*2.1 经验评估与选择*
关键字:
错误率、精度、误差、、训练误差(经验误差)、泛化误差、
关键概念解释:
1.欠拟合解决方案:决策学习树中扩展分支、增加训练轮数
关键字:
错误率、精度、误差、、训练误差(经验误差)、泛化误差、
关键概念解释:
1.欠拟合解决方案:决策学习树中扩展分支、增加训练轮数
*2.2 评估方法*
关键字:
测试集、留出法、交叉验证法(K折交叉验证)、自助法、参数调节
关键概念解释:
1.测试集应该尽可能与训练集互斥
2.留出法:直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T
3.交叉验证法:先将数聚集D划分为K个大小相似的互斥子集,每个子集尽可能保持数据分布的一致性。然后每次用k-1个子集作为训练集,剩下的那个子集作为测试集。
4.自助法:自助采样m次每次都放会,得到训练集D^,D-D^做测试集。
5. 参数调节:对每种参数配置都训练出模型,然后把对应最好地模型的参数作为结果
2.2.1 留出法
注意事项:
1.训练/测试集的划分要尽可能保持数据分布的一致性,采用分层采样
2.采用若干次随机划分,重复实验评估后取平均值作为留出法的评估结果
3.训练集数据不多不少,一般取 2/3~4/5
注意事项:
1.训练/测试集的划分要尽可能保持数据分布的一致性,采用分层采样
2.采用若干次随机划分,重复实验评估后取平均值作为留出法的评估结果
3.训练集数据不多不少,一般取 2/3~4/5
2.2.2 交叉验证法
注意事项:
1.将数据集划分为K个子集同样存在多种划分方式,为减少误差,重复多次划分取平均
2.留一法:每个子集一个样本,较准确,但是数据量大时开销太大
注意事项:
1.将数据集划分为K个子集同样存在多种划分方式,为减少误差,重复多次划分取平均
2.留一法:每个子集一个样本,较准确,但是数据量大时开销太大
2.2.3 自助法
注意事项:
1.初始训练集中约有36.8%未出现在最终采样中,用作测试集,称为包外估计。
2.适于数聚集较小时,但是改变了初始数聚集地分布
注意事项:
1.初始训练集中约有36.8%未出现在最终采样中,用作测试集,称为包外估计。
2.适于数聚集较小时,但是改变了初始数聚集地分布
2.2.4 调参与最终模型
注意事项:
1.模型评估与选择中用于评估测试的数聚集常称为验证集,学得模型在实际使用中遇到的数据称为测试数据。用测试集判定泛化能力,把训练数据划分为训练集和验证集,给予验证集上的性能来进行模型选择与调参。
注意事项:
1.模型评估与选择中用于评估测试的数聚集常称为验证集,学得模型在实际使用中遇到的数据称为测试数据。用测试集判定泛化能力,把训练数据划分为训练集和验证集,给予验证集上的性能来进行模型选择与调参。
2.3 性能度量
关键字:
查准率、查全率、PR曲线、均方误差、 错误率、精度、平衡点(BEP)、F1、Fβ、宏系列、微系列、ROC、AUC、损失、非均等代价、代价敏感错误率、代价曲线
对于给定样例集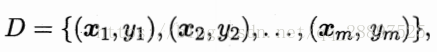
均方误差:
离散:
对于给定样例集
均方误差:
离散:
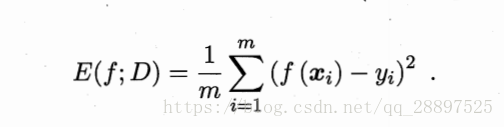
连续:
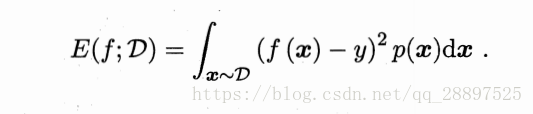
2.3.1 错误率与精度
分类错误率:
离散:
分类错误率:
离散:
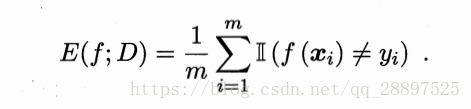
连续:
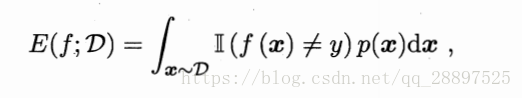
精度:
离散:
离散:
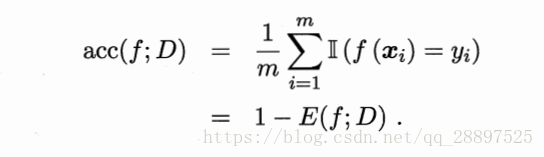
连续:
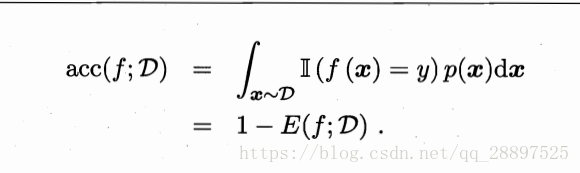
2.3.2 查准率、查全率
对于二分问题,可将样例根据真是类别与学习器预测类别的组合划分为真正例(TP),假正例(FP),真反例(TN),假反(FN)
查准率:

查全率:

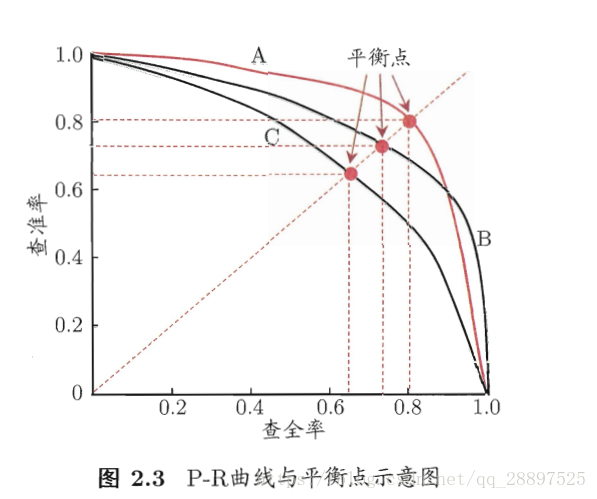
查准率和查全率是一对矛盾的度量
注意事项:
1.RP曲线中若一个学习器曲线被另一个学习器完全包住,则可断言后者更佳,一般通过比较曲线下的面积来比较性能
1.RP曲线中若一个学习器曲线被另一个学习器完全包住,则可断言后者更佳,一般通过比较曲线下的面积来比较性能
2.性能度量:BEP、F1、Fβ、宏系列、微系列
BER:P=R
F1:

Fβ:
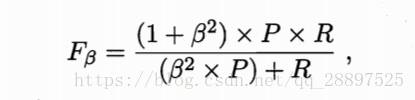
β>1查全率更重要,反之查准率影响更大
宏系列:在各混淆矩阵上分别计算出查准率和查全率
宏系列:在各混淆矩阵上分别计算出查准率和查全率
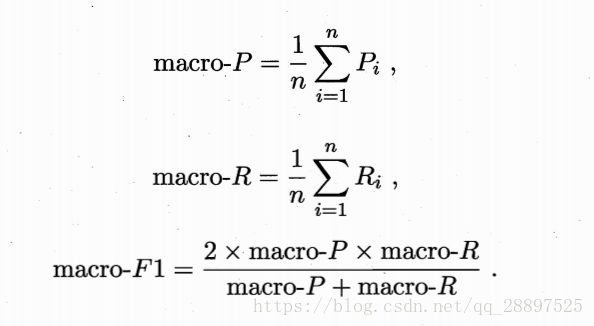
微系列:将各混淆矩阵的对应元素进行平均

2.3.3 ROC与AUC
tips:
1.ROC(受试者工作特征):真正例率(TPR)为纵轴,假正例率(FPR)为横轴
TPR:
tips:
1.ROC(受试者工作特征):真正例率(TPR)为纵轴,假正例率(FPR)为横轴
TPR:
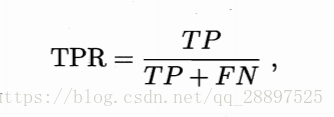
FPR:
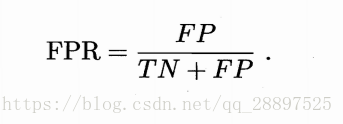
2.ROC曲线:
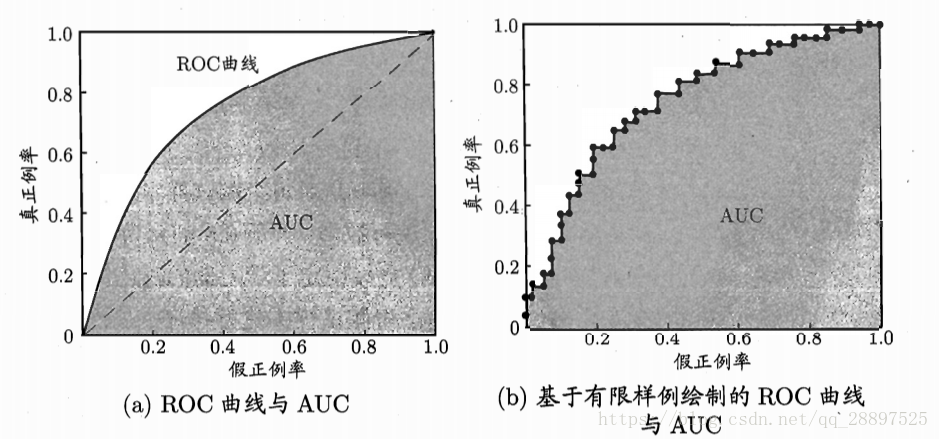
(0,1)对应于将所有正例排在所有反例之前的理想模型;
(0,0)对应于把所有样例均预测为反例
ROC曲线下的面积,即AUC来比较优劣
AUC:
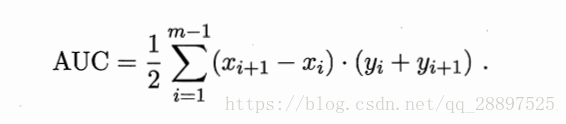
损失:图像上面的面积
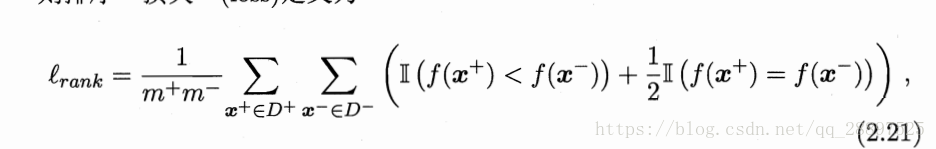
AUC=1-lrank
2.3.4 代价敏感错误率与代价曲线
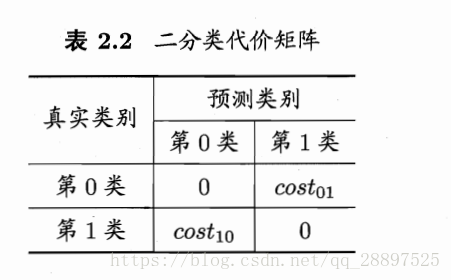
tips:
代价敏感错误率:
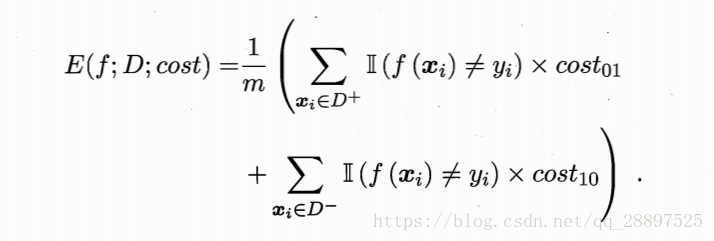
代价曲线:
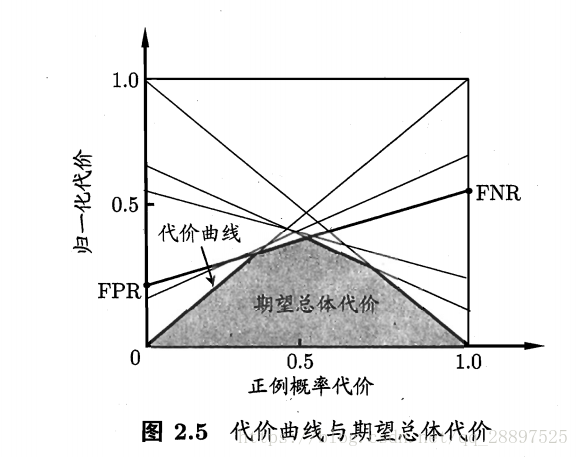
横轴为正例概率代价:
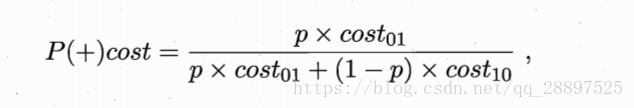
纵轴为归一化代价:
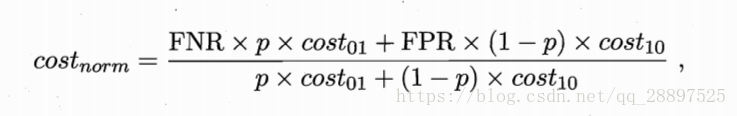
绘制方式:ROC曲线上每一点对应了代价平面上的一条线段,(0,FPR)连接(1,FNR) FNR=1-TPR。
图像几何意义:线段下的面积代表了该条件下的期望总代价,所有线段下界围成的面积即为所有条件下学习器的期望总体代价。
图像几何意义:线段下的面积代表了该条件下的期望总代价,所有线段下界围成的面积即为所有条件下学习器的期望总体代价。
2.4 比较检验
关键字:统计假设检验
关键字:统计假设检验
2.4.1
1.假设检验中的假设是对学习器泛化错误率分布的某种判断或猜想
2.泛化错误率为ε的学习器被测为ε()的概率:
1.假设检验中的假设是对学习器泛化错误率分布的某种判断或猜想
2.泛化错误率为ε的学习器被测为ε()的概率:
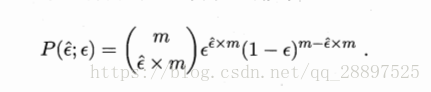
3.二项检验、置信度
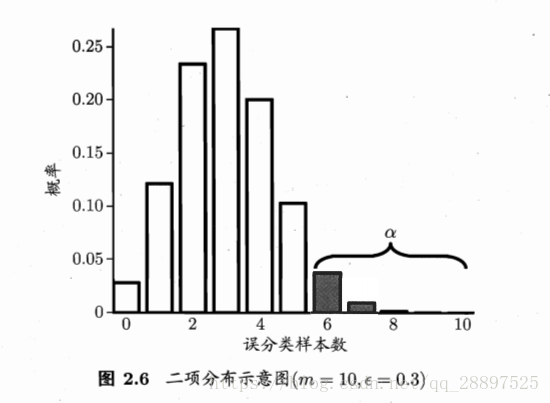
4.若测试错误率小于临界值,即能够以1-α的置信度认为,学习器的泛化错误率不大于ε0,否则拒绝假设。
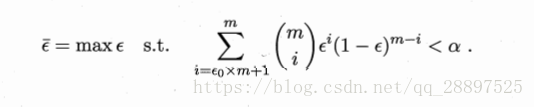
5.通过t检验来多次重复留出法
平均测试错误率和方差
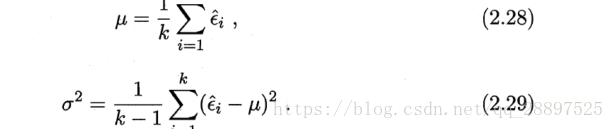
那么:
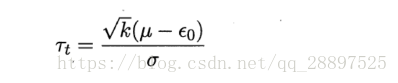
服从自由度为k-1的t分布
双边假设
2.4.2 交叉验证t检验
1.对不同学习器的性能进行对比,利用k折交叉检验“成对t检验”,若性能相同,使得k对测试错误率来做t检验
2.假设检验前提是测试错误率为泛化错误率的独立样本,然而不一定独立而有重叠,那么使用5*2交叉验证法

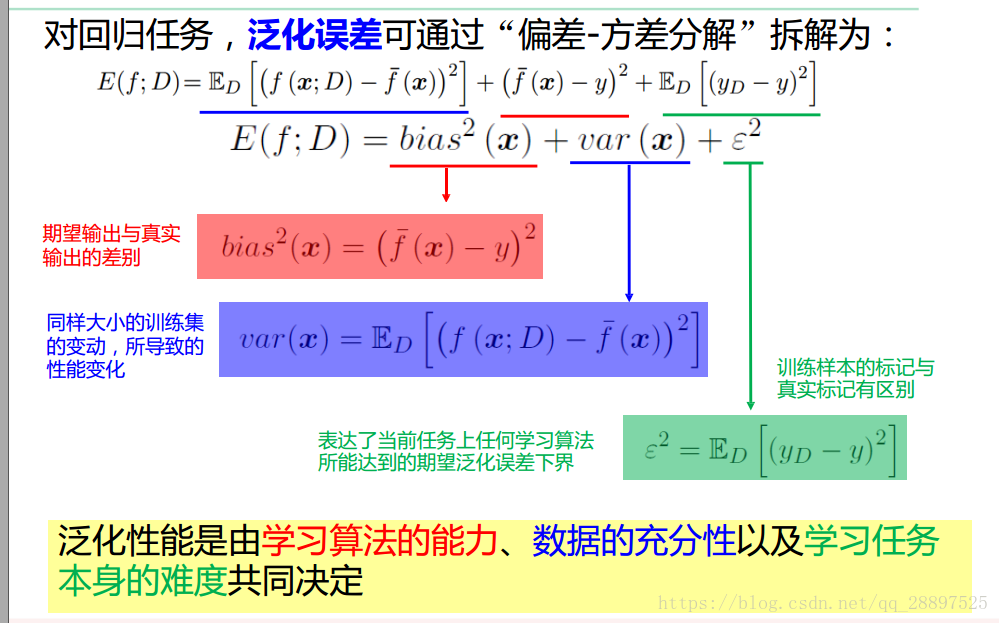
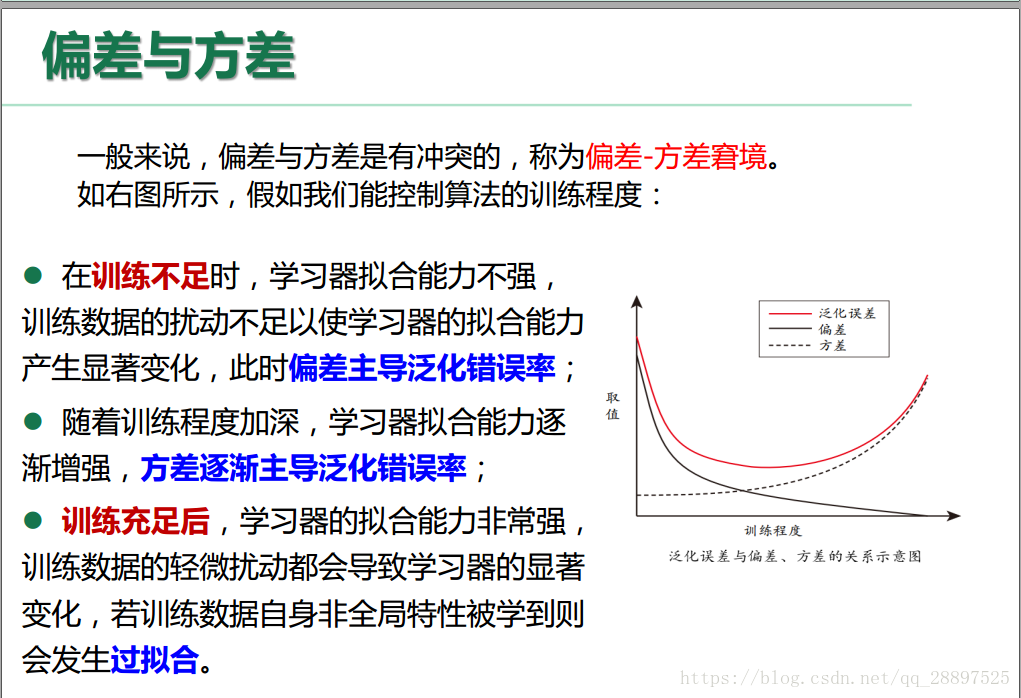
2.5 偏差与方差
1.偏差-方差分解是解释学习算法泛化性能的一种工具
期望输出与真实标记的差别称为偏差,对泛化误差可分解为: