前言
很多人在做网站的时候可能有这样的需求,前期网站内容不多需要从外站获取,需求量较大的时候,我们不可能手工进行转载。这时候“爬虫”显得尤为重要。下面就让我介绍在php下如何做一个“爬虫”。
前期我在做小程序的时候需要大量的关于电脑的文章(教程),自己打算写一个爬虫直接打算从网上爬取。由于自己的经验不足只单纯的利用了PHP的字符截取替换查找及正则表达式写了一个PHP爬虫,虽然最后达到了爬取的作用,但是因为使用这种方法只能针对具有一样排版的网站(或者说只适用于一个网站),所以当我需要获取其他网站内容时就需要重写算法。这极其不利于后期的维护。后来我想使用PYTHON爬虫获取内容然后入库,然后再用PHP去读,可是这样PYTHON也要和数据对接,这样也不利于维护。之后想到PY作为胶水语言,是不是可以和PHP一起使用呢?虽说可以,但是网上没有确切的解决办法,我也不想花时间去尝试PHP+PYTHON的方法。后面经过查找,找到了PHP中的爬虫类库QUERYLIST。有人可能会有疑问,调用这个类库就能后轻松的爬取内容了吗?我做个简单的比喻,PHP中的QueryList类库就相当于Python中的BS4(Beautiful Soup 4)模块。
QueryList类库
QueryList虽然可以让我们在PHP环境下轻松的爬取网站内容,但是在功能方面还是不如BS4,如果有特殊需求,建议使用Python BS4。
官方介绍
我们有时需要抓取一个网页的内容,但只需要特定部分的信息,通常会用正则来解决,这当然没有问题。正则是一个通用解决方案,但特定情况下,往往有更简单快 捷的方法。比如你想查询一个编程方面的问题,当然可以使用Google,但stackoverflow 作为一个专业的编程问答社区,会提供给你更多,更靠谱的答案。
对于html页面,不应该使用正则的原因主要有3个
1、编写条件表达式比较麻烦
尤其对于新手,看到一堆”不知所云”的字符评凑在一起,有种脑袋都要炸了的感觉。如果要分离的对象没有太明显的特征,正则写起来更是麻烦。
2、效率不高
对于php来说,正则应该是没有办法的办法,能通过字符串函数解决的,就不要劳烦正则了。用正则去处理一个30多k的文件,效率不敢保证。
3、有phpQuery
如果你使用过jQuery,想获取某个特定元素应该是轻而易举的事情,phpQuery让这成为了可能。
phpQuery
在介绍QueryList之前,有必要先来介绍一下phpQuery。
phpQuery是一个用php实现的类似jQuery的开源项目,可以在服务器端以jQuery的语法形式解析网页元素。
基本上jQuery的选择器都可以用在phpQuery上,phpQuery很强大可以对DOM进行任何复杂的操作,而接下来要介绍的QueryList则相当于phpQuery的子集,发挥它采集方面的强大功能。
QueryList
QueryList是一个基于phpQuery的PHP通用列表采集类,得益于phpQuery,让使用QueryList几乎没有任何学习成本,只要会CSS3选择器就可以轻松使用QueryList了,它让PHP做采集像jQuery选择元素一样简单。 QueryList的几个特点:
学习简单:只有一个核心的API
使用简单:用jQuery选择器来选择页面元素
自带过滤功能,可过滤掉无用的内容
支持无限层级嵌套采集
采集结果直接以采集规则以列表的形式有序的返回
支持扩展
下载安装使用
下载安装使用,请直接移步官方文档进行查看
官方文档
框架中使用QueryList
关于框架中使用的方法,官方给出的是THINKPHP3的教程,显然在现在来说THINKPHP3框架太老了,在我写这篇博文的时候THINKPHP框架已经更新到了5.1版本。QueryList官方提供的关于ThinkPHP3的使用方法在5中是不适用的。后期我会把这个补上,写一篇关于ThinkPHP5如何使用类库和QueryList在其中的一些使用技巧。(毕竟我也是刚接触到QueryList类库,需要一段时间的适应期,也希望有大佬可以指点。)
使用效果
- 网页原型
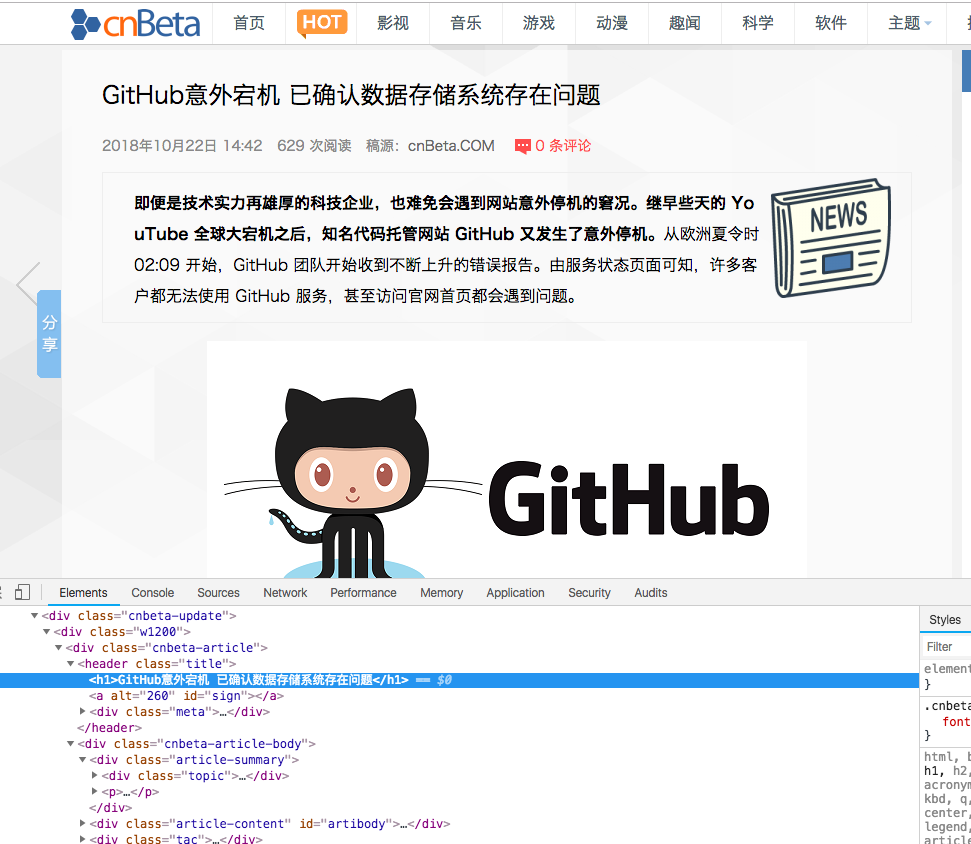
- 示例代码
<?php
require 'vendor/autoload.php';
use QL\QueryList;
// 待采集的页面地址
$url = 'https://www.cnbeta.com/articles/tech/779841.htm';
// 采集规则
$rules = [
// 文章标题
'title' => ['.title>h1','text'],
// 发布日期
'date' => ['.meta>span:eq(0)','text'],
// 文章内容
'content' => ['#artibody','html']
];
$data = QueryList::Query($url,$rules)->data;
print_r($data);
- 效果
Array
(Array
(
[0] => Array
(
[title] => GitHub意外宕机 已确认数据存储系统存在问题
[date] => 2018年10月22日 14:42
[content] => <p style="text-align: center;"><img src="https://static.cnbetacdn.com/article/2018/1022/82e649adfde2e98.png" alt="github-down-due-to-data-storage-system-issue-523345-2.png"></p>
<p>发稿前,GitHub 已经排除了部分故障。目前似乎只有某些特定地区受到了影响,但欧洲等部分地区仍未完全恢复。</p>
<blockquote>
<p>GitHub 团队表示,数据存储系统是导致本次故障的罪魁祸首。为尽快恢复服务,他们正在努力修复。</p>
<p>过去的几个小时,所有工作都集中在这方面。在此期间,部分用户可能看到不一致的结果。</p>
</blockquote>
<p>今年早些时候,<a data-link="1" href="https://afflnk.microsoft.com/c/1251234/439031/7808" target="_blank">微软</a>宣布以 75 亿美元收购 GitHub 。近日,欧盟委员会认定微软接管 GitHub 不违背反竞争原则,并准予放行。</p>
<p>[编译自:<a href="https://news.softpedia.com/news/github-down-due-to-data-storage-system-issue-523345.shtml" target="_self">Softpedia</a>]</p>
)
)
END
文章仅代表作者个人观点,转载请注明出处!
文章地址:https://www.orbpi.cn/article/zuophppachongzhiquerylistkuphppachongchajian.html