版权声明:本文为博主原创学习笔记,如需转载请注明来源。 https://blog.csdn.net/SHU15121856/article/details/84032793
学习《Python3爬虫、数据清洗与可视化实战》时自己的一些实践。
认识SQLAlchemy
SQLAlchemy是Python的ORM工具,就像Java有Hibernate一样,实现关系型数据库中的记录与Python自定义Class的对象的转化,实现操作之间的映射。
书上底层用了pymysql,但是实践中会出现问题,网上查了一下改用mysql-connector-python就可以了。
from sqlalchemy import Column, String, create_engine
from sqlalchemy.orm import sessionmaker, scoped_session
from sqlalchemy.ext.declarative import declarative_base
# 映射对象的基类
Base = declarative_base()
# 连接数据库.指定编码为utf-8
# 使用mysqlconnector(安装mysql-connector-python)而不是pymsql,以解决下面的错误
# 错误1366:"Incorrect string value",下面是输出的异常信息
# latin-1' codec can't encode characters in position 58-62: ordinal not in range(256)
engine = create_engine('mysql+mysqlconnector://root:3838438@localhost:3306/k8', encoding='utf-8')
# 创建绑定于该连接的数据库会话.域session可以将session进行共享
DBSession = scoped_session(sessionmaker(bind=engine))
# 要映射到的类,它要继承前面的基类
class Product(Base):
# 映射到DB中的表名.私有属性(双'_'开头)
__tablename__ = 'product'
# 表的结构.使用Column对象,其中记录了该属性对应于数据库中的数据类型以及其它信息
id = Column(String(20), primary_key=True) # 标识为主键
name = Column(String(20))
type = Column(String(20))
# 添加用户
def add_user(user):
session = DBSession()
session.add(user)
try:
session.commit()
except Exception as e:
session.rollback()
# 输出异常信息
print("add_user(): ======={}=======".format(e))
finally:
session.close()
# 其它的一些测试
def other_test():
session = DBSession()
# 查询并更新用户
session.query(Product).filter(Product.id == '12345678').update({Product.name: "北京两日游"})
# 这样输出的是这些操作对应的SQL语句,并不是查询结果
# print(session.query(Product).filter(Product.id == '12345678'))
# 查询并查看查询结果
goal = session.query(Product).filter(Product.id == '12345678').one()
print('name:' + goal.name + ',type' + goal.type)
# 查询并删除用户
session.query(Product).filter(Product.id == '12345678').delete()
try:
session.commit()
except Exception as e:
session.rollback()
print("other_test(): ======={}=======".format(e))
finally:
session.close()
if __name__ == '__main__':
# 创建一个自定义的Product对象(因为继承了基类,这里不需要实现Product类的该构造器即可使用)
new_user = Product(id='12345678', name='上海一日游', type='景+酒')
# 添加用户的测试
add_user(new_user)
# 修改,查询和删除用户的演示
other_test()
运行结果:
name:北京两日游,type景+酒
简单操作Pandas中的DataFrame
Numpy那章讲得比较碎,内容也比较少,没有什么好记录的。Pandas数据处理这章的数据文件要到书网站上去下载。
import pandas as pd
# (1)从csv文件中读取数据生成DataFrame对象.按','分割,编码为utf-8,0号行作为列名
df = pd.read_csv("E:/Data/practice/taobao_data.csv", delimiter=',', encoding='utf-8', header=0)
# print(type(df)) # <class 'pandas.core.frame.DataFrame'>
# (2)将(刚刚读出的)df对象中的数据写到另一个csv文件中.columns指定要写的是哪些列,禁止写入索引,保存表头信息
df.to_csv("E:/Data/practice/test_in.csv", columns=['宝贝', '价格'], index=False, header=True)
# (3)取前3行(得到的还是DataFrame对象)
rows = df[0:3]
# print(rows)

# (4)取指定的某些列
cols = df[['宝贝', '成交量', '位置']]
# print(cols.head()) # 至多前5行

# (5)取前4行中的某些列.第一个维度指定行,在第二个维度上选取指定的列
print(df.ix[0:3, ['成交量', '价格']]) # 注意这里是0:3,另外ix方法已经被弃用
# 或(使用loc按label索引)
print(df.loc[0:3, ['成交量', '价格']]) # 这里0:3可以替换成df.index[0:4]
# 或(使用iloc按index索引)
print(df.iloc[0:4, df.columns.get_indexer(['成交量', '价格'])]) # 这里是0:4

# (6)从已有的列中计算新的列,并直接将其写入到df对象中
df['销售额'] = df['价格'] * df['成交量']
# print(df.head())
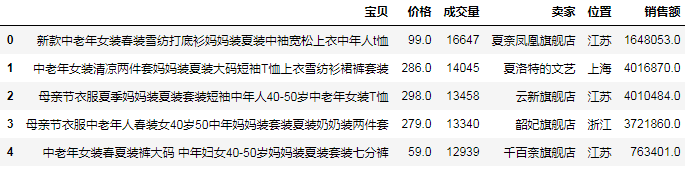
# (7)根据条件过滤行
result = df[(df['价格'] < 100) & (df['成交量'] > 10000)]
# print(result.head())

# (8)按照某个字段排序
df1 = df.set_index("价格").sort_index()
# print(df1.head())
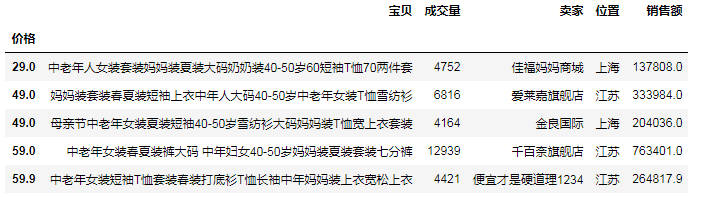
# (9)按照多个字段排序
# 默认level是0,这里即先"位置"再"价格"
df2 = df.set_index(['位置', '价格']).sort_index()
# print(df2)

# level设置为1时,这里即先"价格"再"位置"
df2 = df2.sort_index(level=1)
# print(df2)
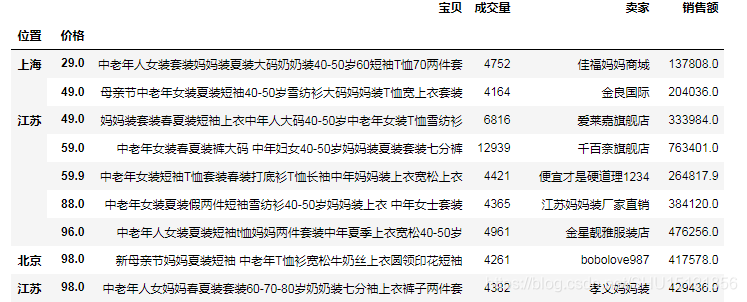
# (10)数据整理操作
# 先删除label为'宝贝'和'卖家'的列,然后按位置分组,计算组内的均值,再按成交量进行排序(降序)
df_mean = df.drop(['宝贝', '卖家'], axis=1).groupby("位置").mean().sort_values("成交量", ascending=False)
# print(df_mean)
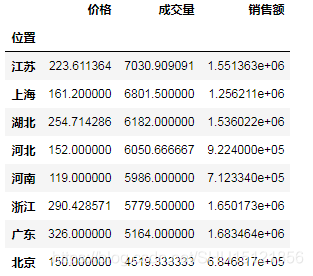
# 先删除label为'宝贝'和'卖家'的列,然后按位置分组,计算组内的加和,再按成交量进行排序(降序)
df_sum = df.drop(['宝贝', '卖家'], axis=1).groupby("位置").sum().sort_values("成交量", ascending=False)
# print(df_sum)
# (11)查看表的数据信息和描述性统计信息
print(df.info())
print(df.describe())
