菜鸡一只!如果有什么说错的还请大家指出批评,坚决改正!!
遇到了一个挺诡异的报错把,反正比较无语,发现国内网站完全搜不到这个报错的解决方法,因此在这里记录下!!
1、环境:
这是一个spark的Task not serializable问题,因此只需要关注spark的版本就好了,我的版本是spark2.2.0的版本!
2、具体报错:
Exception in thread "main" org.apache.spark.SparkException: Task not serializable
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:298)
at org.apache.spark.util.ClosureCleaner$.org$apache$spark$util$ClosureCleaner$$clean(ClosureCleaner.scala:288)
at org.apache.spark.util.ClosureCleaner$.clean(ClosureCleaner.scala:108)
at org.apache.spark.SparkContext.clean(SparkContext.scala:2287)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsWithIndex$1.apply(RDD.scala:841)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsWithIndex$1.apply(RDD.scala:840)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:362)
at org.apache.spark.rdd.RDD.mapPartitionsWithIndex(RDD.scala:840)
at org.apache.spark.sql.execution.WholeStageCodegenExec.doExecute(WholeStageCodegenExec.scala:389)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:117)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:117)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:138)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:135)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:116)
at org.apache.spark.sql.execution.exchange.ShuffleExchange.prepareShuffleDependency(ShuffleExchange.scala:88)
at org.apache.spark.sql.execution.exchange.ShuffleExchange$$anonfun$doExecute$1.apply(ShuffleExchange.scala:124)
at org.apache.spark.sql.execution.exchange.ShuffleExchange$$anonfun$doExecute$1.apply(ShuffleExchange.scala:115)
at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:52)
at org.apache.spark.sql.execution.exchange.ShuffleExchange.doExecute(ShuffleExchange.scala:115)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:117)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:117)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:138)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:135)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:116)
at org.apache.spark.sql.execution.InputAdapter.inputRDDs(WholeStageCodegenExec.scala:252)
at org.apache.spark.sql.execution.aggregate.HashAggregateExec.inputRDDs(HashAggregateExec.scala:141)
at org.apache.spark.sql.execution.WholeStageCodegenExec.doExecute(WholeStageCodegenExec.scala:386)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:117)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:117)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:138)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:135)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:116)
at org.apache.spark.sql.execution.SparkPlan.getByteArrayRdd(SparkPlan.scala:228)
at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:311)
at org.apache.spark.sql.execution.CollectLimitExec.executeCollect(limit.scala:38)
at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$collectFromPlan(Dataset.scala:2853)
at org.apache.spark.sql.Dataset$$anonfun$head$1.apply(Dataset.scala:2153)
at org.apache.spark.sql.Dataset$$anonfun$head$1.apply(Dataset.scala:2153)
at org.apache.spark.sql.Dataset$$anonfun$55.apply(Dataset.scala:2837)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:65)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:2836)
at org.apache.spark.sql.Dataset.head(Dataset.scala:2153)
at org.apache.spark.sql.Dataset.take(Dataset.scala:2366)
at org.apache.spark.sql.Dataset.showString(Dataset.scala:245)
at org.apache.spark.sql.Dataset.show(Dataset.scala:644)
at org.apache.spark.sql.Dataset.show(Dataset.scala:603)
at org.apache.spark.sql.Dataset.show(Dataset.scala:612)
at com.test.XXX.getXXXX(App.java:473)
at com.test.BaseTest.main(BaseTest.java:66)
Caused by: java.io.NotSerializableException: org.apache.spark.unsafe.types.UTF8String$IntWrapper
Serialization stack:其实报错挺长的,后面还有,不过看报错还是要提取关键字的:其实就是这个类,或者这个对象无法序列化!!!org.apache.spark.unsafe.types.UTF8String$IntWrapper
3、产生的原因(可看图):

这里是使用spark DSL语法,写的sql,将A表和B表做join的同时,还用到了case when语法,并在case when内嵌套了sql的窗口函数(sql有一点点复杂,但是还好),如果大家不太懂怎么写,可以参考我的图,不过这里马赛克打得乱七八糟的,希望各位谅解,毕竟这种东西,你懂的。。。当我要show t1和t2字段的时候就出报错了(如果不打印那两个字段,不会报错)!
相对应的sql:
SELECT 查询字段5,查询字段6,查询字段7,查询字段8,
FROM (
SELECT
查询字段1,
查询字段2,
查询字段3,
查询字段4,
case when (MAX(XXX) OVER w ) =1 then 1 else 0 end AS t1,
case when (MIN(XXX) OVER w ) =0 then 1 else 0 end AS t2
FROM (
select Z,ZZ,ZZZ,ZZZZ
from 表A
where 过滤条件
) info
INNER JOIN
(
select X,XX,XXX,XXXX
from 表B
WHERE 过滤条件
) hav
ON info.关联字段=hav.关联字段
WINDOW w AS (PARTITION BY 字段A,字段B, 字段C ORDER BY 字段D RANGE BETWEEN 窗口时间 PRECEDING AND 窗口时间 FOLLOWING)
) db1
WHERE 过滤字段
; 4、解决方法:
方法一:
经过测试发现,如果直接把sql写好,然后使用spark.sql(“selectXXXX”),这种方式是不会报错的,真的想骂人,这种方式也是可以,但是我可能个人有点强迫症(领导让你来写代码,结果你就写了一段sql,用这种方式运行,大家肯定会觉得你是在敷衍了事),所以不想采用这种方法,我想把这个报错调好
方法二:
上下求索,终于让我找到解决方法!
我去google上搜索相关的东西,找到了(id:debugger87)一位大神向spark提交的pr(pull request)!
地址:https://github.com/debugger87/spark/commit/2bd33d819137220c55e8ddf7b6df7b98945046aa
如果大家看不懂这篇pull request在说什么,那我来说说:
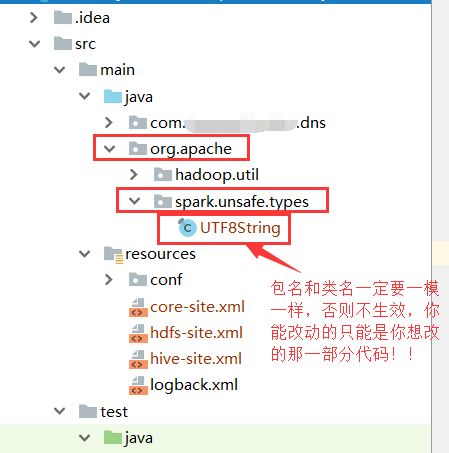
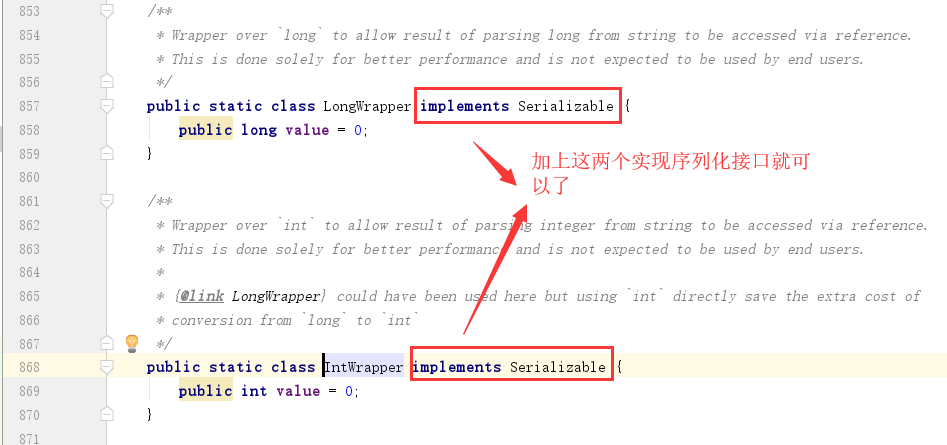
这两个静态类是在org.apache.spark.unsafe.types.UTF8String这个类里面的!
修改方式:

直接修改肯定是不可能的,因为这是编译好的类!
1、下载spark源码,找到这个类,先把这个地方写上implements Serializable,然后编译源码,运行的时候用自己的源码的环境来运行(比较麻烦,因为你如果不会编译的话。。。但是本人也有写一篇如何编译的文章,大家可以参考下,亲测成功)
编译博客:https://blog.csdn.net/lsr40/article/details/80116235
2、直接把需要修改的源码类,复制出来放到自己的项目中,这样运行的时候,自己写的类就会覆盖源码中的类,就实现了修改,如图:
如果这样还看不明白,那留言给我号了,比如什么复制代码出来,怎么创建一模一样的package这一类的问题等。。。
这里留一篇文章,这是一般人会遇到的序列化问题的解决方法(其实这类报错就是看到底哪个类序列化失败,然后去实现序列化接口,或者不要在map等闭包算子内,引用外部对象变量,你可以直接在map算子内手动创建就好了,或者考虑广播变量等方式),原谅我找不到原作者了,我看到这篇文章的作者也是转载的,而且也没有标明出处,如有冒犯原作者的地方,还请谅解,如果原作者看到,可以私聊我,我愿意添加上您的id!
序列化问题:https://blog.csdn.net/javastart/article/details/51206715
刚刚提到了闭包,可能会有人问什么是闭包!?(又是一篇被转载没有标明出处的文章,不好意思)
闭包:https://blog.csdn.net/wy_blog/article/details/57130702
好了,老话,菜鸡一只,如果有什么说的不对的,还请大家批评指出!
==========================================================================
经过了实际的线上测试!发现该问题在本地跑,直接如上文修改就可以了,但是如果是在服务器上跑!请注意看我下面的描述:
首先对于之前没有说明白,表示歉意!
1、本人经过尝试,在服务器上跑,无论打成胖包还是打成瘦包,spark都不会读取我们自己修改的UTF8String这个类,只会读取本地的jar包(因为这个类是spark本身就有的jar包,不是外部添加的,这个jar包名字spark-unsafe_2.11-2.2.0.jar)。因此按照上文那样的修改方式,本地生效在服务器上不生效!
2、考虑了几种解决方法:
3、后来,我还遇到了数据倾斜的问题,我会在下一篇文章当中提出解决的方案(其实这个方法很早就有了,大数据解决数据倾斜的思想是比较重要而且比较通用的)-1.升级或者降级服务器上的spark版本(但是这。。。不可能说想换版本就换版本的,除非你真有那个权限)
-2.去集群上所有机器的spark的lib下替换spark-unsafe_2.11-2.2.0.jar(换成你改完的,但是这也不现实,工作量未免太大)
-3.当你在使用窗口的时候,使用sparksession.sql("sql")这种方式来运行!(本人就使用这种,就是直接把sql写上去,就可以避免这个错误)