一、Linux 调度器
Linux中进程调度器已经经过很多次改进了,目前核心调度器是在CFS(Completely Fair Scheduler),从2.6.23开始被作为默认调度器。用作者Ingo Molnar的话讲,CFS在真实的硬件上模拟了完全理想的多任务处理器。也就是说CFS试图仿真CPU。理想、精确的多任务CPU是一个可以同时并行执行多个进程的硬件CPU,给每个进程分配等量的处理器功率(并非时间)。如果只有一个进程执行,那么它将获得100%的处理器功率,两个进程就是50%,依次平均分配。这样就可以实现所有进程公平执行。
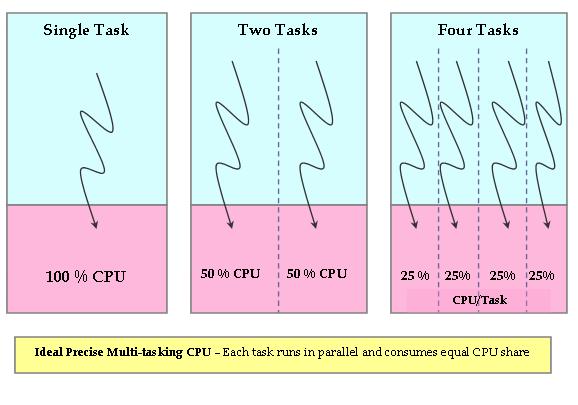
显然这样的理想CPU是不存在的,CFS调度器试图通过软件方式去模拟出这样的CPU来。在真实处理器上,同一时间只能有一个进程被调度执行,因此其他进程必须等待。因此当前执行的进程将会获得100%的CPU功率,其他等待的进程无法获得CPU功率,这样的分配显然是违背之前的初衷的,没有公平可言。
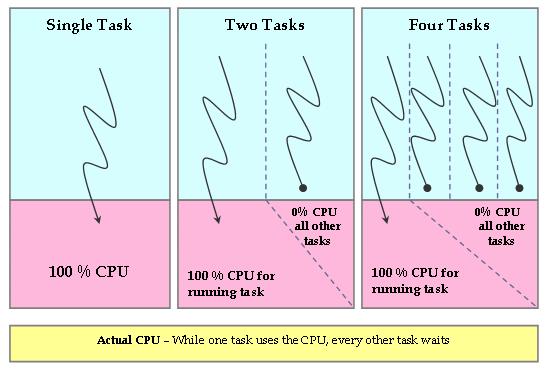
CFS调度器就是为了减少系统中的这种不公平,CFS跟踪记录CPU的公平分配份额,用来分配给系统中的每个进程。因此CFS在一小部分CPU时钟速度下运行一个公平时钟。公平时钟增加速度通过用实际时钟时间除以等待进程个数计算。结果就是分配给每个进程的CPU时间。
进程等待CPU的时候,调度器会跟踪记录它将会使用理想的处理器时间。这个等待时间用每个进程等待执行时间来表示,可以用来对进程进行排序,决定其在被抢占之前可以被分配的CPU时间。等待时间最长的进程会被首先选择调度到CPU上执行,当这个进程执行时,它的等待时间会相应减少,其他进程等待时间自然就会增加了。这样马上就会有另外一个等待时间最长的进程出现,当前执行的进程就会被抢占。基于这一原理,CFS调度器试图公平对待所有进程并使每个进程等待时间为0,这样每个进程就可以拥有等量的CPU资源,达到完全公平的一种理想状态。
二、Hadoop调度器
自从可插入式调度器实现以来,已开发了多种调度器算法。接下来的章节将会介绍各种算法以及各自适用的情况。
FIFO 调度器
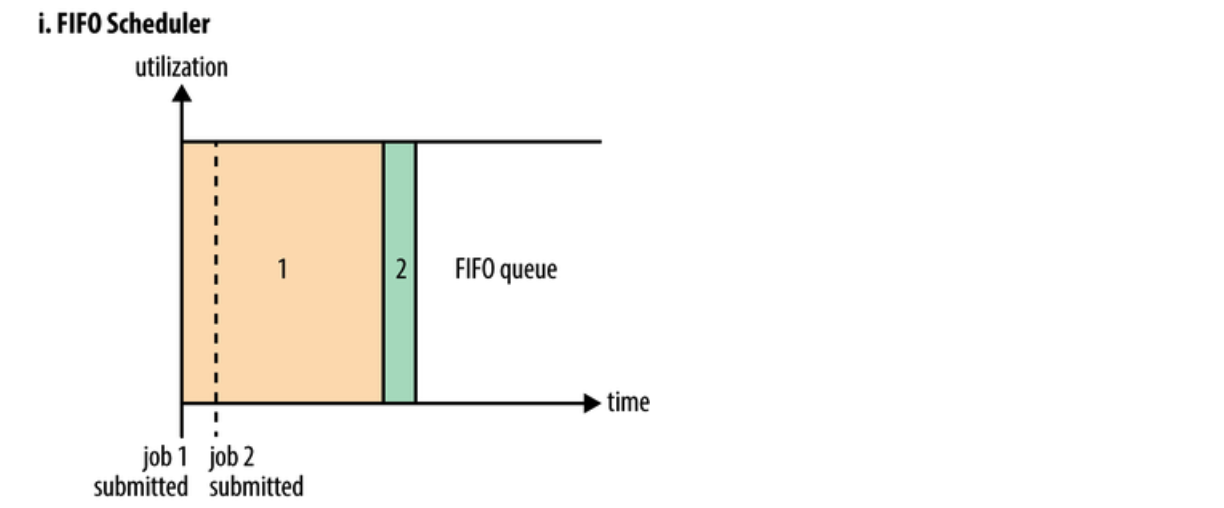
集成在 JobTracker 中的原有调度算法被称为 FIFO。在 FIFO 调度中,JobTracker 从工作队列中拉取作业,最老的作业最先。这种调度方法不会考虑作业的优先级或大小,但很容易实现,而且效率很高。在FIFO 调度器中,小任务会被大任务阻塞。
Fair Scheduler(公平调度器)
公平调度是一种将资源分配给作业的方法,使所有作业在一段时间内平均获得相等的资源份额。当运行一个作业时,该作业将使用整个集群。当提交其他作业时,空闲的任务槽被分配给新作业,因此每个作业获得的CPU时间大致相同。
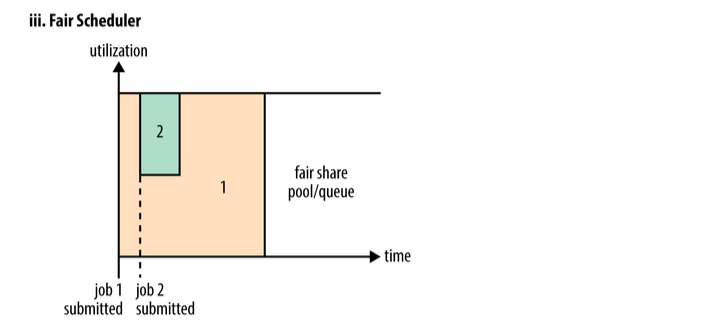
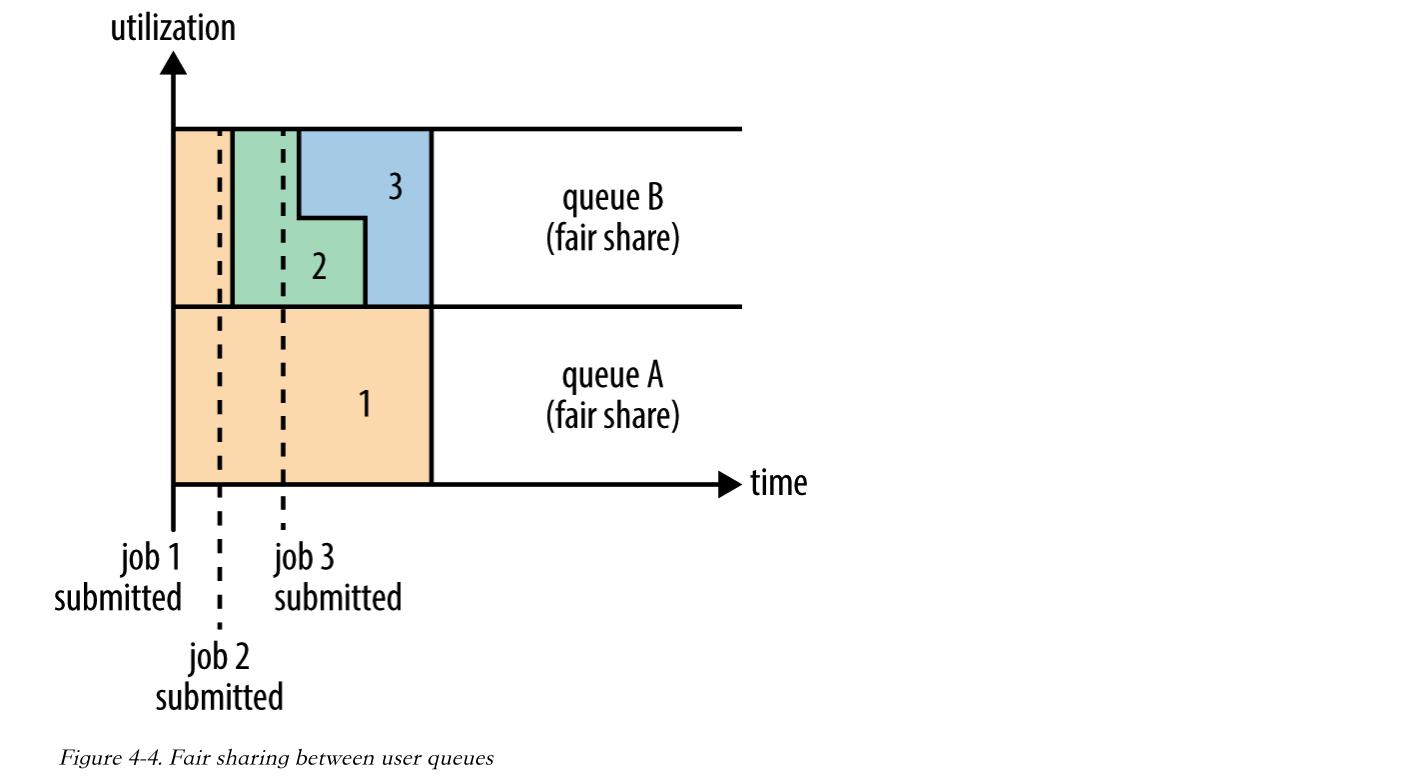
在Fair调度器中,我们不需要预先占用一定的系统资源,Fair调度器会为所有运行的job动态的调整系统资源。如下图所示,当第一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
当然,公平调度在也可以在多个队列间工作。举个例子,假设有两个用户A和B,他们分别拥有一个队列。当A启动一个job而B没有任务时,A会获得全部集群资源;当B启动一个job后,A的job会继续运行,不过一会儿之后两个任务会各自获得一半的集群资源。如果此时B再启动第二个job并且其它job还在运行,则它将会和B的第一个job共享B这个队列的资源,也就是B的两个job会用于四分之一的集群资源,而A的job仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享。
Capacity Scheduler(容量调度器)
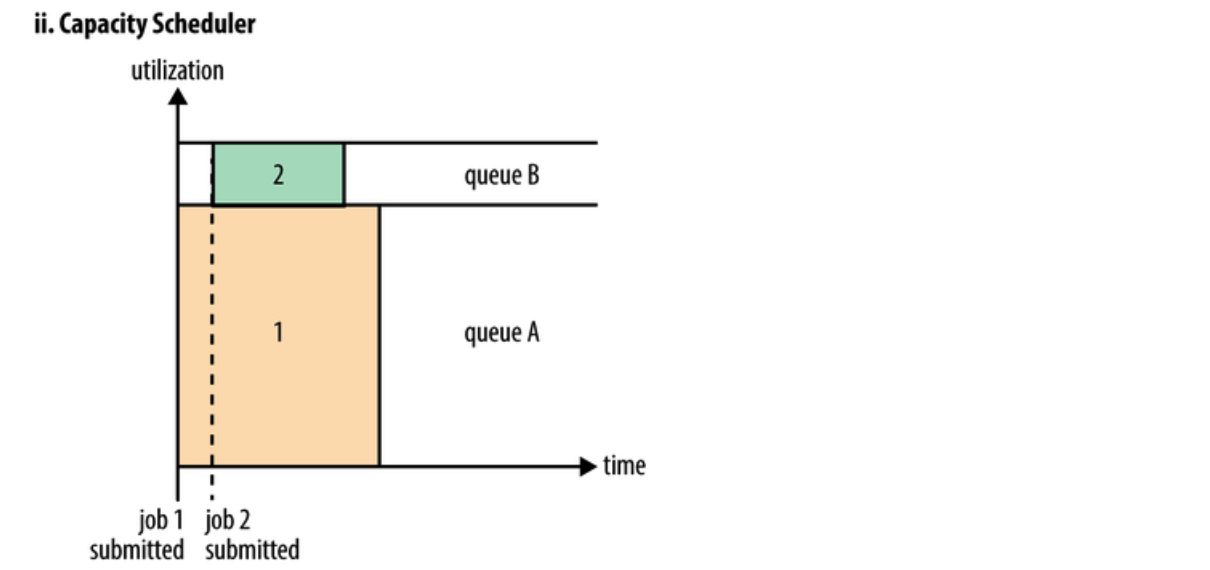
Capacity Scheduler设计用于允许共享一个大型集群,同时为每个组织提供容量保证。核心思想是Hadoop集群中的可用资源在多个组织之间共享,这些组织根据计算需求共同为集群提供资金。另一个好处是,一个组织可以访问其他组织没有使用的任何过剩容量。这以一种具有成本效益的方式为组织提供了弹性。
跨组织共享集群需要对多租户提供强有力的支持,因为每个组织都必须保证容量和安全,以确保共享集群不受单个流氓应用程序或用户或其集合的影响。Capacity Scheduler提供了一组严格的限制,以确保单个应用程序、用户或队列不能消耗集群中不成比例的资源。此外,Capacity Scheduler对来自单个用户和队列的初始化和挂起应用程序提供了限制,以确保集群的公平性和稳定性。
在容量调度中,创建的是队列,每个队列都会分配一个保证容量(集群的总容量是每个队列容量之和)。队列处于监控之下;如果某个队列未使用分配的容量,那么这些多余的容量会被临时分配到其他队列中。由于队列可以表示一个人或大型组织,那么所有的可用容量都可以由其他用户重新分配使用。
为了对资源共享提供进一步的控制和可预见性,Capacity Scheduler支持分层队列,确保在允许其他队列使用免费资源之前,在组织的子队列之间共享资源,从而为在给定组织的应用程序之间共享免费资源提供亲和力。
三、LVS的10种调度算法
静态算法:
rr(round robin):轮询调度算法:
轮询调度算法的原理就是依次将用户的访问请求,平均的分配到每一台web服务节点上,从1开始,到最后一台服务器节点结束,然后在开始新一轮的循环,这种算法简单,但是没有考虑到每台节点服务器的具体性能
wrr(weight):权重调度算法
由于每台服务器的性能会高低不同,wrr将会根据管理员设定的权重值来分配访问请求,权重值越大的,被分到的请求数也就越多,此种算法有效的解决了rr轮询算法的缺点
sh(source hashing)源地址散列:
主要实现会话绑定,解决session会话共享问题,源地址散列会根据请求的源ip地址,作为关键字,在静态分配的hash表中找出对应的服务器,若该服务器没有超过负荷,就将请求分配到该服务器
dh(destination hashing)目标地址散列,把同一个ip地址的请求,发送给同一个server
目标地址散列调度算法是针对目标ip地址的负载均衡,是一种静态映射算法,把目标ip地址作为关键字,在静态分配的hash表中找到对应的服务器,若该服务器可用并没有超过负荷,则将请求发送到该服务器
动态调度算法:
LC(least connection)最少连接:
当有用户发起访问请求时,lc算法将会把请求分配到集群中连接数最少的服务器上
wlc(weight least connection scheduling)加权最少连接:
加权最少连接算法是最少连接的升级版,各个服务器用想应的权重值表示其处理连接的性能,默认权重值为1,加权最少连接调度在调度访问请求时,会尽量使服务器的已建立连接和权重值成比例
也就是活动的连接数除以权重,谁小,挑谁
sed(shortest expected)最短延迟调度:
在wlc基础上进行改进,不在考虑非活动状态,把当前处于活动状态的数目+1,数目最小的,则接受下次访问请求,+1的目的是为了考虑加权的时候,非活动链接过多,当权限过大,会导致非空闲的节点一直处于无连接状态
nq(nerver queue)永不排队,改进的sed
无需队列,如果有rs节点的连接数为0,那么直接将访问请求分配过去,不需要进行sed运算
LBLC(locality based leastconnection)基于局部性的最少连接
此算法是根据请求报文的目标ip地址的负载均衡调度,目前主要用于cache集群系统,因为cache集群中的客户请求报文的目标ip地址是变化的,这里假设任何后端服务器都可以处理任何请求,算法的设计目标在服务器的负载剧本平衡的请求下,将相同的目标ip地址的请求调度到同一个服务器,来提高整个web服务的访问局部性和主存cache的命中率,从而调整整个集群系统的处理能力
基于局部性的最少连接调度算法根据请求的目标ip地址找出该目标地址最近使用的rs,若该rs可用,将发送请求,若该服务器不可用,则用最少连接的原则选出一台可用服务器来进行匹配
LBLCR(Locality-Based Least Connections withReplication)带复制的基于局部性最少连接
此种算法是针对目标ip地址的负载均衡,该算法根据请求的目标地址ip找出该地址对应的服务组,按最少连接的原则从服务组中选出一台服务器,若服务器没有超载,则发送请求到该服务器,若该服务器超载或者不可用,则按照最小连接的原则从这个集群中选出一台服务器,将该服务器添加到服务组中,在将请求发送到该服务器,同时当该服务器组中有一段时间没有被修改,将最忙的服务器从组中剔除,以降低复制的程度
四、Nginx的五种调度算法
rr轮询算法:
依次将用户的访问请求,平均的分配到后端的web集群中每个节点,此种算法不会考虑每个节点的性能,所以比较适用于所有节点的性能一致的情况
wrr权重算法:
根据设定的权重值,权重值越大,被配到的请求次数也就越多,有效的解决了rr算法的缺点
ip_hash算法:
根据用户访问的真实ip生成一个hash表,此后,同一个ip地址的访问请求都将会分配到这个节点上,可以解决session会话共享的问题
url_hash:
根据用户访问的url的hash结果,使每个url定向到同一个后端服务器上
fair:
fair是更加智能的负载均衡算法,此种算法可以根据页面大小的和加载时间长短智能的进行负载均衡,也就是根据后端节点的响应时间来分配请求,响应时间短的则优先分配,Nginx本身不支持fair,如果需要则必须下载nginx的upstream_fair模块
五、gig:自带负载均衡和降级功能的高可用RPC解决方案
gig的核心功能之一是解决包含网络异常在内的坏节点问题,而不同的系统对异常的定义不同,gig选择了所有在线系统都有的一个核心指标"查询延迟"作为节点好坏的评判标准,节点队列堵塞、网络超时、操作系统负载高等异常情况均能在latency上反应出来。同样,系统负载也能从latency上体现,因而gig的降级(限流)策略和负载均衡策略也是基于latency的。
如果将在线树状系统想象成一个大的水利灌溉系统(gig名字的由来),灌溉者的功能是将水导向系统中阻力最小的部分,既不能让入口水流堵塞,也不能让干旱发生,到gig这里,水即是流量,阻力则可以近似认为是latency,阻塞是系统吞吐量下跌,干旱则是负载不均衡。所以gig会统计上图中每一条边的平均latency,并据此导流,更进一步,gig还通过控制流量高低来控制每一条边的latency。
流量控制的目的是为了稳定每一个节点的latency,各个节点的latency差异控制在合理范围内,对于高latency的节点应该予以屏蔽。为了稳定各个节点的latency,我们设计了如下图所示的负反馈控制器:
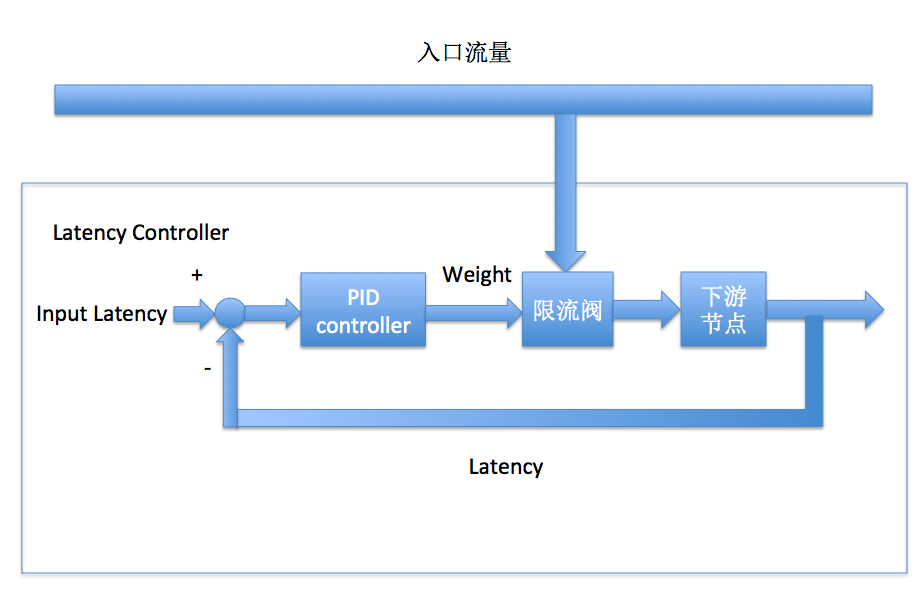
图中的PID控制器实际上只使用了I(Integral)部分,即一个带抗饱和功能的积分器,整体是一个过阻尼系统,这样设计的原因是线上各个系统的Latency-qps关系变化很大,积分本身虽然相应速度慢,但由于在线系统的响应速度快(流量升高时latency会瞬间上升),latency达到预期值后积分器瞬间停止积分,不会超调导致下游节点CPU被打满。
六、TPP的负载均衡(流量调度)
ps: 目前的资料仅有一份不太详细的设计方案
设计考虑点
-
机器上线/热部署事件
-
性能波动
-
服务质量:latency/cpu/load
-
防止雪崩/优先保证不降级
-
单机cache命中率/uid
-
小流量集群调度
-
集群不同规格机器支持
权重计算和调节
w1,w2,......wn, 被选中的概率:w(i)/sum(w)
目标: cpu1, cpu2,..... cpun接近相等并保持稳定
cpu为cpu_usage, 和ps结果接近,不超过100%. 若为load,则为单core的平均load,默认2已经无法正常服务
-
1/ 指标被归一化到(0,100)区间
-
2/ 5%误差, 指标都是周期统计结果,允许一定的波动范围,避免反复调节达不到稳定状态。因此存在20个状态, 由于cpu等限流因此部分状态无效
-
3/ 默认权重w=20;若当前机器负载为: cpu1, cpu2,......cpun, 求平均数,按照cpu状态排序,并按照和平均数的差距进行权重加减, 形成一轮新的w1,w2,.....wn, 而sum(w) 仍然为20*n
-
4/ 机器-1, 重新计算平均数,重复(3)步骤
-
5/ 机器+1, 渐进式扩流量,权重默认为1,重复步骤(3)
-
6/ 机器增减m,同(4),(5)
-
7/ 调度周期:需要根据流量和机器规模设置一个合理值,不能太快也不能太迟钝,原则是:本地调度完几乎所有router状态达到一致,且当前权重下负载达到稳态。当然灵敏肯定没问题,只要指标最好平滑即可,只是太频繁调整会浪费性能