conv2d(input, filter, strides, padding, use_cudnn_on_gpu=True, data_format="NHWC", dilations=[1, 1, 1, 1], name=None)
"""Computes a 2-D convolution given 4-D `input` and `filter` tensors."""
给定4维的输入张量和滤波器张量来进行2维的卷积计算。
input:4维张量,形状:[batch, in_height, in_width, in_channels]
filter:滤波器(卷积核),4维张量,形状:[filter_height, filter_width, in_channels, out_channels]
strides:滤波器滑动窗口在input的每一维度上,每次要滑动的步长,是一个长度为4的一维张量。
padding:边界填充算法参数,有两个值:‘SAME’、‘VALID’。具体差别体现在卷积池化后,特征图的大小变化上面。卷积池化后特征矩阵的大小
终于明白,在进行2D卷积的过程中,例如输入的是一张rgb图像,则此时in_channels的值为3,再次卷积时卷积核的个数对应的是out_channels的大小,逐层的卷积,上层的out_channels的值即是下一层的in_channels的值。
卷积后的大小
W:矩阵宽,H:矩阵高,F:卷积核宽和高,P:padding(需要填充的0的个数),N:卷积核的个数,S:步长
width:卷积后输出矩阵的宽,height:卷积后输出矩阵的高
width = (W - F + 2P)/ S + 1
height = (H - F + 2P) / S + 1
当conv2d(), max_pool()中的padding=‘SAME’时,width=W,height=H,当padding=‘valid’时,P=0
输出图像大小:(width,height,N)
池化后的大小
width = (W - F)/ S + 1
height = (H - F) / S + 1
1D的卷积也是通过将维数扩充,再通过2D经计算
def conv1d(value,filters, stride, padding, use_cudnn_on_gpu=None, data_format=None, name=None)
"""Computes a 1-D convolution given 3-D input and filter tensors."""
给定三维的输入张量和滤波器来进行1维卷积计算。
input:3维张量,形状shape和data_format有关:
(1)data_format = "NWC", shape = [batch, in_width, in_channels]
(2)data_format = "NCW", shape = [batch, in_channels, in_width]
filters:3维张量,shape = [filter_width, in_channels, out_channels],
stride:滤波器窗口移动的步长,为一个整数。
Given an input tensor of shape [batch, in_width, in_channels] if data_format is "NWC", or [batch, in_channels, in_width] if data_format is "NCW", and a filter / kernel tensor of shape [filter_width, in_channels, out_channels], this op reshapes the arguments to pass them to conv2d to perform the equivalent convolution operation. Internally, this op reshapes the input tensors and invokes `tf.nn.conv2d`. For example, if `data_format` does not start with "NC", a tensor of shape [batch, in_width, in_channels] is reshaped to [batch, 1, in_width, in_channels], and the filter is reshaped to [1, filter_width, in_channels, out_channels]. The result is then reshaped back to [batch, out_width, out_channels] \(where out_width is a function of the stride and padding as in conv2d\) and returned to the caller.
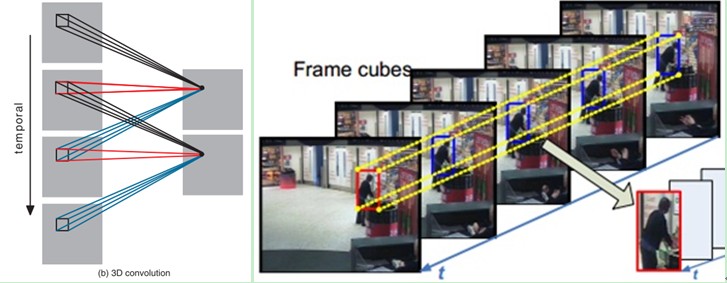
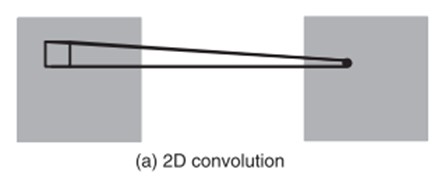
3D卷积针对的是视频帧,连续的视频帧形成了立方体,2D卷积只是利用了空间结构的信息,并没有利用到时间结构上的信息
3D卷积的呈现图为