一.冯诺依曼模型:
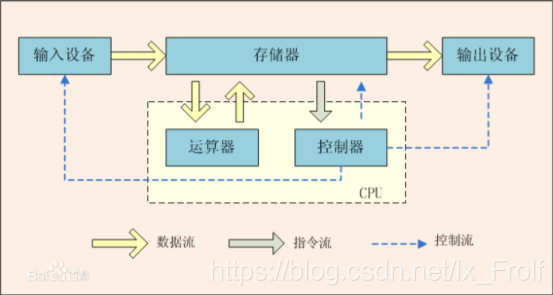
计算机体系中的经典理论-冯.诺依曼体系:计算机硬件由运算器、 控制器、存储器、输入设备、输出设备五大部分组成。在分布式领域中,不管架 构怎么变化,计算机仍没有跳出该体系的范畴。
二.分布式领域中冯诺依曼模型的变化
1.输入设备的变化
在分布式系统架构中,输入设备可以分两类,第一类是互相连接的多个节点,在接收其他节点传来的信息作为该节点的输入;另一种就是传统意义上的人机交互的输入设备了
2.输出设备的变化
输出和输入类似,也有两种,一种是系统中的节点向其他节点传输 信息时,该节点可以看作是输出设备;另一种就是传统意义上的人 际交互的输出设备,比如用户的终端
3.控制器的变化
在单机中,控制器指的是 CPU 中的控制器,在分布式系统中,控 制器主要的作用是协调或控制节点之间的动作和行为;比如硬件负 载均衡器;LVS软负载;规则服务器等
4.运算器
在分布式系统中,运算器是由多个节点来组成的。运用多个节点的 计算能力来协同完成整体的计算任务
5.存储器
在分布式系统中,我们需要把承担存储功能的多个节点组织在一起, 组成一个整体的存储器;比如数据库、redis(key-value存储)
三.分布式系统的特点
分布式系统对于集中式系统而言,在实现上会更加复杂。分布式系统将会是更难理解、设计、构建 和管理的,同 时意味着应用程序的根源问题更难发现。
1.三态
在集中式架构中,我们调用一个接口返回的结果只有两种, 成 功或者失败,但是在分布式领域中,会出现“超时”这个状态。
2.分布式事务
事务就是一系列操作的 原子性保证,在单机的情况下,我们能够依靠本机的数据库连 接和组件轻易做到事务的控制,但是分布式情况下,业务原子 性操作很可能是跨服务的,这样就导致了分布式事务的出现,例如A 和B操作分别是不同服务下的同一个事务内的操作,A调 用B,A可以清楚的知道B是否成功提交从而控制自身的 提交还是回滚操作,但是在分布式系统中调用会出现一个新状 态就是超时,就是A无法知道B是成功还是失败,这个时候A 是提交本地事务还是回滚呢?其实这是一个很难的问题,如果 强行保证事务一致性,可以采取分布式锁,但是那样会增加系 统复杂度而且会增大系统的开销,而且事务跨越的服务越多, 消耗的资源越大,性能越低,所以最好的解决方案就是避免分 布式事务。 还有一种解决方案就是重试机制,但是重试如果不是查询接口,必然涉及到数据库的变更,如果第一次调用成功但是没返回成 功结果,那么对于调用方来说第二次调用依然是重试,但是 对于被调用方来说是重复调用。这样的结果不 是我们期望的,因此需要在写入的接口做幂等设计。多次调用 和单次调用是一样的效果。通常可以设置一个唯一键,在写入 的时候查询是否已经存在,避免重复写入。但是幂等设计的一 个前提就是服务是高可用,否则无论怎么重试都不能调用返回 一个明确的结果,调用方会一直等待,虽然可以限制重试的次数, 但是这已经进入了异常状态,甚至到了极端情况还是需要人 肉补偿处理。其实根据CAP和BASE理论,不可能在高可用分 布式情况下做到一致性,一般都是最终一致性保证。
3.负载均衡
每个服务单独部署,为了达到高可用,每个服务至少是两台机 器,因为互联网公司一般使用可靠性不是特别高的普通机器, 长期运行宕机概率很高,所以两台机器能够大大降低服务不可 用的可能性,大型项目会采用十几台甚至上百台来部署一 个服务,这不仅是保证服务的高可用,更是提升服务的 QPS, 但是一个请求过来到底路由到哪台机器? 路由算法很多,如DNS路由,如果session在本机,还会根据 用户id或则cookie等信息路由到固定的机器,当然现在应用服务器为了扩展的方便都会设计为无状态的,session 会保存 到专有的 session 服务器,所以不会涉及到拿不到 session 问 题。路由规则可以随机获取,但实际情况肯定比这个复杂,在一定范围内随机,但是在大的范 围也会分为很多个域,例如如果为了保证异地多活的多机房, 跨机房调用的开销太大,肯定会优先选择同机房的服务,这个 要参考具体的机器分布来考虑。
4.一致性
数据被分散或者复制到不同的机器上,如何保证各台主机之间 的数据的一致性将成为一个难点。
5.故障的独立性
分布式系统由多个节点组成,整个分布式系统完全出问题的概 率是存在的,但是在实践中出现更多的是某个节点出问题,其 他节点都没问题。这种情况下我们实现分布式系统时需要考虑 得更加全面些 。
上一篇:分布式架构的演进过程
下一篇:分布式架构的基本理论和高可用设计