目录
-
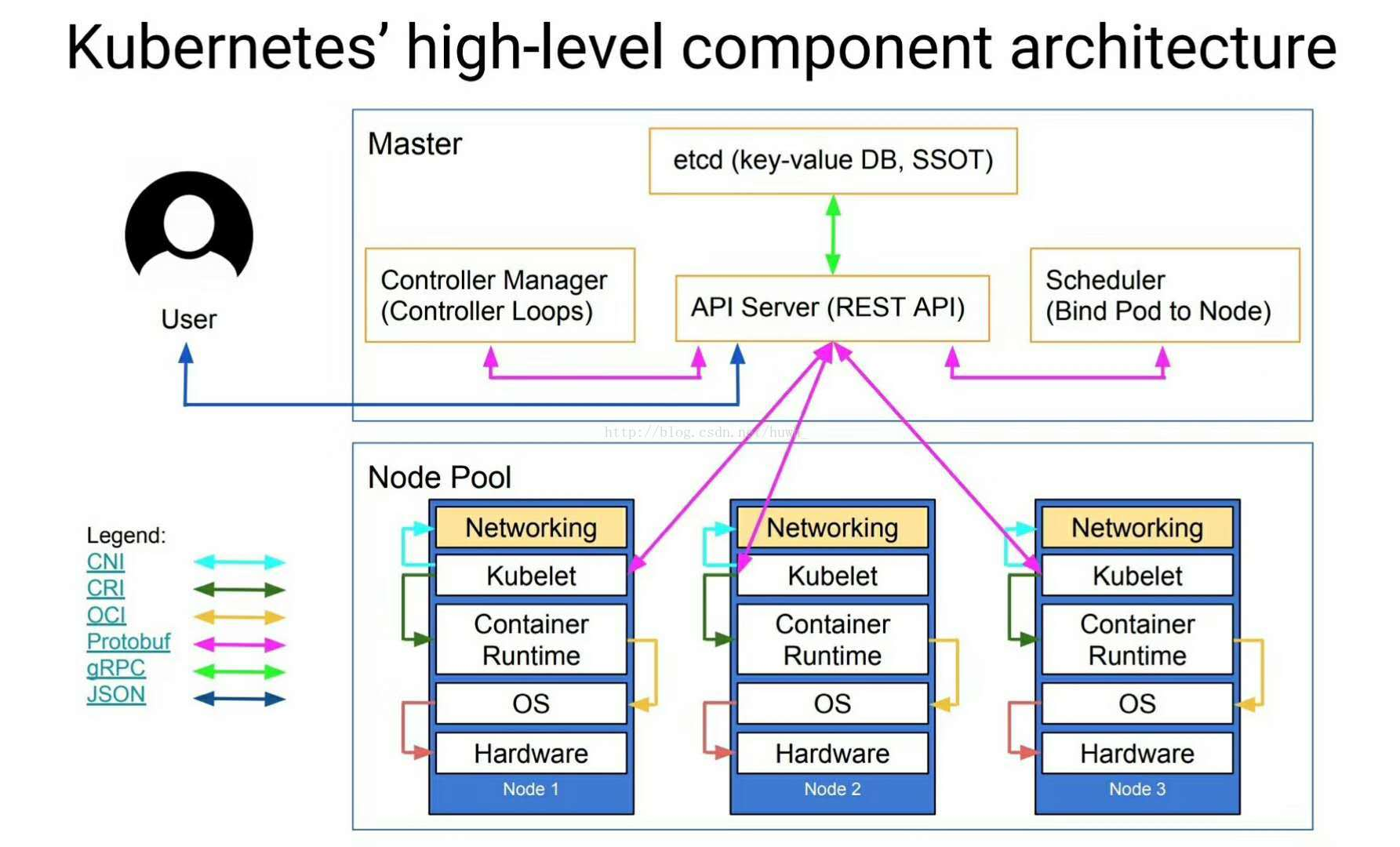
熟悉架构
-
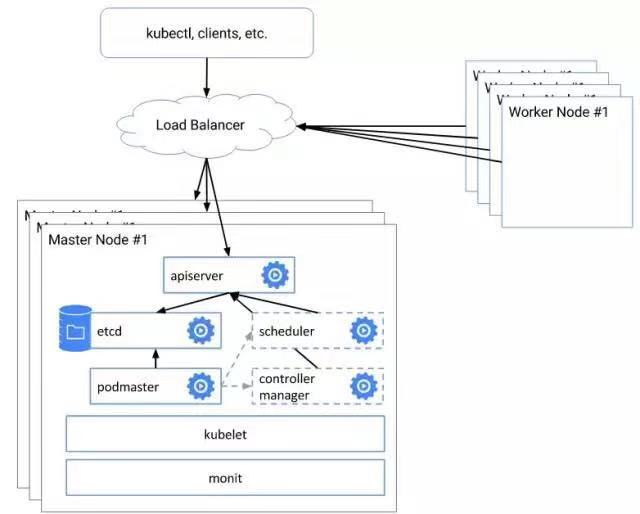
HA的架构
-
- 单master的集群结构
-
- 了解各组件的作用与基本命令
- etcd/kube-api/kube-controller/kube-scheduler/kube-proxy/kube-dns/kubelet/calico
- 当集群出现问题,我们会用一些命令或dashboard观察和获取到错误信息,有时dashboard也无法使用
- 参考:https://blog.csdn.net/huwh_/article/details/71308171
- https://www.kubernetes.org.cn/kubernetes%E8%AE%BE%E8%AE%A1%E6%9E%B6%E6%9E%84
-
-
常用命令:
- 基础网络 :
- iptables/nslookup/curl/tracerroute/route/ping/tcpdump/ss -nltp/ip a/等
- etcd集群状态:
- etcdctl --cert-file /etc/etcd/ssl/etcd.pem --key-file /etc/etcd/ssl/etcd-key.pem --ca-file /etc/etcd/ssl/ca.pem --endpoints https://$CP1_IP:2379cluster-health
- calico网络状态:
- calicoctl node status
- k8s服务与PODS状态:
- kubectl get pods --all-namespaces -o wide
- kubectl get svc --all-namespaces -o wide
- kubectl describe pods <PODNAME> -n <NAMESPACE>
- 容器状态与日志:
- docker ps -a |grep <KEY>
- docker logs <ContainerID>
- 基础网络 :
-
排查思路与顺序
-
基础网络-->etcd集群->api->calico网络->cubeDNS->基础组件->其它SVC与PODS
-
基础网络的故障,会导致etcd集群故障,etcd又会导致kube-apiserver故障,apiserver故障导致整个集群无法访问;
- 故障现象五花八门,同一种现象解决的办法不一定相同,不同的版本解决方法不一定相同;
- 在保证集群基础组件运行正常的前提下,容器的日志往往比较准确的反应问题的实质
- 经验+baidu/google/bing
-
-
-
故障现象
-
容器不断重启
-
dashboard无法打开
- 命令无法执行
- 网络不通
- 域名无法解析
- 。。。
-
-
常见故障例
-
安装时下载镜相类问题
-
问题: 下不到calico镜相,可以用阿里云转一下,master上4个全要下,node上只要node/cni
- # 阿里云镜相服务https://cr.console.aliyun.com/repository/
- docker pull registry.cn-zhangjiakou.aliyuncs.com/yanghaitao/myhub:3.2.3-1
- docker pull registry.cn-zhangjiakou.aliyuncs.com/yanghaitao/myhub:3.2.3-2
- docker pull registry.cn-zhangjiakou.aliyuncs.com/yanghaitao/myhub:3.2.3-3
- docker pull registry.cn-zhangjiakou.aliyuncs.com/yanghaitao/myhub:3.2.3-4
- docker tag registry.cn-zhangjiakou.aliyuncs.com/yanghaitao/myhub:3.2.3-1 quay.io/calico/kube-controllers:v3.2.3
- docker tag registry.cn-zhangjiakou.aliyuncs.com/yanghaitao/myhub:3.2.3-2 quay.io/calico/cni:v3.2.3
- docker tag registry.cn-zhangjiakou.aliyuncs.com/yanghaitao/myhub:3.2.3-3 quay.io/calico/node:v3.2.3
- docker tag registry.cn-zhangjiakou.aliyuncs.com/yanghaitao/myhub:3.2.3-4 quay.io/coreos/etcd:v3.3.9
-
- 权限类问题
- kubectl 使用$HOME/.kube/config(即/etc/kubernetes/admin.conf)的配置来访问集群
- 网络类问题
- 问题一:calico 网络问题:
- 现象:像单master安装时一样apply后,发现calico node一直不正常,重启,coredns也是;
- 查询原因:查calico-etcd有三个,member list只有一个,官网只有单master的介绍,etcd.yaml是个daemonset, 会在每个master上启一个etcd pod, 可导致calico etcd的服务不正常, 连锁反应是calico node/coredns/dashboard等都不正常;
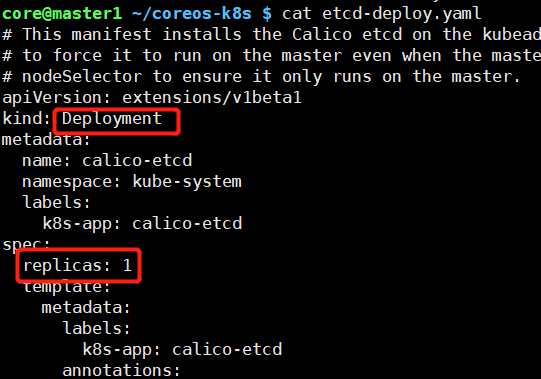
- 解决方法一:
- 把calico etcd的daemonset 改为deployment, replicas 设为1
-
- 方法二:
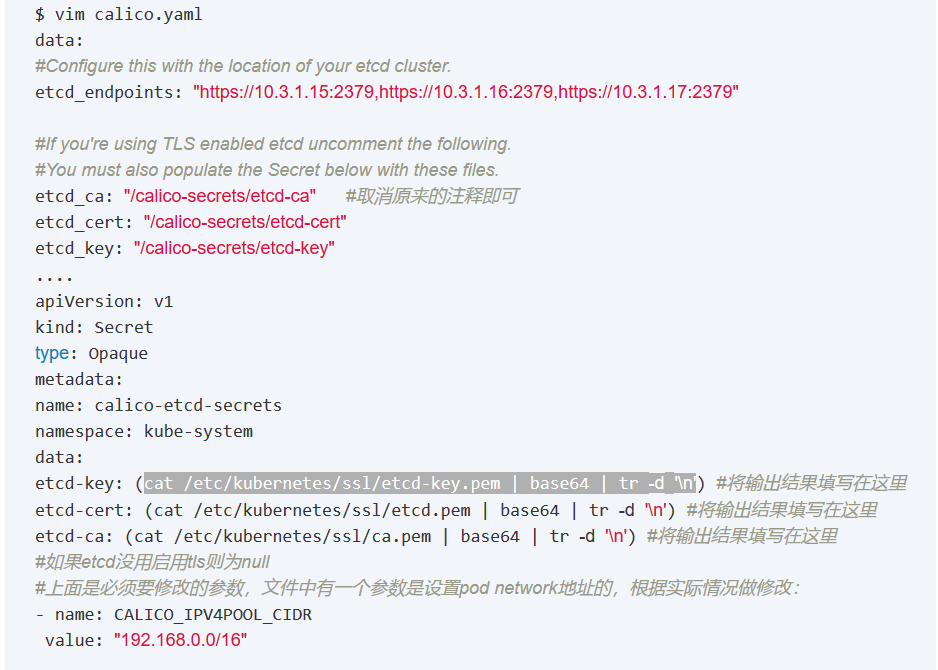
- 把etcd的指向到kubernetes集群的etcd上去,configmap里配置好ca验证
- 参考:http://blog.51cto.com/newfly/2085836
-
- 方法三:
- 用打标签的方法让calico etcd只运行在指定的master上,临时解决方法,没法高可用;
- 改etcd.yaml, nodeselector, =master1
- kubectl label nodes master1 node-role.kubernetes.io/master=master1--overwrite
- reboot所有结点或删除重启calico相关pods
- 用打标签的方法让calico etcd只运行在指定的master上,临时解决方法,没法高可用;
- 问题二:kubeadm init 后,无coredns/kube-proxy的pods出现:
- 调通外部网络
- 问题一:calico 网络问题:
- 其它问题:
- 问题三:k8s集群kubeadm的官方介绍方法有两种:
- 方法一是使用k8s自身的etcd,安装起来速度慢,常出现莫名的故障;
- 方法二即自建外部etcd的方法,速度快且稳定,install.sh采用此方法;
- 问题四:重新安装
- 先执行 sh install.sh reset
- 问题五:etcd备份
- etcd集群数据:/var/lib/etcd
- calico etcd数据: /var/etcd
- 问题三:k8s集群kubeadm的官方介绍方法有两种:
-
-
参考:
- https://www.jianshu.com/p/593c53dbdf7b
- http://dockone.io/article/2247
- http://dockone.io/article/2268
- https://blog.csdn.net/huwh_/article/details/71308301
- https://blog.csdn.net/luckytanggu/article/details/68926330
- https://blog.csdn.net/ljx1528/article/details/81437106
- https://www.kubernetes.org.cn/kubernetes%E8%AE%BE%E8%AE%A1%E6%9E%B6%E6%9E%84
往期链接:
进入公众号 -> 输入help或index

Linux命令速查,如lsof