主要分析Linux伙伴系统算法,内存的分配和释放
1.伙伴系统简介
Linux内核内存管理的一项重要工作就是如何在频繁申请释放内存的情况下,避免碎片的产生,
Linux采用伙伴系统解决外部碎片的问题,采用slab解决内 部碎片的问题.
伙伴算法(Buddy system)把所有的空闲页框分为11个块链表,每块链表中分布包含特定的连续页框地址空间,比如第0个块链表包含大小为2^0个连续的页框,第1个块链表中,每个链表元素包含2个页框大小的连续地址空间,….,第10个块链表中,每个链表元素代表4M的连续地址空间。每个链表中元素的个数在系统初始化时决定,在执行过程中,动态变化。伙伴算法每次只能分配2的幂次页的空间,比如一次分配1页,2页,4页,8页,…,1024页(2^10)等等,每页大小一般为4K,因此,伙伴算法最多一次能够分配4M的内存空间。
1.1.1 关键数据结构
struct zone {
struct free_area free_area[MAX_ORDER];
}
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
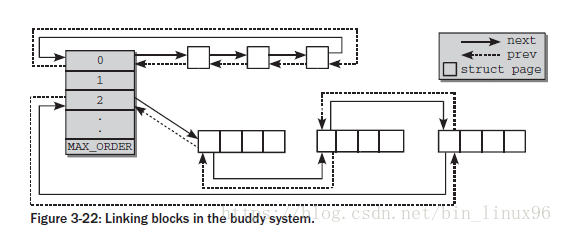
free_area共有MAX_ORDER个元素,其中第order个元素记录了2^order的空闲块,这些空闲块在free_list中以双向链表的形式组织起来,对于同等大小的空闲块,其类型不同,将组织在不同的free_list中,nr_free记录了该free_area中总共的空闲内存块的数量。MAX_ORDER的默认值为11,这意味着最大内存块的大小为2^10=1024个页框。对于同等大小的内存块,每个内存块的起始页框用于链表的节点进行相连,这些节点对应的着struct page中的lru域
struct page {
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone->lru_lock !
*/
}
1.1.2 迁移类型
不可移动页(Non-movable pages):这类页在内存当中有固定的位置,不能移动。内核的核心分配的内存大多属于这种类型
可回收页(Reclaimable pages):这类页不能直接移动,但可以删除,其内容页可以从其他地方重新生成,例如,映射自文件的数据属于这种类型,针对这种页,内核有专门的页面回收处理
可移动页:这类页可以随意移动,用户空间应用程序所用到的页属于该类别。它们通过页表来映射,如果他们复制到新的位置,页表项也会相应的更新,应用程序不会注意到任何改变。
当一个指定的迁移类型所对应的链表中没有空闲块时,将会按以下定义的顺序到其他迁移类型的链表中寻找
static int fallbacks[MIGRATE_TYPES][MIGRATE_TYPES-1] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_RESERVE },
[MIGRATE_RESERVE] = { MIGRATE_RESERVE, MIGRATE_RESERVE, MIGRATE_RESERVE }, /* Never used */
};

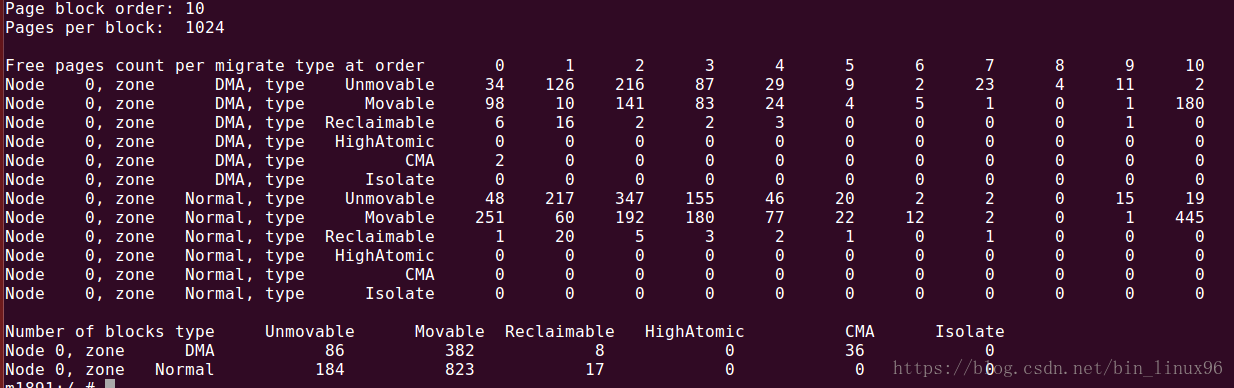
通过cat /proc/pagetypeinfo可以看到迁移类型和order的关系
1.2 内存的分配
分配函数为alloc_pages,最终调用到__alloc_pages_nodemask
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist, nodemask_t *nodemask)
{
struct zoneref *preferred_zoneref;
struct page *page = NULL;
unsigned int cpuset_mems_cookie;
int alloc_flags = ALLOC_WMARK_LOW|ALLOC_CPUSET|ALLOC_FAIR;
gfp_t alloc_mask; /* The gfp_t that was actually used for allocation */
struct alloc_context ac = {
/*根据gfp_mask,找到合适的zone idx和migrate类型 */
.high_zoneidx = gfp_zone(gfp_mask),
.nodemask = nodemask,
.migratetype = gfpflags_to_migratetype(gfp_mask),
};
retry_cpuset:
cpuset_mems_cookie = read_mems_allowed_begin();
/* We set it here, as __alloc_pages_slowpath might have changed it */
ac.zonelist = zonelist;
/* Dirty zone balancing only done in the fast path */
ac.spread_dirty_pages = (gfp_mask & __GFP_WRITE);
/*根据分配掩码,确认先从哪个zone分配 */
/* The preferred zone is used for statistics later */
preferred_zoneref = first_zones_zonelist(ac.zonelist, ac.high_zoneidx,
ac.nodemask ? : &cpuset_current_mems_allowed,
&ac.preferred_zone);
if (!ac.preferred_zone)
goto out;
ac.classzone_idx = zonelist_zone_idx(preferred_zoneref);
/* First allocation attempt */
alloc_mask = gfp_mask|__GFP_HARDWALL;
/*快速分配 */
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (unlikely(!page)) {
/*慢速分配,涉及到内存回收,暂不分析 */
page = __alloc_pages_slowpath(alloc_mask, order, &ac);
}
out:
if (unlikely(!page && read_mems_allowed_retry(cpuset_mems_cookie)))
goto retry_cpuset;
return page;
}1.2.1 水位控制
每个zone有三个水位(watermark),用以标识系统内存存量,由数组 watermark[NR_WMARK]表示.
WMARK_MIN,WMARK_LOW,WMARK_HIGH,当内存存量低于对应水位时,就会调用zone_reclaim()进行内存回收.
mark = zone->watermark[alloc_flags & ALLOC_WMARK_MASK];
if (!zone_watermark_ok(zone, order, mark,//判断水位是否正常
ac->classzone_idx, alloc_flags)) {
ret = zone_reclaim(zone, gfp_mask, order);
}
1.2.2 单个页面的分配
get_page_from_freelist->buffered_rmqueue:
order=0时,单个页面直接从per cpu的free list分配,这样效率最高.
if (likely(order == 0)) {
struct per_cpu_pages *pcp;
struct list_head *list;
local_irq_save(flags);
pcp = &this_cpu_ptr(zone->pageset)->pcp;
list = &pcp->lists[migratetype];
/*如果对应list为空,则从伙伴系统拿内存*/
if (list_empty(list)) {
pcp->count += rmqueue_bulk(zone, 0,
pcp->batch, list,
migratetype, gfp_flags);
if (unlikely(list_empty(list)))
goto failed;
}
/*分配一个页面 */
if ((gfp_flags & __GFP_COLD) != 0)
page = list_entry(list->prev, struct page, lru);
else
page = list_entry(list->next, struct page, lru);
if (!(gfp_flags & __GFP_CMA) &&
is_migrate_cma(get_pcppage_migratetype(page))) {
page = NULL;
local_irq_restore(flags);
} else {
list_del(&page->lru);
pcp->count--;
}
}1.2.3 多个页面的分配(order>1)
get_page_from_freelist->buffered_rmqueue->__rmqueue:
static struct page *__rmqueue(struct zone *zone, unsigned int order,
int migratetype, gfp_t gfp_flags)
{
struct page *page = NULL;
/*CMA内存的分配 */
if ((migratetype == MIGRATE_MOVABLE) && (gfp_flags & __GFP_CMA))
page = __rmqueue_cma_fallback(zone, order);
if (!page)/*根据order和migrate type找到对应的freelist分配内存 */
page = __rmqueue_smallest(zone, order, migratetype);
if (unlikely(!page))/*当对应的migrate type无法满足order分配时,进行fallback规则分配
,分配规则定义在fallbacks数组中。 */
page = __rmqueue_fallback(zone, order, migratetype);
return page;
}
这里分析migrate type能够满足内存分配的情况
static inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* 根据order,逐级向上查找*/
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
if (list_empty(&area->free_list[migratetype]))
continue;
page = list_entry(area->free_list[migratetype].next,
struct page, lru);
list_del(&page->lru);
rmv_page_order(page);
area->nr_free--;
/* 切蛋糕,如果current_order大于目标order,则要把多余的内存挂到对应的order链表.*/
expand(zone, page, order, current_order, area, migratetype);
set_pcppage_migratetype(page, migratetype);
return page;
}
return NULL;
}
static inline void expand(struct zone *zone, struct page *page,
int low, int high, struct free_area *area,
int migratetype)
{
unsigned long size = 1 << high;//先一分为2
while (high > low) {
area--;/* 回退到下一级链表*/
high--;
size >>= 1;/*Size减半 */
/*接入下一级空闲链表 */
list_add(&page[size].lru, &area->free_list[migratetype]);
area->nr_free++;
set_page_order(&page[size], high);
}
}1.2.4 fallback分配
当前migrate type不能满足内存分配需求时,需要到其他migrate type空闲链表分配内存.
规则如下:
static int fallbacks[MIGRATE_TYPES][4] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
#ifdef CONFIG_CMA
[MIGRATE_CMA] = { MIGRATE_TYPES }, /* Never used */
#endif
#ifdef CONFIG_MEMORY_ISOLATION
[MIGRATE_ISOLATE] = { MIGRATE_TYPES }, /* Never used */
#endif
};
__rmqueue_fallback(struct zone *zone, unsigned int order, int start_migratetype)
{
struct free_area *area;
unsigned int current_order;
struct page *page;
int fallback_mt;
bool can_steal;
/* 先从最大的order list中找到合适的块 */
for (current_order = MAX_ORDER-1;
current_order >= order && current_order <= MAX_ORDER-1;
--current_order) {
area = &(zone->free_area[current_order]);
/*从fallbacks数组中找到合适的migrate type链表 */
fallback_mt = find_suitable_fallback(area, current_order,
start_migratetype, false, &can_steal);
if (fallback_mt == -1)
continue;
page = list_entry(area->free_list[fallback_mt].next,
struct page, lru);
if (can_steal &&/*改变pageblock的migrate type */
get_pageblock_migratetype(page) != MIGRATE_HIGHATOMIC)
steal_suitable_fallback(zone, page, start_migratetype);
/* Remove the page from the freelists */
area->nr_free--;
list_del(&page->lru);
rmv_page_order(page);
/*切蛋糕 */
expand(zone, page, order, current_order, area,
start_migratetype);
set_pcppage_migratetype(page, start_migratetype);
trace_mm_page_alloc_extfrag(page, order, current_order,
start_migratetype, fallback_mt);
return page;
}
return NULL;
}
如UNMOVABLE链表内存不足时,优先从RECLAIMABLE链表分配,再从MOVABLE链表分配
1.3 内存的释放
页面的释放,最终调用到__free_one_page函数.
首先两块内存是伙伴块,必须满足以下条件:
1. 伙伴不能在空洞页面中,要有实实在在的物理页面/the buddy is not in a hole/
2. 伙伴块在伙伴系统中,也就是伙伴块要是空闲的,没有被分配出去的内存块/the buddy is in the buddy system/
3. 要有相同的order /a page and its buddy have the same order/
4. 位于同一个zone./a page and its buddy are in the same zone/
5. 物理上要相连.且两个page的起始pfn号一定相差2^order,则有计算公式B2 = B1 ^ (1 << O)
static inline unsigned long
__find_buddy_index(unsigned long page_idx, unsigned int order)
{
return page_idx ^ (1 << order);//计算buddy page的index
}
static inline void __free_one_page(struct page *page,
unsigned long pfn,
struct zone *zone, unsigned int order,
int migratetype)
{
unsigned long page_idx;
unsigned long combined_idx;
unsigned long uninitialized_var(buddy_idx);
struct page *buddy;
unsigned int max_order;
max_order = min_t(unsigned int, MAX_ORDER, pageblock_order + 1);
/*计算page_idx, */
page_idx = pfn & ((1 << MAX_ORDER) - 1);
VM_BUG_ON_PAGE(page_idx & ((1 << order) - 1), page);
VM_BUG_ON_PAGE(bad_range(zone, page), page);
continue_merging:
while (order < max_order - 1) {
/*找到buddy ix */
buddy_idx = __find_buddy_index(page_idx, order);
buddy = page + (buddy_idx - page_idx);
/*判断是否是伙伴块 */
if (!page_is_buddy(page, buddy, order))
goto done_merging;
/*
* Our buddy is free or it is CONFIG_DEBUG_PAGEALLOC guard page,
* merge with it and move up one order.
*/
if (page_is_guard(buddy)) {
clear_page_guard(zone, buddy, order, migratetype);
} else {
list_del(&buddy->lru);
zone->free_area[order].nr_free--;
rmv_page_order(buddy);
}
/*继续向上合并 */
combined_idx = buddy_idx & page_idx;
page = page + (combined_idx - page_idx);
page_idx = combined_idx;
order++;
}
done_merging:
set_page_order(page, order);
/*
* If this is not the largest possible page, check if the buddy
* of the next-highest order is free. If it is, it's possible
* that pages are being freed that will coalesce soon. In case,
* that is happening, add the free page to the tail of the list
* so it's less likely to be used soon and more likely to be merged
* as a higher order page
*/
if ((order < MAX_ORDER-2) && pfn_valid_within(page_to_pfn(buddy))) {
struct page *higher_page, *higher_buddy;
/*这里检查更上一级是否存在伙伴关系,如果是的,则把page添加到链表末尾,这样有利于页面回收. */
combined_idx = buddy_idx & page_idx;
higher_page = page + (combined_idx - page_idx);
buddy_idx = __find_buddy_index(combined_idx, order + 1);
higher_buddy = higher_page + (buddy_idx - combined_idx);
if (page_is_buddy(higher_page, higher_buddy, order + 1)) {
list_add_tail(&page->lru,
&zone->free_area[order].free_list[migratetype]);
goto out;
}
}
/*链接到对应的free list 链表 */
list_add(&page->lru, &zone->free_area[order].free_list[migratetype]);
out:
zone->free_area[order].nr_free++;
}