本人菜鸡,最近还更新python的爬虫系列,有什么错误,还望大家批评指出!
该系列暂时总共有4篇文章,连接如下:
【python】爬虫篇:python连接postgresql(一):https://blog.csdn.net/lsr40/article/details/83311860
【python】爬虫篇:python对于html页面的解析(二):https://blog.csdn.net/lsr40/article/details/83380938
【python】爬虫篇:python使用psycopg2批量插入数据(三):https://blog.csdn.net/lsr40/article/details/83537974
【pykafka】爬虫篇:python使用python连接kafka介绍(四):https://blog.csdn.net/lsr40/article/details/83754406
在上一篇文章中,我讲到了python批量插入数据库,但是因为访问url的线程多的原因,可能会导致接入数据库的线程也多,对于数据库在说是一种压力,因此,我用到了另一个框架:kafka
整体架构调整如下图:
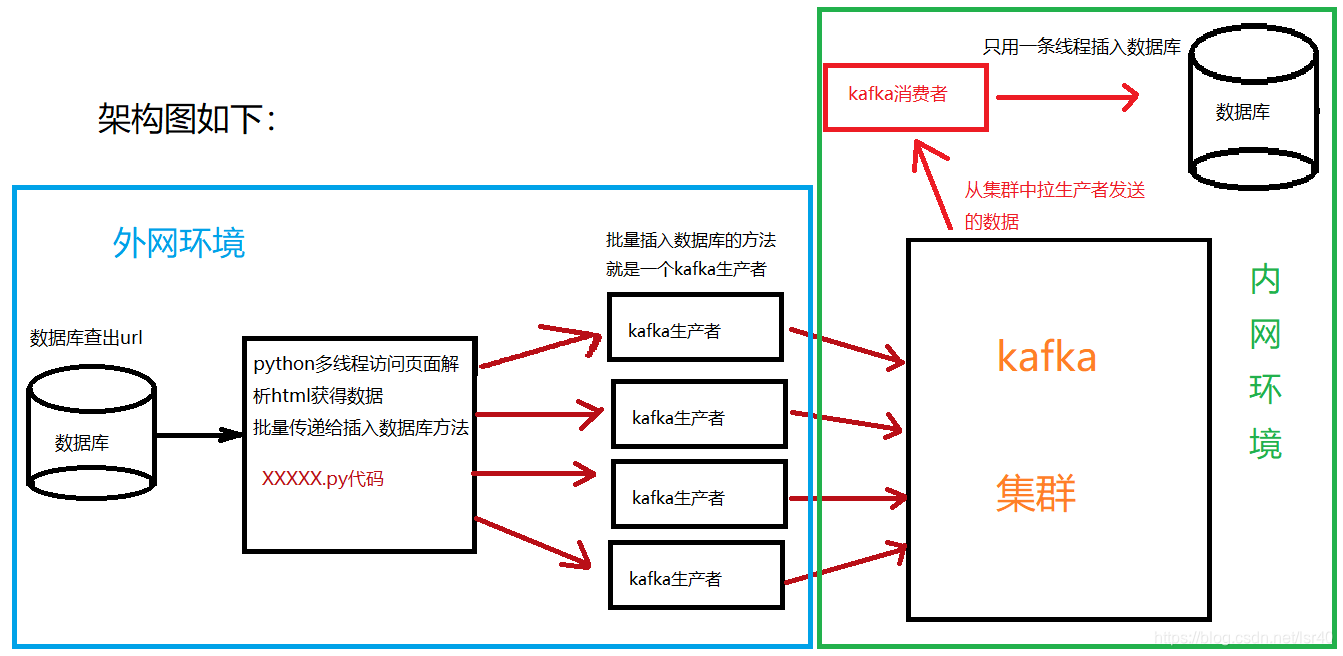
喜欢看文字描述的朋友可以看看如下解释:
在集群外的一台机器上启动一个python脚本,该脚本从数据库读出数据,然后将这些数据分发给多个线程,每个线程各自访问url,解析正文,创建一个kafka的生产者往kafka中发送数据(有多少条线程,就有多少个kafka信息),接着在内网环境中,启动一个kafka消费者,将所有生产者传递过来的数据解析,并批量插入数据库。
然后我再说几个点:
1、我试过,如果每个kafka生产者获取到个url的正文,就往kafka发送消息,这样相对来说可以更加保证数据不丢失,但是消费者会消费来不及,也就是说会有数据延迟,而且把生产者关了一段时间,消费者还消费不完(延迟挺严重),所以还是得通过拼接字符串的方式,使得一条kafka消息中,有几十(甚至可以更多)条数据,然后消费端再解析这个数据,批量插入数据库(详细看代码),节省时间和资源。
2、数据是否会出现问题,会的,我来列举下会丢或者重复数据的几个地方。
- 丢失数据:
- urllib获取页面信息的时候,有可能超时,所以那个页面就跳过去了
- 生产者发送数据的时候,有可能因为网络或者其他原因没发送成功(大部分是因为网络)
- 数据重复:
- 消费者消费完数据之后,由于消费者的程序挂了,没能将偏移量提交到zookeeper上,导致下次再开启消费者的时候,重复消费数据,但是因为我的消费者压力不大,所以没有出现主动挂掉的情况
总结:我会通过sql的join方式,每次都从数据库中拿出那些未被处理的数据,也就是说丢数据也无所谓,数据重复的问题,可以用主键(一张表内不会出现两条相同主键的数据),或者最后用sql来对表进行去重的方式来解决。
3、python连接kafka有两个包:pykafka和kafka-python
具体他们之间孰好孰坏,可以看下pykafka开发者在自己的GitHub给别人的回答:https://github.com/Parsely/pykafka/issues/334,当然是全英文的。不过(作者:高尔夫golf,标明转载)https://blog.csdn.net/konglongaa/article/details/81206889有对于这个issue的中文翻译和总结,如果大家有兴趣可以去看下,当然,这个issue的回答有些年代了,所以也不一定完全正确,比如里面说pykafka只支持0.8.2版本的kafka,但是我使用了kafka_2.11-1.0.1版本,完全没有版本不兼容的问题。
代码如下:
生产者:
from concurrent.futures import ThreadPoolExecutor
import time
import urllib.request
import psycopg2
from lxml import etree
from pykafka import KafkaClient
def insertManyRow(strings):
print('insertManyRow:',strings)
# 多条数据间使用 =.= 来做分隔符
b="=.=".join(strings)
try:
print('进入到生产者代码!')
client = KafkaClient(hosts="broker1:端口1,broker2:端口2,broker3:端口3")
# 查看所有topic
print(client.topics)
topic = client.topics['指定发送的topic名称'] # 选择一个topic
# 同步发送数据
with topic.get_sync_producer() as producer:
# 数据转换成byte才可以发送
producer.produce(bytes(b, encoding="utf8"))
except Exception as e:
print("发送失败%s" % (e))
def productList(rows):
string=''
# 将多条数据放入list中
strings=[]
count = 0
for row in rows:
file = urllib.request.urlopen(row[2],timeout=5)
try:
data = file.read()
#是否被封号,从偏移量3000的位置往下找
isBan=str(data).find('被封号的字符串', 3000)
if(isBan!=-1):
string='ip被封'
else:
selector = etree.HTML(data)
data = selector.xpath('//*[@id="zhengwen"]/p/span/text()')
# 将获取到的多个正文内容拼接成一条字符串
for i in data:
if (i != None):
string = string + i
# 打印查看
print('正文:', string)
# 将数据库中一条数据的多个字段通过 -.- 拼接到一起
content=row[0]+'-.-'+row[1]+'-.-'+string+'-.-'+row[3]+'-.-'+row[4]
# 放入list中
strings.append(content)
# 清空字符串
string = ''
print("集合:", strings)
print("集合长度:",len(strings))
count = count + 1
# 每十条数据就调用一次kafka生产者的代码
if (count >= 10):
print('进入到insertManyRow')
insertManyRow(strings)
strings = []
count = 0
except Exception as e:
print("线程出错:%s" % (e))
if __name__ == '__main__':
conn = psycopg2.connect(database="数据库", user="用户名", password="密码",
host="ip",
port="端口")
cur = conn.cursor()
sql = "查询的sql,查出未处理的url"
cur.execute(sql1)
rows = cur.fetchall()
print('拉取到数据')
start=time.time()
# 开启10个线程,每个线程每次拉取10条url
with ThreadPoolExecutor(10) as executor:
for i in range(0, len(rows)//10, 1):
executor.submit(productList, rows[i*10:(i+1)*10])
end = time.time()
print("time: " + str(end - start))
conn.close()
消费者:
from pykafka import KafkaClient
import psycopg2
client = KafkaClient(hosts="broker1:端口1,broker2:端口2,broker3:端口3")
# 查看所有topic
print(client.topics)
topic = client.topics['指定发送的topic名称'] # 选择一个topic
#获得一个均衡的消费者
balanced_consumer = topic.get_balanced_consumer(
consumer_group=bytes('消费者组名',encoding='utf-8'),
auto_commit_enable=True,# 设置为False的时候不需要添加consumer_group,直接连接topic即可取到消息
#kafka在zk上的路径,这个路径应该和kafka的broker配置的zk路径一样(不然zk上会放得乱七八糟的。。。)
zookeeper_connect='zk1:端口1,zk2:端口1,zk3:端口3/kafka在zk上的路径'
)
# arrs=[]
insertarr=[]
for message in balanced_consumer:
print(message)
if message is not None:
#print(message.offset, message.value, type(message.value), str(message.value, encoding="utf8"))
#将接受到的数据转换成executemany能接受的数据格式
arrs=str(message.value, encoding="utf8").split('=.=')
for arr in arrs:
a=arr.split('-.-')
insertarr.append(a)
try:
conn = psycopg2.connect(database="数据库", user="用户名", password="密码",
host="ip",
port="端口")
cur = conn.cursor()
sql = "INSERT INTO 数据库.表名(字段1,字段2,字段3,字段4,字段5) VALUES(%s,%s,%s,%s,%s)"
print(insertarr)
cur.executemany(sql, insertarr)
conn.commit()
insertarr = []
conn.close()
except Exception as e:
print("插入错误:%s" % (e))
insertarr=[]
conn.close()
所以,到这里,这个爬虫系列的文章就更新到这里了!因为我使用到了kafka框架,下一篇文章,应该会说下kafka生产者,消费者的一些东西,比如,我使用的get_balanced_consumer这个api,然后还有第一篇文章说的分类的东西,我也会开博客来记录!