nvidia nvlink互联与nvswitch介绍
https://www.chiphell.com/thread-1851449-1-1.html
差不多在一个月前在年度gtc会议上,老黄公开了dgx-2,这台售价高达399k美元,重达350磅的怪兽是专门为了加速ai负载而研制的,他被授予了“世界最大的gpu”称号。为什么它被赋予这个名字,它又是如何产生的,我们需要把时间倒退到几年之前。
动机
在nvidia推出目前这个方案之前,为了获得更多的强力计算节点,多个GPU通过PCIe Switch直接与CPU相连。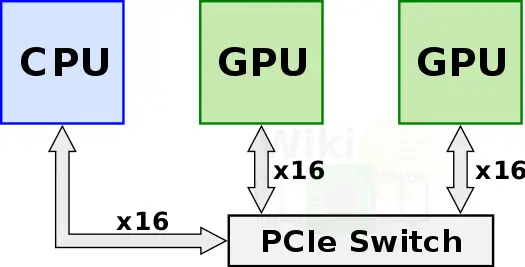
他们之间的pcie 3.0*16有接近32GB/s的双向带宽,但是当训练数据不停增长的时候,这个互联方案本身却成为了致命的系统瓶颈。如果不改进这个互联带宽,那么新时代GPU带来的额外性能就没法发挥出来,从而无法满足现实需求负载的增长。
NVLink
为了解决这个问题,nvidia开发了一个全新的互联构架nvlink。单条nvlink是一种双工双路信道,其通过组合32条配线,从而在每个方向上可以产生8对不同的配对(2bi*8pair*2wire=32wire),第一版的实现被称为nvlink 1.0,与P100 GPU一同发布。一块P100上,集成了4条nvlink。每条link具备双路共40GB/s的带宽,整个芯片具备整整160GB/s的带宽。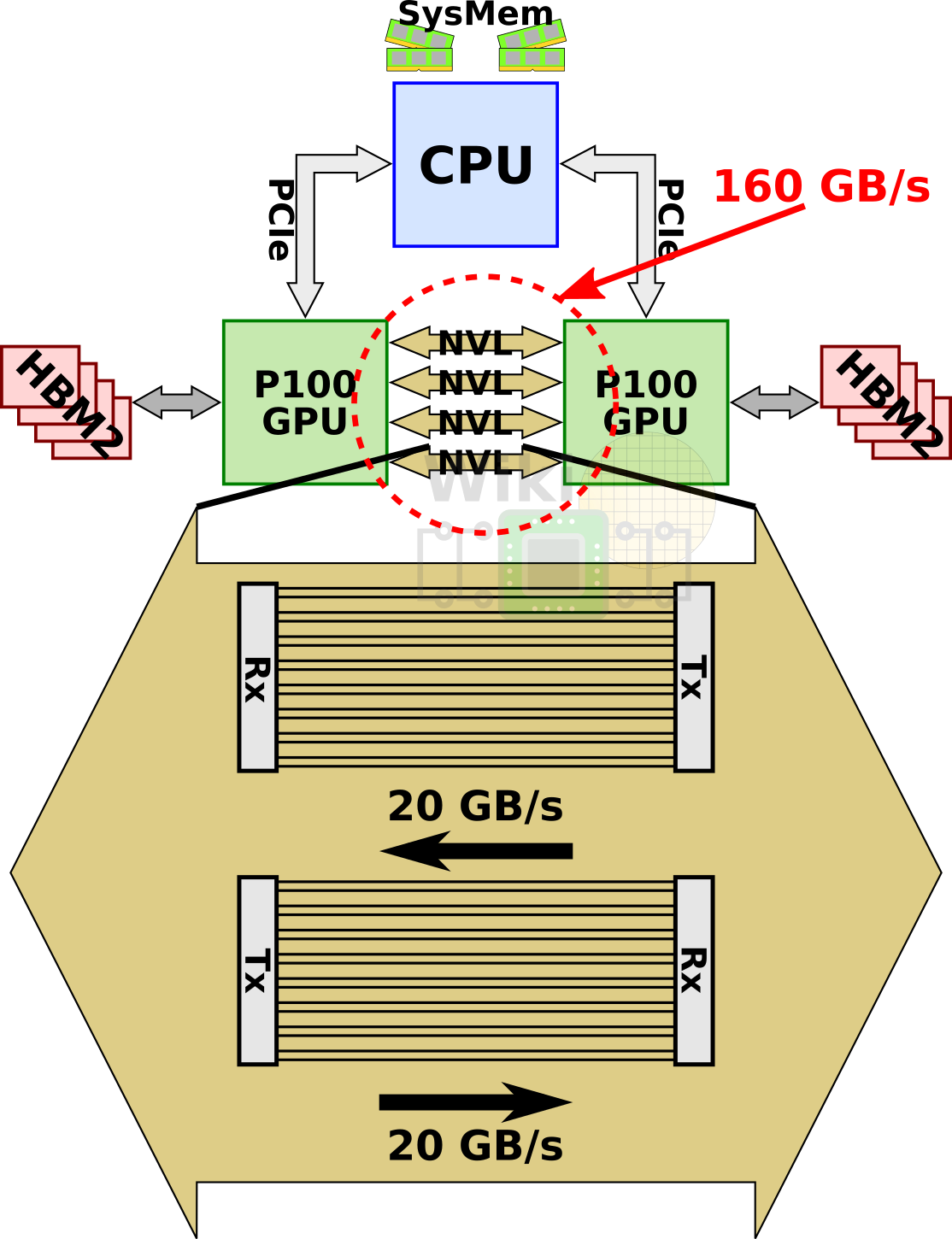
当然,nvlink不仅仅只是限定在GPU之间互联上。IBM将nvlink 1.0添加到他们基于Power8+微架构的Power处理器上,这一举措使得P100可以直接通过nvlink于CPU相连,而无需通过pcie。通过与最近的power8+ cpu相连,4GPU的节点可以配置成一种全连接的mesh结构。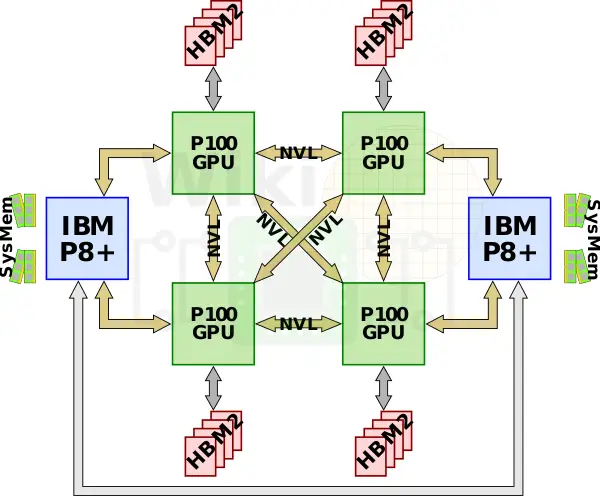
DGX-1
第一种nvidia专门为AI加速订制的机器叫做dgx1,它集成了八块p100与两块志强e5 2698v4,但是因为每块GPU只有4路nvlink,这些GPU构成了一种混合的cube-mesh网络拓扑结构,GPU被4块4块分为两组,然后在互相连接。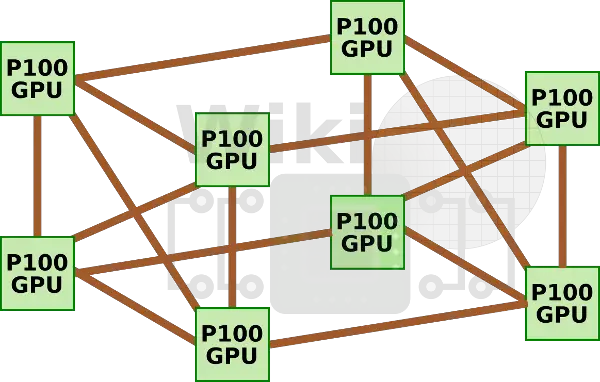
同时,因为GPU需要的pcie通道数量超过了芯片组所能提供的数量,所以每一对GPU将连接到一组pcie switch上与志强相连,然后两块志强再通过qpi总线连接。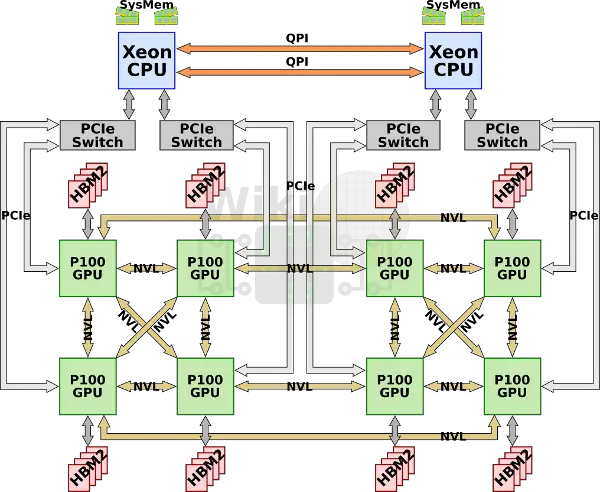
6块P100,每块16GB HBM2显存,总计128GB显存和512GB DDR4-2133系统内存。
nvlink 2.0
nvlink的第二个版本与gv100一同而来。IBM计划在Power9 cpu上给与支持。nvlink 2.0提升了信号的传输率,从20Gb/s到了25Gb/s,双信道总计50GB/s,pre nvlink。同时进一步提升了nvlink数到6路。这些举措让v100的总带宽从p100的160GB/s提升到了300GB/s。
顺便说下,除了带宽的增长,nvidia还添加了数个新的operational feature到协议本身。其中最有意思的一个特性是引入了coherency operation缓存一致性操作,它允许CPU在读取数据时缓存GPU显存信号,这将极大的降低访问延迟。
去年nvidia将原始dgx-1升级到v100架构。因为主要的cube-mesh拓扑结构并没有变化,所以多出来的link用来倍化一些GPU之间的互联。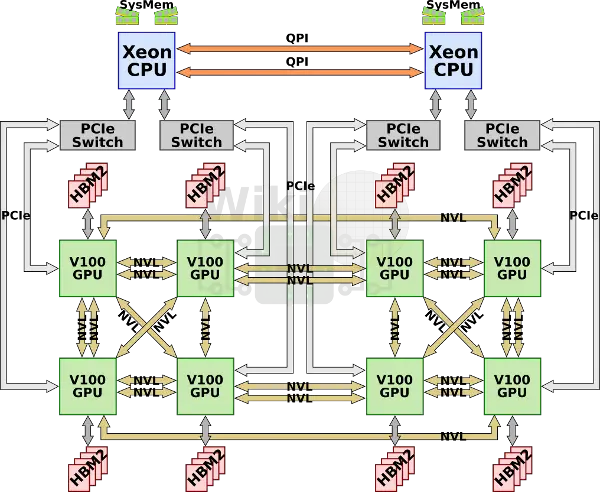

DGX-2
最近的GTC2018发布的dgx-2,其加倍了v100的数量,最终高达16块v100。同时hbm2升级到32GB/块,一共高达512GB,cpu升级为双路2.7G 24核 志强白金8168.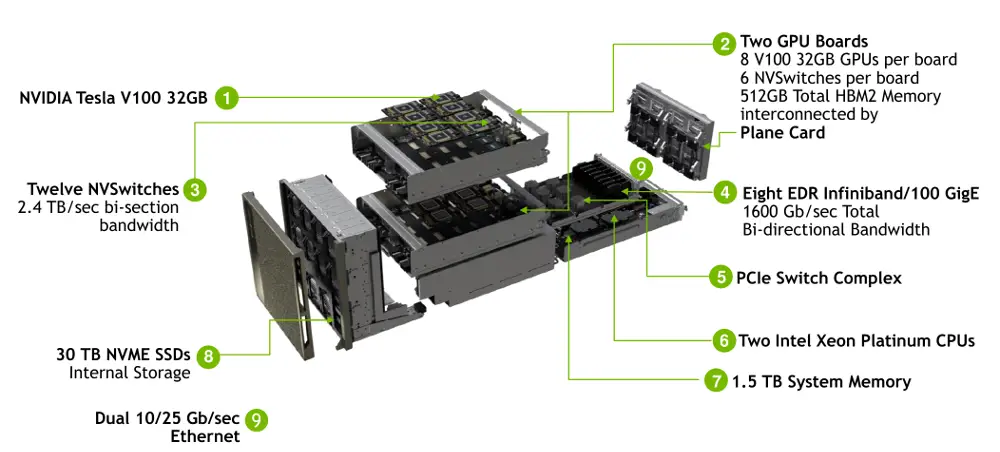
升级到16块GPU,对于系统而言也要做出巨大的改变,特别是更快更大的互联网络带宽。
NVSwitch
那么dgx-2中装载的是什么呢,是一块新的asic - nvswitch。nvswitch是一块独立的nvlink芯片,其提供了高达18路nvlink的接口。这块芯片据说已经开发了两年之久。其支持nvlink 2.0,也就意味着每个接口均能提供双信道高达50GB/s的带宽,那么这块芯片总计能够提供900GB/s的带宽。这块芯片功率100w,基于台积电12nm FinFet FFN nvidia订制工艺,来源于增强的16nm节点,拥有2b个晶体管。
这块die封装在1940个pin大小为4cm2的BGA芯片中,其中576个针脚专门服务于18路的nvlink,剩下的阵脚则用于电源,或者其他I/O接口,比如用于管理端口的x4 pcie,I2c,GPIO等等。
通过nvswitch提供的18路接口,nvswitch能够让nvidia设计出完全无阻塞的全互联16路GPU系统。每块v100中的6路nvlink将分别连接到6块nvswitch上面。这样8块v100与6块nvsiwtch完全连接,构成一个基板。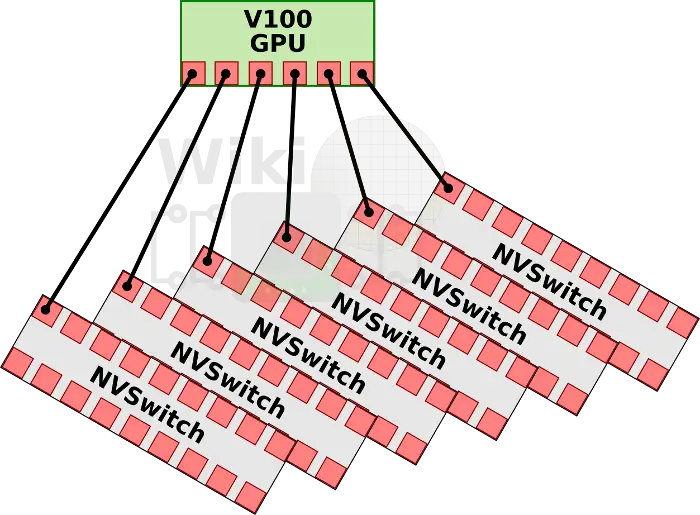
dgx2拥有两块基板,这两块基板则是通过nvswitch剩余的另一侧接口完全互联在一起,这就构成了一个16路全连接的GPU构架。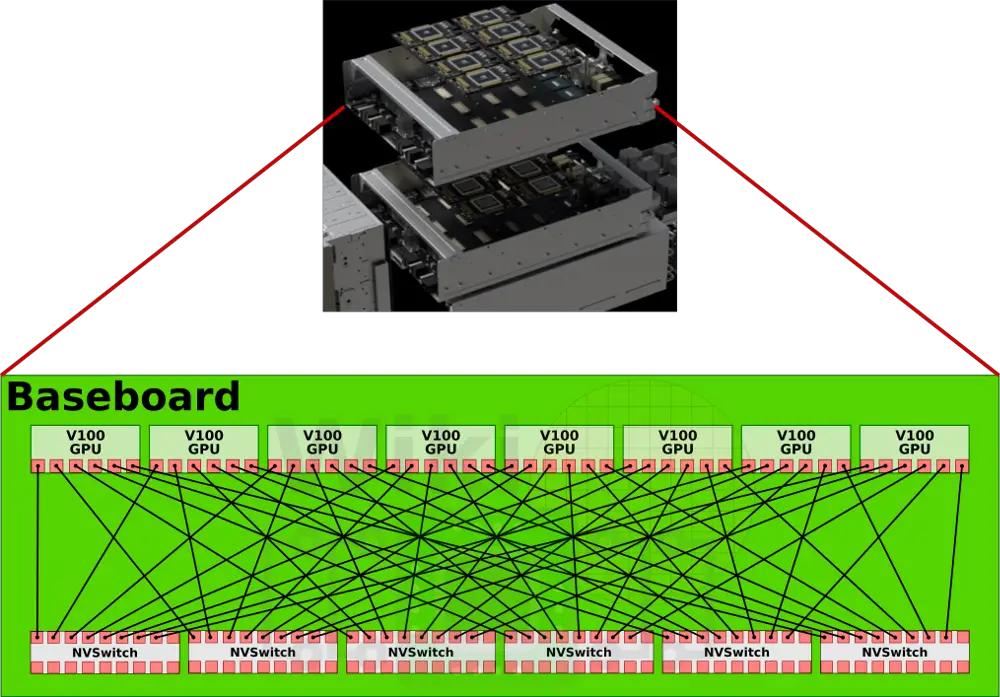
两块基板之间的nvswitch之间都有八路link互联,16块GPU每块有6路nvlink的情况下,其总双路带宽达到2400GB/s。有趣的是,其实nvswitch有18路接口nvidia却只用到了其中16路。一种可能性是nv留下两路用于支持ibm的power9处理器(dgx1和2都是用的志强)。在这个复杂的结构中,power9处理器可能分别接在两块基板的nvsiwtch上,这样GPU也与Power9处于全连接状态。如果CPU直接与nvswitch相连,那么pcie就不再担任cpu与gpu相连的责任。目前nvidia还没有向其他厂商开放nvswitch,如果他们决定开放,将会产生一些新型态的,可能更加规模庞大的结算节点。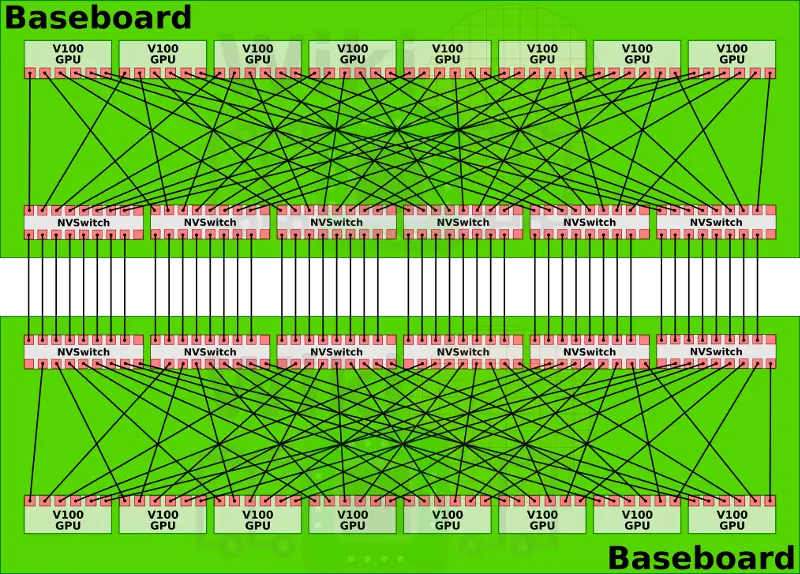
在原始的dgx-1中,执行GPU之间的事务处理需要一个额外的hop,这将导致远程访问的不一致性。在很多负载中,这会让利用统一寻址变得困难,产生了一些不确定性。在dgx2中,每一块gpu都可以于另外一块gpu以相同的速度和一致性延迟交流。大型的AI负载能够通过并行化的模型技术得到巨大的提升。回到GTC中,nvidia赋予的名称“世界最大的GPU”。在实践中,因为每块GPU和其他伙伴直接互联,统一寻址也变的简单有效。现在,可以合并512GiB高速带宽的显存,将他虚拟化成一块统一的内存。无论是GPU本身还是nvswitch都有相应的算法用于实现这一统一的内存系统。在程序层面,整台机器将会被当作一块GPU和一个整体的显存,这个显存子系统将会自行管理显存layout,提供最优化的组织架构。