Hive与HBase整合的实现是利用两者本身对外的API接口互相通信来完成的,其具体工作交由Hive的lib目录中的hive-hbase-handler-*.jar工具类来实现,通信原理如下图所示。
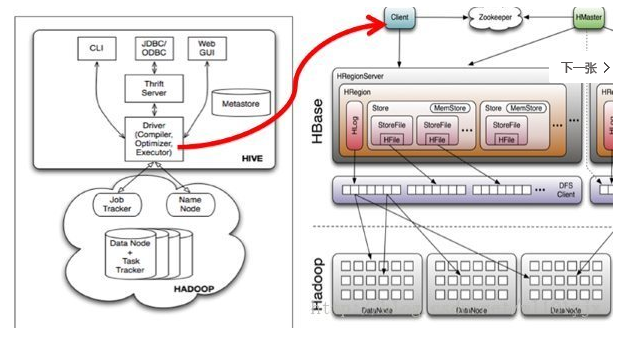
Hive整合HBase后的使用场景:
(一)通过Hive把数据加载到HBase中,数据源可以是文件也可以是Hive中的表。
(二)通过整合,让HBase支持JOIN、GROUP等SQL查询语法。
(三)通过整合,不仅可完成HBase的数据实时查询,也可以使用Hive查询HBase中的数据完成复杂的数据分析。
Hive内置服务
Hive自带了许多服务,可在运行时通过service选项来明确指定使用什么服务,或通过--service help来查看帮助。下面介绍最常用的一些服务。
(1)CLI:这是Hive的命令行界面,用的比较多。这是默认的服务,直接可以在命令行里面使用。
(2)hiveserver:这个可以让Hive以提供Trift服务的服务器形式来运行,可以允许许多不同语言编写的客户端进行通信。可以通过设置HIVE_PORT环境变量来设置服务器所监听的端口号,在默认的情况下,端口为 10000。最新版本(hive1.2.1)用hiveserver2取代了原有的hiveserver。
(3)hwi:它是Hive的Web接口,是hive cli的一个web替换方案。
(4)jar:与Hadoop jar等价的Hive接口,这是运行类路径中同时包含Hadoop和Hive类的Java应用程序的简便方式。
(5)Metastore:用于连接元数据库(如mysql)。在默认情况下,Metastore和Hive服务运行在同一个进程中,端口号为9083。使用这个服务,可以让Metastore作为一个单独的进程运行,我们可以通过METASTORE_PORT来指定监听的端口号。
Hive映射HBase表
<property>
<name>hive.zookeeper.quorum</name>
<value>10.116.33.109,10.27.185.72,10.25.203.67 </value>
<description>
List of ZooKeeper servers to talk to. This is needed for:
1. Read/write locks - when hive.lock.manager is set to
org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager,
2. When HiveServer2 supports service discovery via Zookeeper.
3. For delegation token storage if zookeeper store is used, if
hive.cluster.delegation.token.store.zookeeper.connectString is not set
4. LLAP daemon registry service
</description>
</property>2.将hbase lib目录下的所有文件复制到hive lib目录中
cd /data/spark/hbase-2.0.0-alpha4/lib
cp * /data/spark/apache-hive-2.3.2-bin/lib$ hive shell
> create table hive_hbase_test(key int,value string) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping"=":key,cf1:val") tblproperties("hbase.table.name"="hive_hbase_test");$ hbase shell
> listHive Hbase测试
1.Hive 导入数据,Hbase查看数据
vim test.txt
1 zhangsan
2 lisi
3 wangwu
4 老司机
数据列以tab 分割
Hive 创建表,并加装外部数据
create table test(key int,value string) row format delimited fields terminated by '\t';
load data local inpath'/data/spark/apache-hive-2.3.2-bin/test.txt' overwrite into table test;
select * from test;
将hive的test表中的数据加载到hive_hbase_test表
insert overwrite table hive_hbase_test select * from test;
select * from hive_hbase_test;测试服务器内存不够,最后导入没有成功。
2.通过Hbase put添加数据,Hive查看添加数据。
put 'hive_hbase_test','100','cf1:val','laosiji'Hive 查看
select * from hive_hbase_test;说明Hive和Hbase数据完全一致,类似数据库中的表和视图关系,如果是外部表,二者之间数据则不是关联的。
通过结合,可以设计一个高速写入,后面接入实时分析的海量数据分析系统。
这种组合可以有多种解决方案,Kafka+Spark/jStorm
创建外部表
create external table hive_hbase_test(key int,value string)stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping"=":key,cf1:val") tblproperties("hbase.table.name"="hive_hbase_test");未删除hive/lib目录下的jar
报错
Caused by: java.lang.NoSuchMethodError: org.apache.hadoop.hbase.HBaseConfiguration.createClusterConf(Lorg/apache/hadoop/conf/Configuration;Ljava/lang/String;Ljava/lang/String;)Lorg/apache/hadoop/conf/Configuration;
at org.apache.hadoop.hbase.mapreduce.TableOutputFormat.setConf(TableOutputFormat.java:226)
at org.apache.hive.common.util.ReflectionUtil.setConf(ReflectionUtil.java:101)
at org.apache.hive.common.util.ReflectionUtil.newInstance(ReflectionUtil.java:87)
at org.apache.hadoop.hive.ql.io.HiveFileFormatUtils.getHiveOutputFormat(HiveFileFormatUtils.java:302)
at org.apache.hadoop.hive.ql.io.HiveFileFormatUtils.getHiveOutputFormat(HiveFileFormatUtils.java:292)
at org.apache.hadoop.hive.ql.exec.FileSinkOperator.createHiveOutputFormat(FileSinkOperator.java:1168)
... 38 more
内存空间不够报错:
Diagnostic Messages for this Task:
Error: org.apache.hadoop.hbase.client.HTable.<init>(Lorg/apache/hadoop/conf/Configuration;Ljava/lang/String;)V
2018-04-02 17:24:09,498 INFO [ca66ff2f-3431-4765-b550-28f7ed1fb9ae main] impl.YarnClientImpl: Killed application application_1522660651503_0001
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
2018-04-02 17:24:09,512 WARN [ca66ff2f-3431-4765-b550-28f7ed1fb9ae main] mapreduce.Counters: Group FileSystemCounters is deprecated. Use org.apache.hadoop.mapreduce.FileSystemCounter instead
Stage-Stage-3: Map: 1 HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec
参考:
大数据学习系列之五 ----- Hive整合HBase图文详解