
http协议----基于请求报文和响应报文完成一次http事务
应用层协议格式有两种: 文本(开发容易,但交互解析困难如http smtp),二进制(交互解析容易,但理解起来困难memocache)
状态码:304 已经请求过,但是资源没什么改变返回304;对于get请求,只返回head,以表示资源有没有

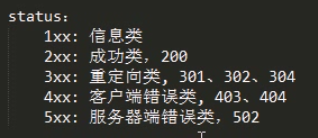
缓存:在速度不匹配之间的网络组件之间添加缓存以达到性能最优。请求首部中的if-Modified-Since,If-None-Match是关键信息
user-agent加载的仅仅是web框架,资源家在的过程就是向服务器请求的过程,如果一个页面有很多url,逐一请求主机的话,浪费时间,就需要通过缓存提高加载速度,如果是多核资源,可能并发2个请求
所以,对于服务器,可能同时接受到2个或多个请求,但这可能来自同一个请求客户端!!!
现如今,服务器面对的成千上万的并发也就毫不奇怪了,常见的优化方式:例如看到第一屏,(只加载第一屏,除非添加滚轮),或者压垮所有服务。
pv:整个页面有很多请求(链接),通过日志数据挖掘做广告投放和用户行为分析,虽然有站长统计工具,但大型网站最好自行统计pv;计算标准是访问一个网站入口后能完整的呈现页面就算是一个pv
uv:独立IP,日uv,一天内有多少独立ip地址发起过页面访问
为了客户端打开页面时尽可能的快:通常的做法有:加载缓存和并发访问,不过现如今浏览器都是多线程的,任意浏览器对于单个域名线程数是有上限的,例如访问域名A,开启两个线程,访问域名B,开启两个线程
所以对于同一网站可以设置多个二级域名,并把资源,如图片,视频,文本文件分散部署到各二级域名的方法来实现一个站点开启多线程的方式达到访问效率的优化。

httpd mpm多路处理模块有三种模式:prefork 主进程以管理员身份启动生成多个子进程,可以监听80端口,凡小于1024端口号的谓之特权端口

- I/O类型:所谓I/O,一方请求服务,另一方调用服务,那么,请求方如何得知什么时候得知自己的请求被响应了呢(如何通知调用者)
同步synchronous:调用发出后,不会立即返回,一旦返回,则返回最终结果
异步asychronous调用发出后,被调用方立即反馈消息,但并非最终结果,被调用者通过回调函数,状态信息,通知机制等通知调用方处理结果(银行服务,拿到排队号,被叫号的过程)
上述关注的是消息通知的机制
------------------------------------------------------
以下关注的是请求发出者等待被调用者返回结果时的状态
阻塞block:调用者没结果一直出等待状态,被挂起
非阻塞non-block:调用者不会被阻塞

- 阻塞式I/O blocking I/O:一个进程通常只能处理单步I/O
- 非阻塞式I/O:盲等待,polling模型正基于此,过一段时间就去咨询是否完成,效率不一定优于阻塞,所谓非阻塞,是指从磁盘加载数据到内核空间这一段;从内核内存复制到应用进程阶段仍是阻塞的
- I/O多路复用,一个进程只能处理单步I/O,以向服务器请求资源为例,一步负责监听请求(网络I/O),一步负责请求数据,由于从内核空间复制数据到应用进程内存时处于阻塞状态,这时进程处于“不可终止睡眠状态”,即使网络I/O发生异动也不可能作出响应,按理说,在请求时间过长时,我们也无法取消请求,可现实生活中的例子告诉我们,我们确实可以取消请求,这就是多路复用I/O(无非是在网络请求和磁盘请求之间添加了一个“代理”,代i理会转发请求给空闲的进程,支持两路以上的复用----这就是select() 由BSE研发 poll()和select()功能一致,但是局限在于1024条请求,尽管可以改代码,但实际上1024是并发的极限,超出后拒绝服务,select是复用代理)---其实还得阻塞,只不过可以分身干点别的
- 事件驱动式I/O:被调用者会回复调用者-----你的请求我拿到了,10分钟后ok,你可以先干点别的,这就免去了盲等(这一阶段一个进程可以处理n个请求);然而第二步从内核内存到进程内存的过程依然阻塞;一旦收到就绪的通知,会调用回调函数完成后续的操作(callback)
- 异步I/O
一个典型的应用进程发起I/O请求的步骤
向内核空间请求数据-------->内核没有------>向磁盘请求数据------>把磁盘数据复制到内核内存----->再把数据拷贝到应用进程内存(每个应用进程都有各自独立的空间);真正的I/O过程就是从内核复制数据到应用进程内存的那一步