版权声明:博主GitHub地址https://github.com/suyeq欢迎大家前来交流学习 https://blog.csdn.net/hackersuye/article/details/83116814
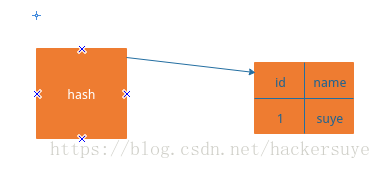
哈希类型又叫做字典,在redis中,哈希类型本身是一个键值对,而哈希类型里面也存贮着键值对,其对应关系是,每个哈希类型的值对应着一个键值对或多对键值对,如图所示:
哈希类型命令
| 命令 | 对应操作 | 时间复杂度 |
|---|---|---|
| hset key field value | 添加一个域值对 | O(1) |
| hget key field | 获取域值 | O(1) |
| hdel key field [field…] | 删除多个域值对 | O(n) |
| hlen key | 该哈希表的长度 | O(1) |
| hgetall key | 获取全部的域值对 | O(n) |
| hmget field [field…] | 获取多个指定键的域值对 | O(n) |
| hmset field value [field…] | 设置多个域值对 | O(n) |
| hexists key field | 检测其中是否有了field键 | O(1) |
| hkeys key | 列出所有的域名 | O(n) |
| hvals key | 列出所有的域值 | O(n) |
| hsetnx key field value | 增加一个之前必须不存在的域值 | O(1) |
| hincrby key field increment | 自增一段 | O(1) |
| hincrbyfloat key field increment | 浮点数自增 | O(1) |
| hstrlen key field | 获取其对应域值的字符串长度 | O(1) |
编码的转换
当每个元素的值的字节长都小于默认的64字节时,以及总长度小于默认的512个时,哈希对象会采用ziplist来保存数据,在插入新的元素的时候都会检查是否会满足这两个条件,不满足则进行编码的转换:
# hash_max_ziplist_value 64
void hashTypeTryConversion(robj *o, robj **argv, int start, int end) {
int i;
// 如果对象不是 ziplist 编码,那么直接返回
if (o->encoding != REDIS_ENCODING_ZIPLIST) return;
// 检查所有输入对象,看它们的字符串值是否超过了指定长度
for (i = start; i <= end; i++) {
if (sdsEncodedObject(argv[i]) &&
sdslen(argv[i]->ptr) > server.hash_max_ziplist_value)
{
// 将对象的编码转换成 REDIS_ENCODING_HT
hashTypeConvert(o, REDIS_ENCODING_HT);
break;
}
}
}
/*
* 将一个 ziplist 编码的哈希对象 o 转换成其他编码
*/
void hashTypeConvertZiplist(robj *o, int enc) {
redisAssert(o->encoding == REDIS_ENCODING_ZIPLIST);
// 如果输入是 ZIPLIST ,那么不做动作
if (enc == REDIS_ENCODING_ZIPLIST) {
/* Nothing to do... */
// 转换成 HT 编码
} else if (enc == REDIS_ENCODING_HT) {
hashTypeIterator *hi;
dict *dict;
int ret;
// 创建哈希迭代器
hi = hashTypeInitIterator(o);
// 创建空白的新字典
dict = dictCreate(&hashDictType, NULL);
// 遍历整个 ziplist
while (hashTypeNext(hi) != REDIS_ERR) {
robj *field, *value;
// 取出 ziplist 里的键
field = hashTypeCurrentObject(hi, REDIS_HASH_KEY);
field = tryObjectEncoding(field);
// 取出 ziplist 里的值
value = hashTypeCurrentObject(hi, REDIS_HASH_VALUE);
value = tryObjectEncoding(value);
// 将键值对添加到字典
ret = dictAdd(dict, field, value);
if (ret != DICT_OK) {
redisLogHexDump(REDIS_WARNING,"ziplist with dup elements dump",
o->ptr,ziplistBlobLen(o->ptr));
redisAssert(ret == DICT_OK);
}
}
// 释放 ziplist 的迭代器
hashTypeReleaseIterator(hi);
// 释放对象原来的 ziplist
zfree(o->ptr);
// 更新哈希的编码和值对象
o->encoding = REDIS_ENCODING_HT;
o->ptr = dict;
} else {
redisPanic("Unknown hash encoding");
}
}
/*
* 对哈希对象 o 的编码方式进行转换
*
* 目前只支持将 ZIPLIST 编码转换成 HT 编码
*/
void hashTypeConvert(robj *o, int enc) {
if (o->encoding == REDIS_ENCODING_ZIPLIST) {
hashTypeConvertZiplist(o, enc);
} else if (o->encoding == REDIS_ENCODING_HT) {
redisPanic("Not implemented");
} else {
redisPanic("Unknown hash encoding");
}
}
检查域是否存在
步骤是先判断是哪种编码类型,然后调用对应的API接口,返回一个值表示成功:
/*
* 参数:
* field 域
* vstr 值是字符串时,将它保存到这个指针
* vlen 保存字符串的长度
* ll 值是整数时,将它保存到这个指针
* 查找失败时,函数返回 -1 。
* 查找成功时,返回 0 。
*/
int hashTypeGetFromZiplist(robj *o, robj *field,
unsigned char **vstr,
unsigned int *vlen,
long long *vll)
{
unsigned char *zl, *fptr = NULL, *vptr = NULL;
int ret;
// 确保编码正确
redisAssert(o->encoding == REDIS_ENCODING_ZIPLIST);
// 取出未编码的域
field = getDecodedObject(field);
// 遍历 ziplist ,查找域的位置
zl = o->ptr;
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) {
// 定位包含域的节点
fptr = ziplistFind(fptr, field->ptr, sdslen(field->ptr), 1);
if (fptr != NULL) {
// 域已经找到,取出和它相对应的值的位置
vptr = ziplistNext(zl, fptr);
redisAssert(vptr != NULL);
}
}
decrRefCount(field);
// 从 ziplist 节点中取出值
if (vptr != NULL) {
ret = ziplistGet(vptr, vstr, vlen, vll);
redisAssert(ret);
return 0;
}
// 没找到
return -1;
}
/*
* 从 REDIS_ENCODING_HT 编码的 hash 中取出和 field 相对应的值。
* 成功找到值时返回 0 ,没找到返回 -1 。
*/
int hashTypeGetFromHashTable(robj *o, robj *field, robj **value) {
dictEntry *de;
// 确保编码正确
redisAssert(o->encoding == REDIS_ENCODING_HT);
// 在字典中查找域(键)
de = dictFind(o->ptr, field);
// 键不存在
if (de == NULL) return -1;
// 取出域(键)的值
*value = dictGetVal(de);
// 成功找到
return 0;
}
/*
* 多态 GET 函数,从 hash 中取出域 field 的值,并返回一个值对象。
* 找到返回值对象,没找到返回 NULL 。
*/
robj *hashTypeGetObject(robj *o, robj *field) {
robj *value = NULL;
// 从 ziplist 中取出值
if (o->encoding == REDIS_ENCODING_ZIPLIST) {
unsigned char *vstr = NULL;
unsigned int vlen = UINT_MAX;
long long vll = LLONG_MAX;
if (hashTypeGetFromZiplist(o, field, &vstr, &vlen, &vll) == 0) {
// 创建值对象
if (vstr) {
value = createStringObject((char*)vstr, vlen);
} else {
value = createStringObjectFromLongLong(vll);
}
}
// 从字典中取出值
} else if (o->encoding == REDIS_ENCODING_HT) {
robj *aux;
if (hashTypeGetFromHashTable(o, field, &aux) == 0) {
incrRefCount(aux);
value = aux;
}
} else {
redisPanic("Unknown hash encoding");
}
// 返回值对象,或者 NULL
return value;
}
新增元素
下面给出HSET系列命令的底层实现:
/*
* 将给定的 field-value 对添加到 hash 中,
* 如果 field 已经存在,那么删除旧的值,并关联新值。
* 这个函数负责对 field 和 value 参数进行引用计数自增。
* 返回 0 表示元素已经存在,这次函数调用执行的是更新操作。
* 返回 1 则表示函数执行的是新添加操作。
*/
int hashTypeSet(robj *o, robj *field, robj *value) {
int update = 0;
// 添加到 ziplist
if (o->encoding == REDIS_ENCODING_ZIPLIST) {
unsigned char *zl, *fptr, *vptr;
// 解码成字符串或者数字,ziplist需要编码与解码操作
field = getDecodedObject(field);
value = getDecodedObject(value);
// 遍历整个 ziplist ,尝试查找并更新 field (如果它已经存在的话)
zl = o->ptr;
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) {
// 定位到域 field
fptr = ziplistFind(fptr, field->ptr, sdslen(field->ptr), 1);
if (fptr != NULL) {
/* Grab pointer to the value (fptr points to the field) */
// 定位到域的值
vptr = ziplistNext(zl, fptr);
redisAssert(vptr != NULL);
// 标识这次操作为更新操作
update = 1;
/* Delete value */
// 删除旧的键值对
zl = ziplistDelete(zl, &vptr);
/* Insert new value */
// 添加新的键值对
zl = ziplistInsert(zl, vptr, value->ptr, sdslen(value->ptr));
}
}
// 如果这不是更新操作,那么这就是一个添加操作
if (!update) {
/* Push new field/value pair onto the tail of the ziplist */
// 将新的 field-value 对推入到 ziplist 的末尾
zl = ziplistPush(zl, field->ptr, sdslen(field->ptr), ZIPLIST_TAIL);
zl = ziplistPush(zl, value->ptr, sdslen(value->ptr), ZIPLIST_TAIL);
}
// 更新对象指针
o->ptr = zl;
// 释放临时对象
decrRefCount(field);
decrRefCount(value);
/* Check if the ziplist needs to be converted to a hash table */
// 检查在添加操作完成之后,是否需要将 ZIPLIST 编码转换成 HT 编码
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, REDIS_ENCODING_HT);
// 添加到字典
} else if (o->encoding == REDIS_ENCODING_HT) {
// 添加或替换键值对到字典
// 添加返回 1 ,替换返回 0
if (dictReplace(o->ptr, field, value)) { /* Insert */
incrRefCount(field);
} else { /* Update */
update = 1;
}
incrRefCount(value);
} else {
redisPanic("Unknown hash encoding");
}
// 更新/添加指示变量
return update;
}
删除元素
/*
* 删除成功返回 1 ,因为域不存在而造成的删除失败返回 0 。
*/
int hashTypeDelete(robj *o, robj *field) {
int deleted = 0;
// 从 ziplist 中删除
if (o->encoding == REDIS_ENCODING_ZIPLIST) {
unsigned char *zl, *fptr;
field = getDecodedObject(field);
zl = o->ptr;
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) {
// 定位到域
fptr = ziplistFind(fptr, field->ptr, sdslen(field->ptr), 1);
if (fptr != NULL) {
// 删除域和值
zl = ziplistDelete(zl,&fptr);
zl = ziplistDelete(zl,&fptr);
o->ptr = zl;
deleted = 1;
}
}
decrRefCount(field);
// 从字典中删除
} else if (o->encoding == REDIS_ENCODING_HT) {
if (dictDelete((dict*)o->ptr, field) == REDIS_OK) {
deleted = 1;
/* Always check if the dictionary needs a resize after a delete. */
// 删除成功时,看字典是否需要收缩
if (htNeedsResize(o->ptr)) dictResize(o->ptr);
}
} else {
redisPanic("Unknown hash encoding");
}
return deleted;
}
获取所有域
在讲解数据库遍历时谈到redis采取了两种不同的遍历方式,全量遍历与渐进式遍历,先来看看全量遍历KEYS命令的底层实现:
void genericHgetallCommand(redisClient *c, int flags) {
robj *o;
hashTypeIterator *hi;
int multiplier = 0;
int length, count = 0;
// 取出哈希对象
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.emptymultibulk)) == NULL
|| checkType(c,o,REDIS_HASH)) return;
// 计算要取出的元素数量
if (flags & REDIS_HASH_KEY) multiplier++;
if (flags & REDIS_HASH_VALUE) multiplier++;
length = hashTypeLength(o) * multiplier;
addReplyMultiBulkLen(c, length);
// 迭代节点,并取出元素
hi = hashTypeInitIterator(o);
while (hashTypeNext(hi) != REDIS_ERR) {
// 取出键
if (flags & REDIS_HASH_KEY) {
addHashIteratorCursorToReply(c, hi, REDIS_HASH_KEY);
count++;
}
// 取出值
if (flags & REDIS_HASH_VALUE) {
addHashIteratorCursorToReply(c, hi, REDIS_HASH_VALUE);
count++;
}
}
// 释放迭代器
hashTypeReleaseIterator(hi);
redisAssert(count == length);
}
渐进式遍历,直接调用数据库中scanGenericCommand方法:
void hscanCommand(redisClient *c) {
robj *o;
unsigned long cursor;
//表示开始渐进式遍历
if (parseScanCursorOrReply(c,c->argv[2],&cursor) == REDIS_ERR) return;
//读取对象,检查类型
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.emptyscan)) == NULL ||
checkType(c,o,REDIS_HASH)) return;
scanGenericCommand(c,o,cursor);
}
关于自增、获取长度等操作与列表类型相似,在此不再重复。