此为火车头采集器的页面
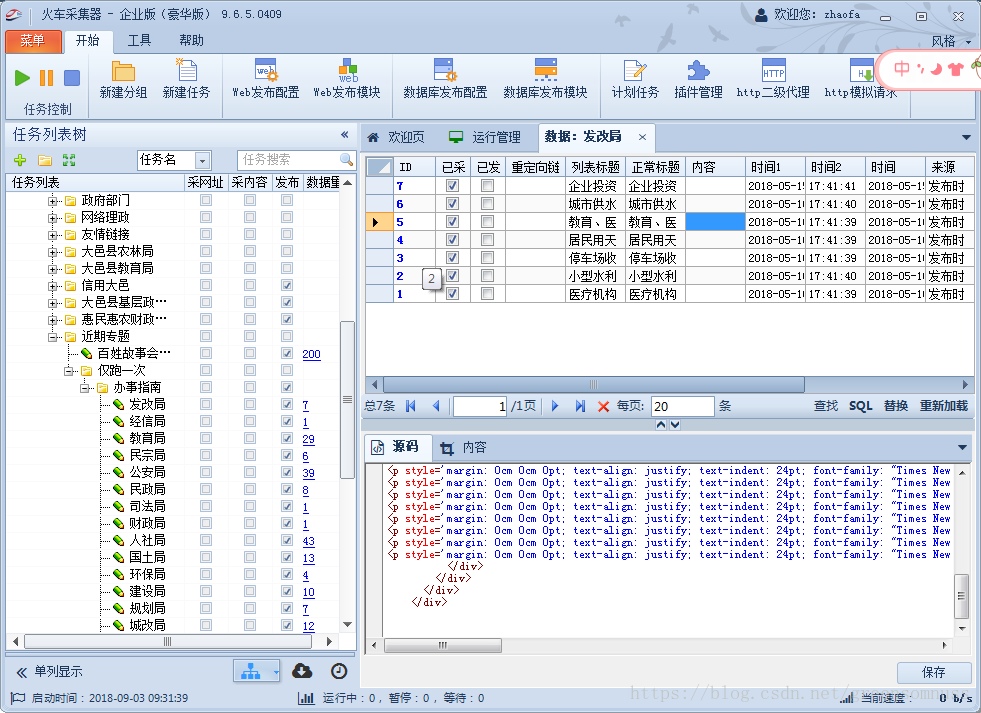
*左边建立分组,建议结构都和所需要采集的数据结构一致,不然数据多了起来,很容易混乱。
1, 创建任务
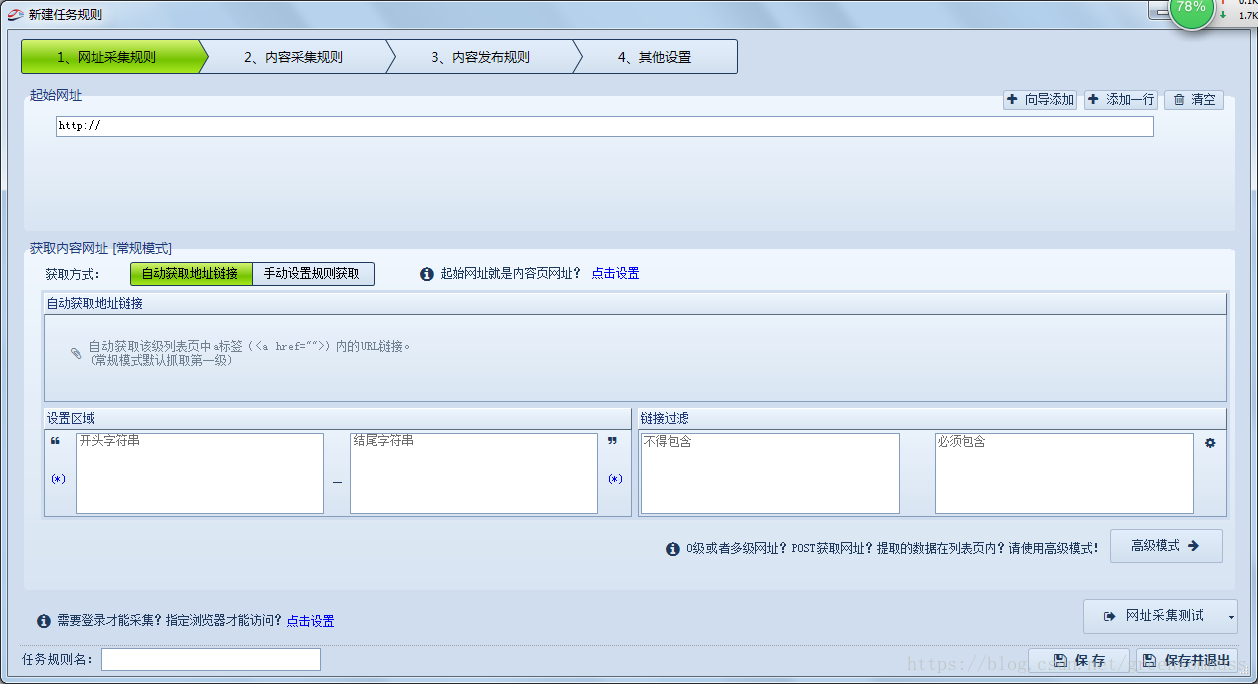
起始网址是指你需要抓取的网址,例如:http://www.day.gov.cn/dayi/c108528/list_1.shtml
下面的获取内容的网址是指你需要起始网址里面你需要跳转的页面的网址,设置的区域是指那你所要跳转的页面的起始的字符串,这里我们一般选择手动设置规则获取网址,例如:

一般的重定向链接可通用的规则:
<a(*)href="[标签:重定向链接]"(*)>[标签:列表标题]</a>
2,接下来点击网址采集测试
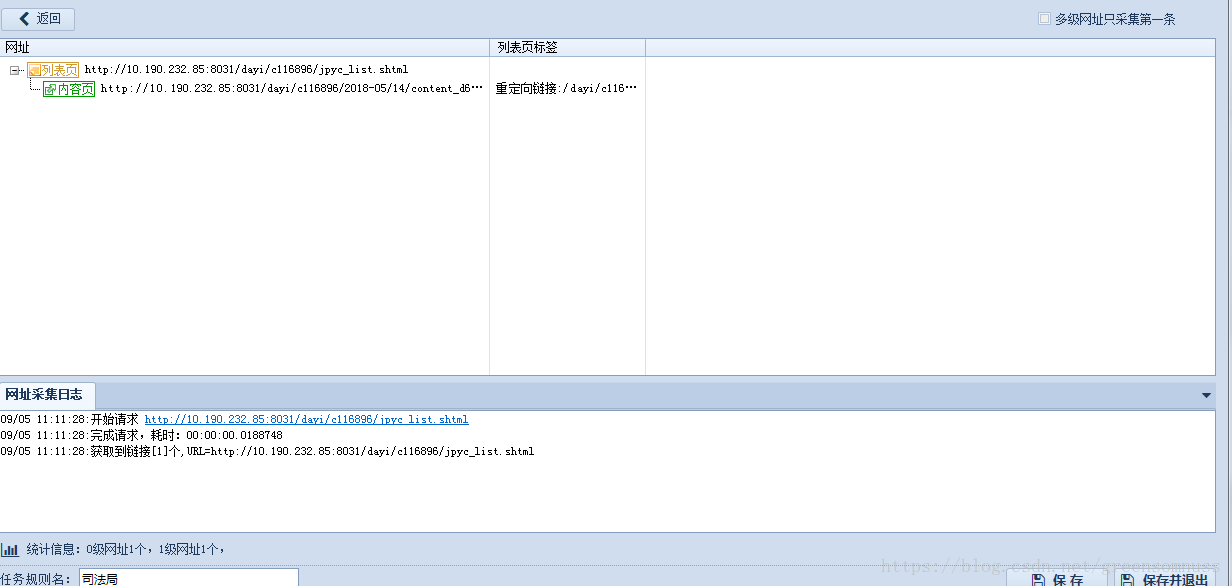
会出现你需要抓取的网页的地址。
3,选中其中一条
双击进入 ,右下方的测试
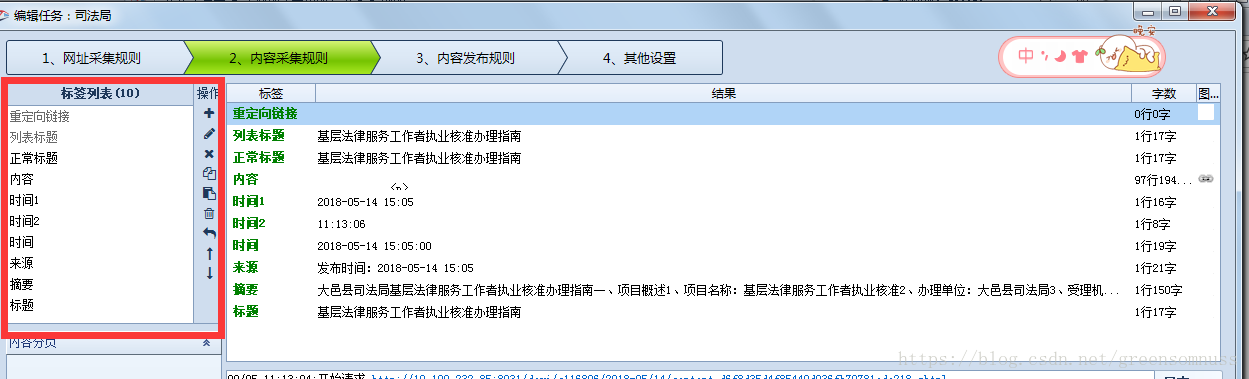
这里的标签列表是指你在此网站的内容中需要抓取的内容和字段的配置,提取的字段也可以使用起始字符串。
测试的时候就会出现你所需要的字段。
3,内容发布规则会在后面具体讲解。
4,其它设置
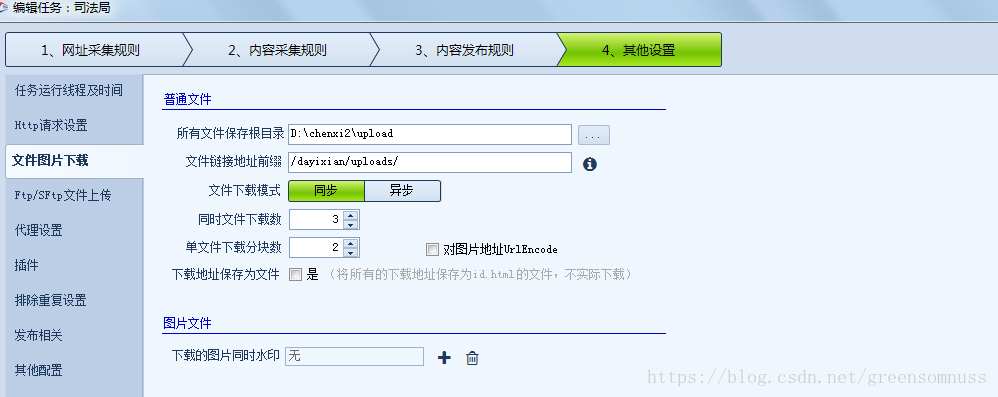
如果抓取的内容包含图片附件或者视频,这里需要设置一下地址, 所有文件保存根目录是指本地路径,这里如果程序放在服务器上,需要把附件这些传到对应的服务器。
这里的文件链接地址前缀是指下载下来火车头采集器会把你的附件或图片的地址前缀加上如上。
(提示:这里的前缀地址要与你的服务器的部署的访问站点地址一致哦)
* web发布配置
点击保存或退出以后,返回界面,点击web发布配置。

可以新建一个,这里新建的一个信息类:
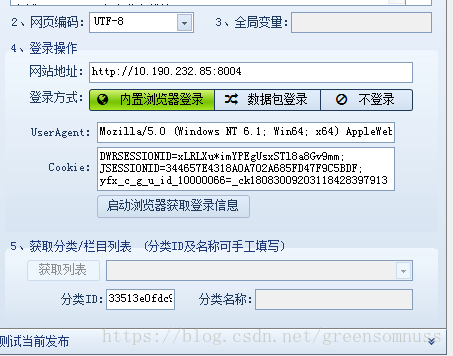
网站地址是指你需要发布数据起始地址
useragent可以使用fidder2 获取得到
cookie 也可以通过fidder2得到,同时也可以根据网站的f12检查得到,有些可能没有。
然后在右边建立一个发布的模块,这里的配置就是相当于要和数据库的字段相互对应,插入到数据库:
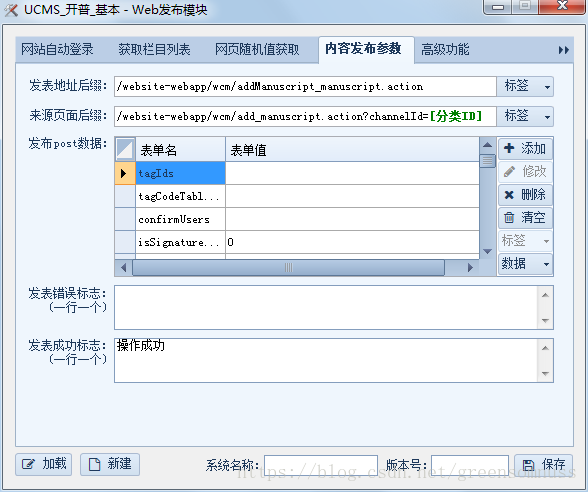
这里的发表地址是前面的地址加上你需要发布的地址的后缀,来源页面地址是指你需要发布在某个栏目下面配置的栏目id,也就是相当于一篇文章属于什么类型(文学,小说),这里的类型id。
发布的post数据:
post数据也可以根据fidder2获得。
后面会说明fidder2是怎么使用。