Java 爬虫实战案例三之 HttpClient 详解
1. 代码
package httpClient;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
/**
* 1.this class is used to get a html by HttpClient
*/
public class HelloHttp {
public static void main(String[] args) throws IOException {
CloseableHttpClient httpClient = HttpClients.createDefault();//创建httpClient实例
HttpGet httpGet = new HttpGet("http://www.csdn.net"); //创建httpGet实例
CloseableHttpResponse response = httpClient.execute(httpGet);//指向http get请求
HttpEntity entity = response.getEntity();//获取返回实体
System.out.println("网页内容:"+ EntityUtils.toString(entity,"utf-8"));//获取网页内容
response.close();
httpClient.close();
}
}
2. 运行结果
网页内容:<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no">
<meta name="apple-mobile-web-app-status-bar-style" content="black">
<meta name="referrer"content="always">
····
})
</script>
<script src='//csdnimg.cn/pubfooter/js/publib_footer-1.0.3.js?v201807020000' data-isfootertrack="false"></script>
window.csdn.indexSuperise({
smallMoveImg: '//ubmcmm.baidustatic.com/media/v1/0f0002xZEmQ-Pg-yUBISo0.png',
bigMoveImg: '//ubmcmm.baidustatic.com/media/v1/0f0002xZEmU-Pg-yUBISC0.png',
link:'//edu.csdn.net/topic/python115?utm_source=rightpopup',
trackSuperId: 647
});
</script></div></html>
3. 问题
3.1 屏蔽请求
但是问题会随着请求网址的变化而变化。如果将上述的网址由www.csdb.net变换成www.tuicool.com时,就会发现出现如下的执行结果:
网页内容:<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
</head>
<body>
<p>系统检测亲不是真人行为,因系统资源限制,我们只能拒绝你的请求。如果你有疑问,可以通过微博 http://weibo.com/tuicool2012/ 联系我们。</p>
</body>
</html>
这是因为我们单纯使用程序是无法获取被限制的资源的,那么该如何解决呢?
解决办法很简单,我们只需要在请求httpGet中添加一个请求头即可,如下:
httpGet.setHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64; rv:63.0) Gecko/20100101 Firefox/63.0");
有人会问,这个 User-Agent是什么?这个代表的意思就是:使用的代理用户,这里添加上述语句的原因在于,模拟浏览器发送一个请求。这个User-Agent的值可以在浏览器中查看得到。
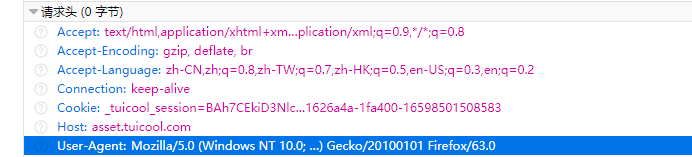
接着执行程序得到的结果如下:
网页内容:<!DOCTYPE HTML>
<!--
______________
< TUICOOL.COM >
--------------
\ ^__^
\ (**)\__$__$__
(__)\ )\/\
U ||------|
|| ||
-->
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta name="csrf-param" content="authenticity_token" />
<meta name="csrf-token" content="J+HCJtgjgLVvVpjfK4imYYZ1TAQYONE+cMG8aXDYlpEfn6mc0xx2Q/b3/wwm3FPmXFw0sdj4dCerVtH9ZvNYdA==" />
<title>
推酷 - IT人专属的个性聚合阅读社区 - 推酷
···
<div style="display:none;">
<script src="https://s22.cnzz.com/stat.php?id=5541078&web_id=5541078" language="JavaScript"></script>
</div>
<script type="text/javascript" src="https://static2.tuicool.com/assets/tip.js?t=3" async></script>
</body>
</html>
如果再更改程序如下:
public static void main(String[] args) throws IOException {
CloseableHttpClient httpClient = HttpClients.createDefault();//创建httpClient实例
HttpGet httpGet = new HttpGet("http://www.tuicool.com"); //创建httpGet实例
httpGet.setHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64; rv:63.0) Gecko/20100101 Firefox/63.0");
CloseableHttpResponse response = httpClient.execute(httpGet);//指向http get请求
HttpEntity entity = response.getEntity();//获取返回实体
System.out.println("Content-Type :"+entity.getContentType());//获取内容类型
System.out.println("Status : "+response.getStatusLine());//判断响应状态
response.close();
httpClient.close();
}
执行结果如下:

其中 Content-Type 表示的是获取到的实体内容属于什么类型;Status表示的是这个请求的响应状态是什么。如果此时将请求地址写为:http://www.tuicool.com/dsfsd,再次测试结果如下:

因为这个地址是明显不存在的,所以请求的 Status 变为了404,但是因为仍然有请求的内容,所以Content-Type仍然是 text/html
3.2 屏蔽IP
因为部分原因,可能会导致发出请求的主机ip被服务器的反爬虫程序监控到,这样就会导致反爬虫程序将ip拉入黑名单,如果我们开发的程序再以此ip发出请求时,就会拒绝请求。那么这个问题该怎么解决呢?
解决方法很简单,主要是通过使用代理ip的方式,能够解决上述问题的方法就是使用“高匿代理”,这是一种代理ip,我们使用此代理ip,就可以实现安全的访问目标主机了。但是这个“高匿代理”的ip怎么获取呢?很简单,baidu一下即可。如下所示:

从中随机选择一个,再修改一下我们的代码,如下所示:
public static void main() throws IOException{
CloseableHttpClient httpClient = HttpClients.createDefault();//创建httpClient实例
HttpGet httpGet = new HttpGet("http://www.tuicool.com/"); //创建httpGet实例
HttpHost proxy = new HttpHost("114.235.22.147", 9000);
RequestConfig config = RequestConfig
.custom()
.setProxy(proxy)
.setConnectTimeout(10000)//连接超时
.setSocketTimeout(10000)//读取超时
.build();
httpGet.setHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64; rv:63.0) Gecko/20100101 Firefox/63.0");
CloseableHttpResponse response = httpClient.execute(httpGet);//指向http get请求
HttpEntity entity = response.getEntity();//获取返回实体
//System.out.println("网页内容:"+ EntityUtils.toString(entity,"utf-8"));//获取网页内容
System.out.println("Content-Type :"+entity.getContentType());//获取内容类型
System.out.println("Status : "+response.getStatusLine());//判断响应状态
response.close();
httpClient.close();
}
执行结果如下:
