目录:
- 集群规划
- HDFS HA
- 冒烟测试
- 功能特性
集群规划:
- 负载类型
- 容量规划
- 可扩展性
- 角色分离
- 管理节点
- Master节点
- Worker节点
- 边缘节点
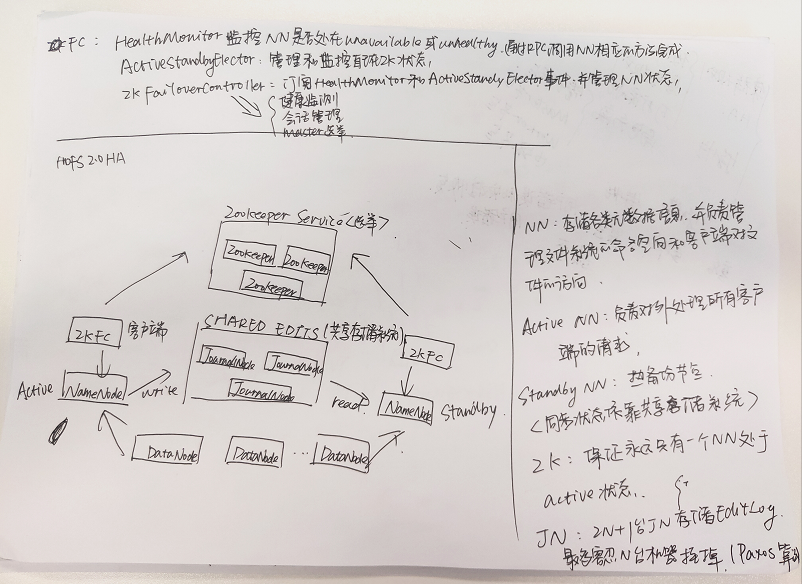
HDFS HA(高可用)
架构原理见下图:
冒烟测试:
详细说明参见之前的博客:https://www.cnblogs.com/huxinga/p/9627084.html
功能特性:
- HDFS Balancer
- 快照 Snapshots
- 配额 Quota
- 权限 ACLs
- 存储策略
- 集中缓存管理
- 机架感知
- Erasure Coding
- Memory as Storage
- Short-Circuit Local Reads
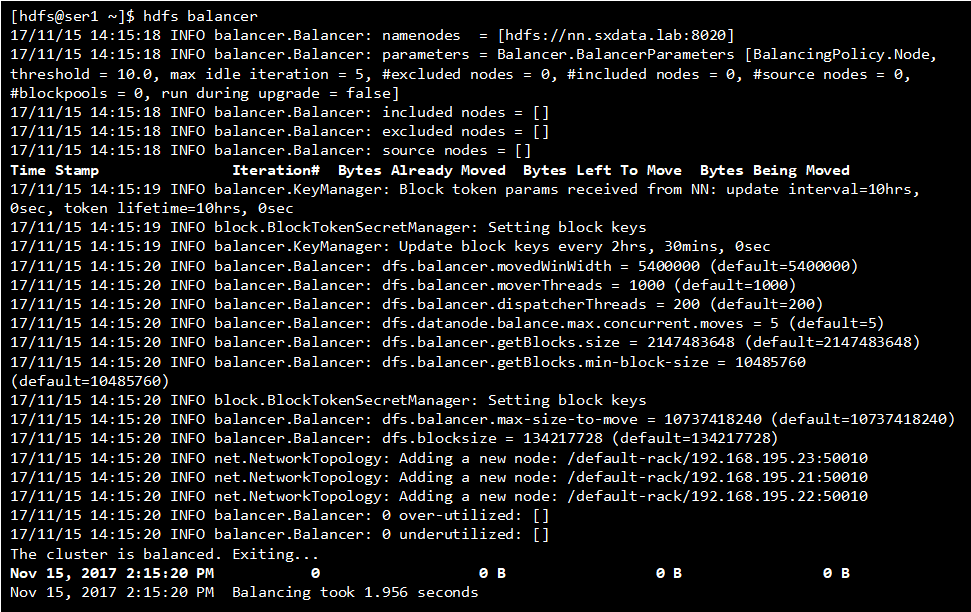
1,HDFS Balancer
balancer是当hdfs集群中一些datanodes的存储要写满了或者有空白的新节点加入集群时,用于均衡hdfs集群磁盘使用量的一个工具。
Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加新的数据节点。当HDFS出现不平衡状况的时候,将引发很多问题,比如MR程序无法很好地利用本地计算的优势,机器之间无法达到更好的网络带宽使用率,机器磁盘无法利用等等。可见,保证HDFS中的数据平衡是非常重要的。在Hadoop中,包含一个Balancer程序,通过运行这个程序,可以使得HDFS集群达到一个平衡的状态
参考命令:
hdfs balancer hdfs dfsadmin [-setBalancerBandwidth <bandwidth in bytes per second>]
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>6250000</value>
</property>
2,快照 snapshots
HDFS快照是文件系统的只读时间点的副本。可以在文件系统的子树或整个文件系统上拍摄快照。快照的一些常见⽤例是数据备份,防⽌用户错误和灾难恢复。
HDFS中可以对目录创建Snapshot,创建之后不管后续目录发生什么变化,都可以通过snapshot找回原来的文件和目录结构。
实现原理:
实现上是通过在每个目标节点下面创建snapshot节点,后续任何子节点的变化都会同步记录到snapshot上。例如删除子节点下面的文件,并不是直接文件元信息以及数据删除,而是将他们移动到snapshot下面。这样后续还能够恢复回来。另外snapshot保存是一个完全的现场,不仅是删除的文件还能找到,新创建的文件也无法看到。后一种效果的实现是通过在snapshot中记录哪些文件是新创建的,查看列表的时候将这些文件排除在外。
参考命令:

# 为指定目录开启快照功能 hdfs dfsadmin -allowSnapshot <path> # 列出开启了快照功能的目录 hdfs lsSnapshottableDir # 创建快照 hdfs dfs -createSnapshot <path> [<snapshotName>] # ⽐较两个快照之间的区别 hdfs snapshotDiff <path> <fromSnapshot> <toSnapshot> # 列出快照内的⽂文件 hdfs dfs -ls /foo/.snapshot # 从快照中恢复数据。 此处使用了了preserve选项来保留时间戳、所有权、权限、ACL 和 XAttrs扩展属性 hdfs dfs -cp -ptopax /foo/.snapshot/s0/bar /tmp

例子分析:
我们通过一个例子来分析整个snapshot的实现细节:
1. 文件目录树如下图所示,并且我们已经通过命令启动了a的snapshot功能,结构如下图所示:

图中.snapshot是虚拟节点,保存了所有的snapshot列表,其中diff中还保存当前节点下面的变化,一个snapshot对应于一个diff.要注意的是snapshot中可以被多个目录的diff引用,后续会进行说明。
2. 当我们执行createSnapshot命令时,结果如下: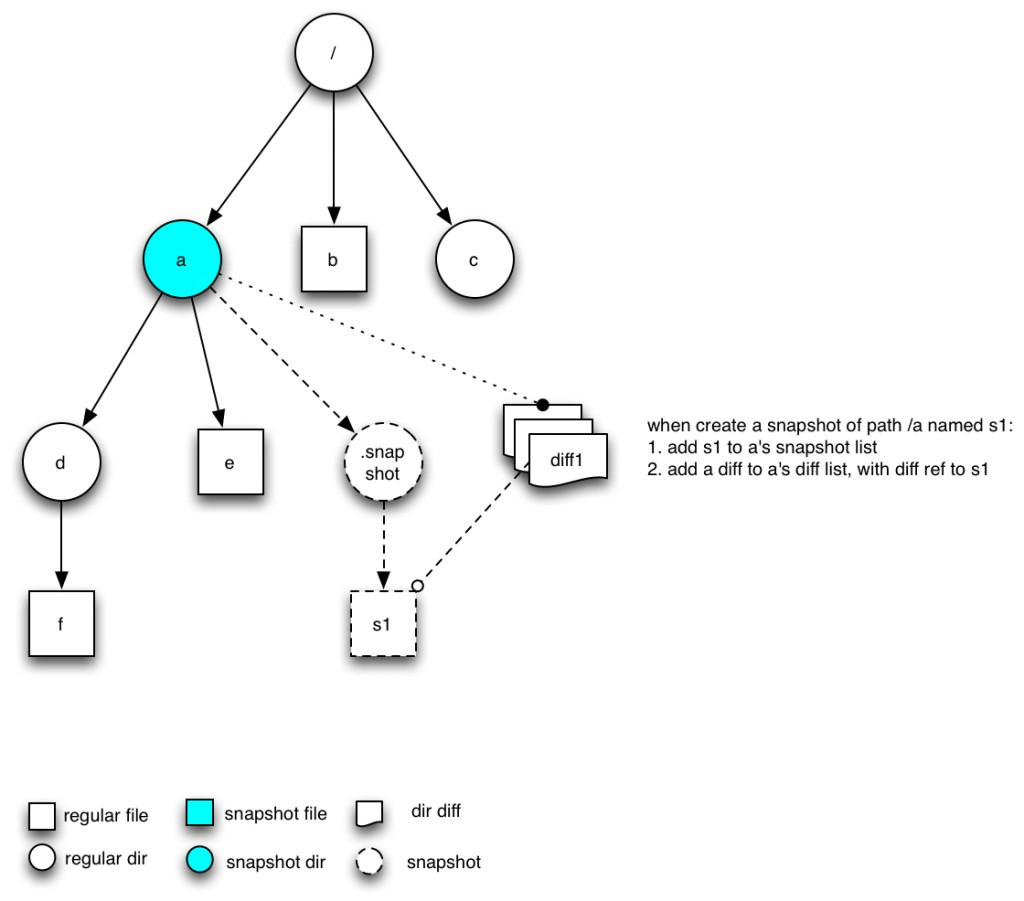
3. 当删除文件e的时候
不论是删除一个文件还是一个目录,只要是直接子节点,都会将节点转换为快照版本.例如e会变成INodeFileWithSnapshot,在a的DirectoryDiff中ChildDiff中deleted列表中将会包含e,而在a的正常节点下会被删除。目录节点的处理同样。
4. 删除孙子节点是的情况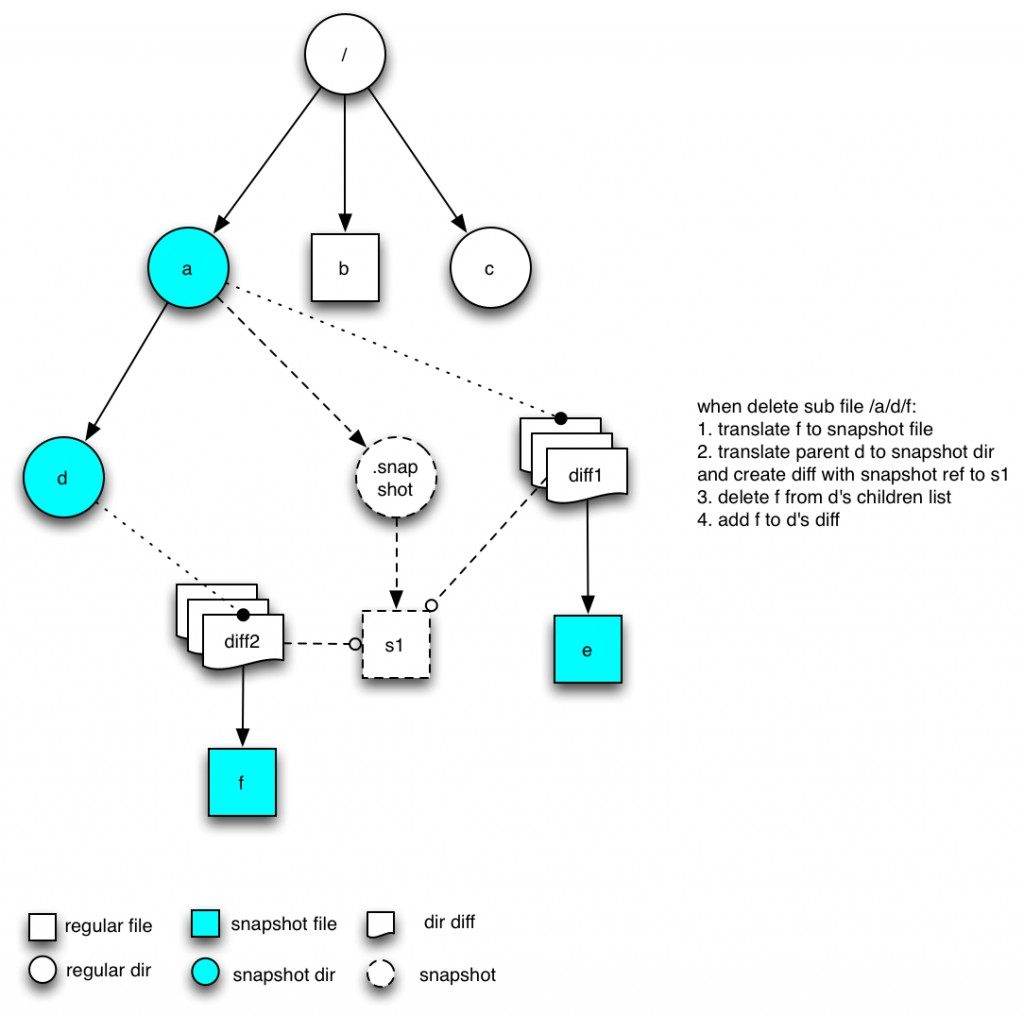
处理这种节点的原则是:先将孙子节点转变为Snapshot版本,然后将父节点变为snapshot版本,同时将孙子节点版本加入到直接父节点的diff列表中。为了能够通过同一个snapshot找到当时的文件,需要将新的diff指向到老的snapshot版本上。图中d节点是INodeDirectoryWithSnapshot(不是INodeDiretorySnapshottable, 本身不允许在d上创建snapshot)
3,配额 Quata
Name Quotas :
Name Quota 是该目录下所有文件和目录总的数量的硬限制。如果超出配额,文件和目录创建将失败。配额为1会强制目录保持为空。 重命名后依然有效
Space Quotas :
Space Quota 是该目录下所有文件使用的字节数的硬限制。如果配额不允许写入完整块,则块分配将失败。块的每个副本都会计入配额。 最好设置空间大小为快的整数倍。空间配额为0时可以创建文件,但不能向文件中写入内容,单位为BYTE。
存储类型配额 :
存储类型配额是该目录中文件使用特定存储类型(SSD,DISK,ARCHIVE)的硬限制
参考命令:
hdfs dfsadmin -setQuota <N> <directory>...<directory> hdfs dfsadmin -clrQuota <directory>...<directory> hdfs dfsadmin -setSpaceQuota <N> <directory>...<directory> hdfs dfsadmin -clrSpaceQuota <directory>...<directory> hdfs dfsadmin -setSpaceQuota <N> -storageType <storagetype> <directory>...<directory> hdfs dfsadmin -clrSpaceQuota -storageType <storagetype> <directory>...<directory> hadoop fs -count -q [-h] [-v] [-t [comma-separated list of storagetypes]] <directory>...<directory
4,HDFS ACLs