版权声明:本文为博主原创文章,转载请注明出处。 https://blog.csdn.net/OOC_ZC/article/details/83999471
先看代码:
public class Main {
public static void main(String[] args) throws Exception{
String baseStr = "baseStr";
final String baseFinalStr = "baseStr";
String str1 = "baseStr01";
String str2 = "baseStr" + "01";
// JAVA 1.6之后,常量字符串的“+”操作,编译阶段直接会合成为一个字符串
// 所以str1与str2指向常量池中的同一引用地址。
String str3 = baseStr + "01"; // StringBuilder.append() 生成
String str4 = baseFinalStr + "01";
// final变量在编译后会直接替换成对应的值,所以实际上等于str4 = "baseStr" + "01"
// 而这种情况下,编译器会直接合并为str4 = "baseStr01",所以最终str1 == str4。
String str5 = new String("baseStr01").intern();
// intern()返回字符串池中的对象
System.out.println(str1 == str2); // true
System.out.println(str1 == str3); // false
System.out.println(str1 == str4); // true
System.out.println(str1 == str5); // true
}
}
其中String str3 = baseStr + "01";,这条语句编译器会自动调用StringBuilder类进行字符串拼接,以此来优化性能。
比如:
public class Test {
public static void main(String[] args) {
String s = "abc";
String ans = s + "def";
}
}
用javap -c Test.class 反编译
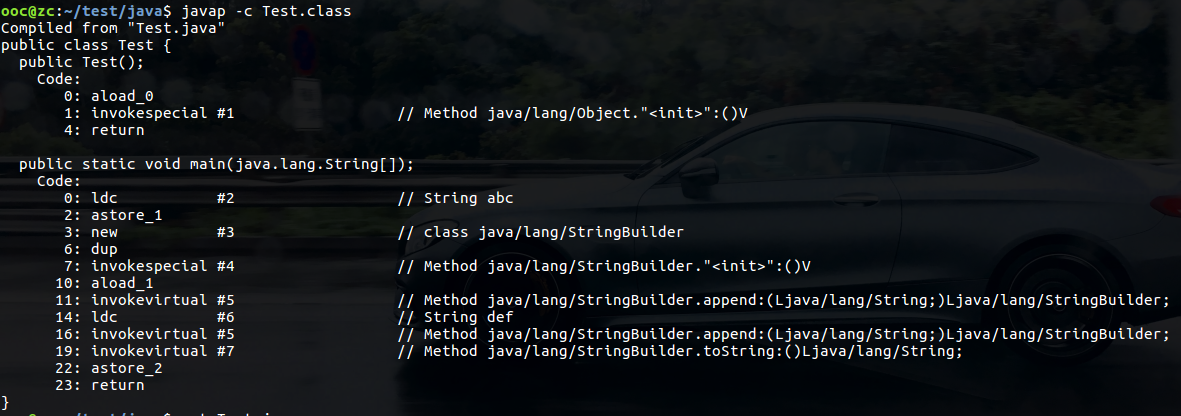
可以看出字符串用’+'运算符拼接时编译器会自动使用StringBuilder类优化性能,拼接完成后调用StringBuilder的toString()方法返回String对象。
虽然字符串拼接时会自动调用StringBuilder来优化性能,但不能太依赖编译器的自动优化,比如在循环条件下,编译器的优化可能并不好。(每次循环都新建一个StringBuilder对象)
StringBuilder 的toString()方法
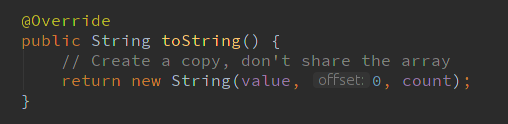
可以看出,这里用new新建了一个String对象,即不从字符串池中获取。
即在运行时进行拼接的String会生成新的String对象(在堆中),在编译器已经完成拼接的String对象在String Pool中。