版权声明:原创博客,不得用于商业用途 https://blog.csdn.net/qq_43471020/article/details/84025549
需求:已知一个excel 表中的"Sheet1"中,有id, name, salary 3列的内容,要求将薪水重复次数最多的按从高到低进行排序
#coding=utf-8
import xlrd
from collections import Counter
import operator
file = r'C:\\Users\\belle.zhao\\Desktop\\test.xlsx'
data = xlrd.open_workbook('C:\\Users\\belle.zhao\\Desktop\\test.xlsx','rb') # 打开excel文件
table = data.sheet_by_name('Sheet1') # 选择sheet页
ncols = table.ncols # 获取sheet1 页的列数
nrows = table.nrows # 获取sheet1页的行数
colsvalue = table.col_values(2) # 读取第3列(索引从0开始)的值存在变量"colsvalue"中
cols2=colsvalue[1:] # 将去除第1个值后的其他元素存到新的变量"cols2"中
list1 = []
list2 = []
# 法一遍历
for n in cols2:
if int(n) > 4000:
list1.append(n)
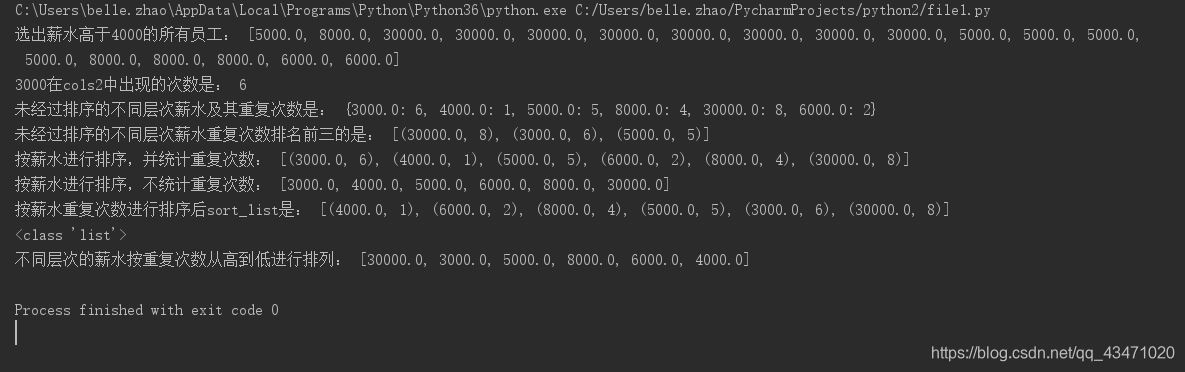
print("选出薪水高于4000的所有员工:",list1)
# # 法二遍历
# for i in colsvalue[1:]:
# if i >= 4000:
# list2.append(i)
# print("选出薪水高于4000的所有员工:",list2)
one_count=cols2.count(3000) # 统计3000在clos2中出现的次数
print("3000在cols2中出现的次数是:",one_count)
repet_salary={} # 定义一个空的字典
for n in cols2:
if n not in repet_salary.keys():
repet_salary[n]=cols2.count(n)
print("未经过排序的不同层次薪水及其重复次数是:", repet_salary) # 根据表中薪水出现的次数进行统计,未进行排序
print("未经过排序的不同层次薪水重复次数排名前三的是:" ,Counter(repet_salary).most_common(3))
sort_count=sorted(Counter(repet_salary).most_common())
print("按薪水进行排序,并统计重复次数:",sort_count)
sort_salary=sorted(repet_salary)
print("按薪水进行排序,不统计重复次数:",sort_salary)
sort_list=sorted(repet_salary.items(), key=operator.itemgetter(1)) # 将repet_salary按第二个元素(重复次数)进行排序
print("按薪水重复次数进行排序后sort_list是:",sort_list)
print(type(sort_list))
result=[]
for item in sort_list[::-1]: # sort_list[::-1] 将sort_list里的元素倒叙排列
result.append((item[0]))
print("不同层次的薪水按重复次数从高到低进行排列:" , result)
运行结果如下: