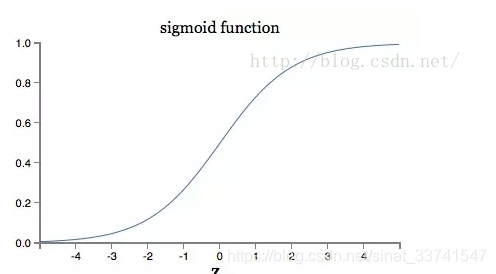
由图像可以看到,当输出接近1时,曲线变得非常平坦,相应的偏导变得非常小,也就是学习速度变慢了,这也是经常被提到的激活函数饱和。
所以均方损失面对以上情况时,效果较差。
Cross-Entropy Error
假设存在以下网络,
,
,样本x,标签为y,
那么交叉熵损失函数可定义为,
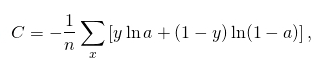
对损失函数求偏导,可得,
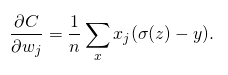
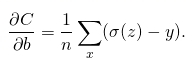
到这里可以看到,最终偏导由σ(z)-y决定,即是由预测的结果与实际标签的损失决定,误差越大学习速度越快。
由学习速度可以看到,交叉熵相对均方损失表现更好。
三、其他
1、https://jamesmccaffrey.wordpress.com/2013/11/05/why-you-should-use-cross-entropy-error-instead-of-classification-error-or-mean-squared-error-for-neural-network-classifier-training/
2、https://yq.aliyun.com/ziliao/576107