版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/renhaofan/article/details/83897564
host:CPU,内存
device:GPU,显存
我是纯粹小白,里面的一些图是根据我自己的理解画的,可能并不一定对
一,GPU和CPU执行程序的区别
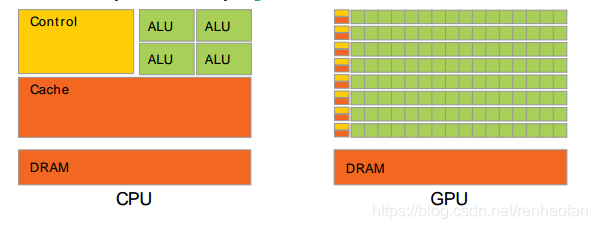 (图片来源:CUDA_C_Programming-Guide)
(图片来源:CUDA_C_Programming-Guide)
可以看到GPU有跟多的cores,你可以先把cores理解成计算的最小的单元。
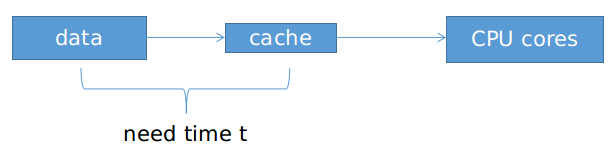
通常来说,访问数据的时间随着计算核和存储数据的内存位置的距离而增加
Latency延迟是核等待数据的时间。
CPU是通过大量的告诉缓存cache来缩短这个时间的,也就是尽可能减少时间t来减小延迟,CPU关注单个核心的执行速度
如果warp1所需要的而数据不可以获得的话,那么SM就会转向一个可以获得数据的线程束。GPU所关注的是整体的运算吞吐量,而不是单个核心的执行速度
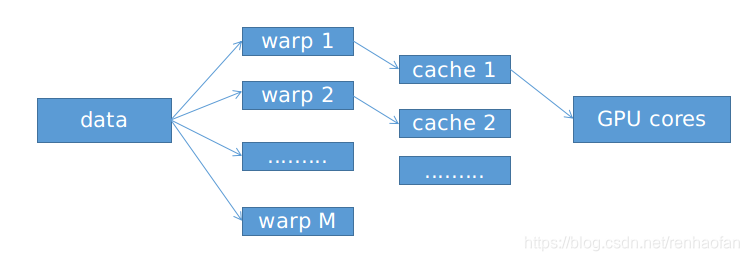
如何产生大量的线程?
CUDA通过一种叫做核函数(kernel)的特殊函数去实现的,这个函数会产生大量的可以分配SM的计算线程
二,GPU的背景知识
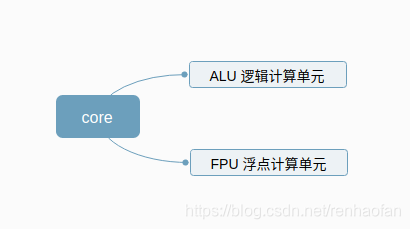
GPU的每一个core(计算核心)都有两个计算单元
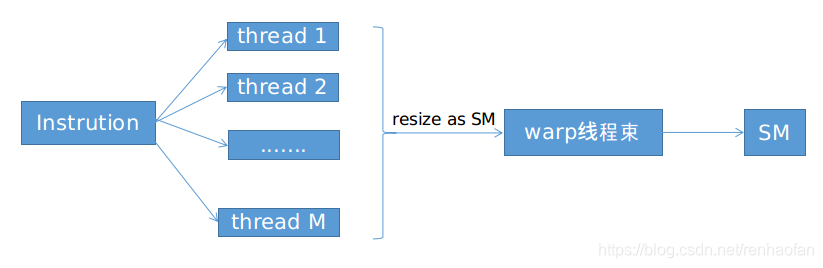
输出指令之后GPU执行程序的流程,也就是所谓的SIMT(single instruction multiple threads)
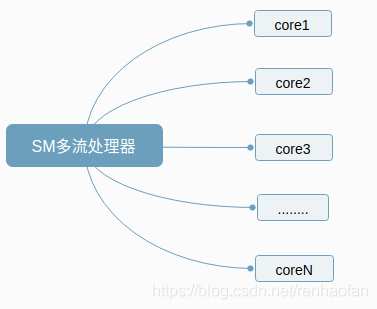
SM中每一个core执行的具体的运算是不一样的,有CUDA统一调度
SM是借用一种特殊的函数–核函数(kernel)去执行的。具体执行的时候是这样去做的:
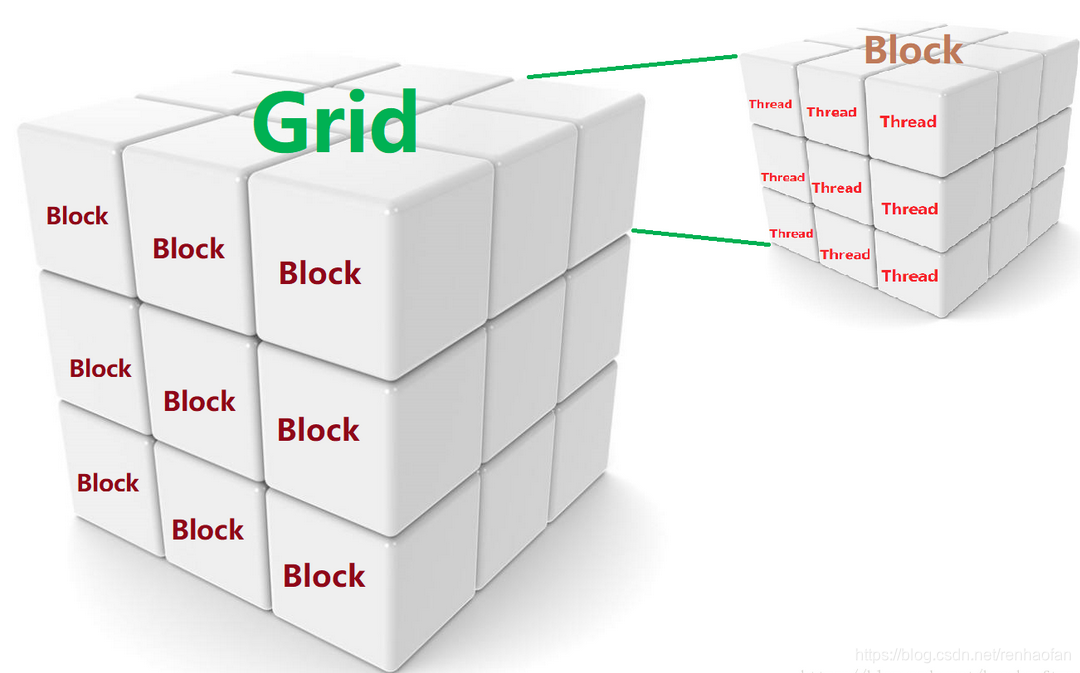
(图片来源:https://blog.csdn.net/breaksoftware/article/details/79302590 by breaksoftware)
参考
- 《CUDA高性能并行计算》机械工业出版社
- CUDA_C_Programming-Guide
- CUDA高性能编程入门