本文介绍了计算机视觉常用工具:卷积神经网络。用大白话讲解了其应用领域、卷积、池化(下采样)、全连接、梯度下降、反向传播算法。并用三维可视化工具展示了手写字体识别的卷积神经网络案例,最后介绍了几个经典的卷积神经网络模型以及一些新手易上手的计算机视觉开源项目。
强烈建议先看上面两个视频再阅读本文!
作者:张子豪(同济大学在读研究生)
关注微信公众号 人工智能小技巧 回复 卷积神经网络 或者 CNN 即可看到文中的B站视频、Gif动画、三维可视化卷积神经网络网站
于2018-11-10发布
文章目录
- 1、卷积神经网络应用领域
- 2、三维可视化手写字体识别卷积神经网络内部结构
- 3、卷积神经网络内部结构
- 4、几个经典的卷积神经网络模型
- LeNet-5:识别手写字体的经典卷积神经网络
- AlexNet:2012年ImageNet竞赛冠军
- GoogLeNet:2014年ImageNet冠军
- VGGNet:2014年ImageNet亚军
- ResNet深度残差卷积神经网络
- 各种模型识别成功率比较
- 5、一些轻松易上手的计算机视觉项目
- 微软年龄测试API
- 自动生成图片描述—captionbot
- 微软Custom Vision —不用写代码,三分钟开发一个图像分类应用
- Github开源人脸识别项目face_recognition
- 在树莓派微型电脑上安装OpenCV
- 视频剪辑师的福音—微软Video Indexer
- 6、参考文献与扩展阅读
1、卷积神经网络应用领域
卷积神经网络可以处理图像以及一切可以转化成类似图像结构的数据。相比传统算法和其它神经网络,卷积神经网络能够高效处理图片的二维局部信息,提取图片特征,进行图像分类。通过海量带标签数据输入,用梯度下降和误差反向传播的方法训练模型。
图像分类


人脸识别

Github开源人脸识别项目face_recognition中文文档
自动驾驶

语音处理:将时序声音转化为类似图像的数据结构

自然语言处理:将文本序列转化为类似图像的数据结构

2、三维可视化手写字体识别卷积神经网络内部结构
网站:三维可视化卷积神经网络
http://scs.ryerson.ca/~aharley/vis/conv/
关注微信公众号 人工智能小技巧 回复 卷积神经网络 即可看到这个手写字体可视化网站。

卷积神经网络识别手写字体步骤


1、把手写字体图片转换成像素矩阵
2、对像素矩阵进行第一层卷积运算,生成六个feature map
3、对每个feature map进行下采样(也叫做池化),在保留feature map特征的同时缩小数据量。生成六个小图,这六个小图和上一层各自的feature map长得很像,但尺寸缩小了。
4、对六个小图进行第二层卷积运算,生成更多feature map
5、对第二次卷积生成的feature map进行下采样
6、第一层全连接层
7、第二层全连接层
8、高斯连接层,输出结果
关注微信公众号 人工智能小技巧 回复 卷积神经网络 或者 CNN 即可看到文中的B站视频、Gif动画、卷积神经网络可视化网站
3、卷积神经网络内部结构
卷积运算:识别图片中指定特征
用卷积核在原图上滑动,进行卷积运算,得到特征图feature map。
卷积的本质:将原图中符合卷积核特征的特征提取出来,展示在feature map里面。
如果原图是X,卷积核是X,那么卷积核在原图上卷积运算之后生成的feature map也是X。
如果原图是O,卷积核是O,那么卷积核在原图上卷积运算之后生成的feature map也是O。
如果原图是O,卷积核是X,那么卷积核在原图上卷积运算之后生成的feature map就是乱码。
权值共享:卷积核扫过整张图片的过程中,卷积核参数不变。
下图的动画中,绿色表示原图像素值,红色数字表示卷积核中的参数,黄色表示卷积核在原图上滑动。右图表示卷积运算之后生成的feature map。

下图展示了RGB三个通道图片的卷积运算过程,共有两组卷积核,每组卷积核都有三个filter分别与原图的RGB三个通道进行卷积。每组卷积核各自生成一个feature map。
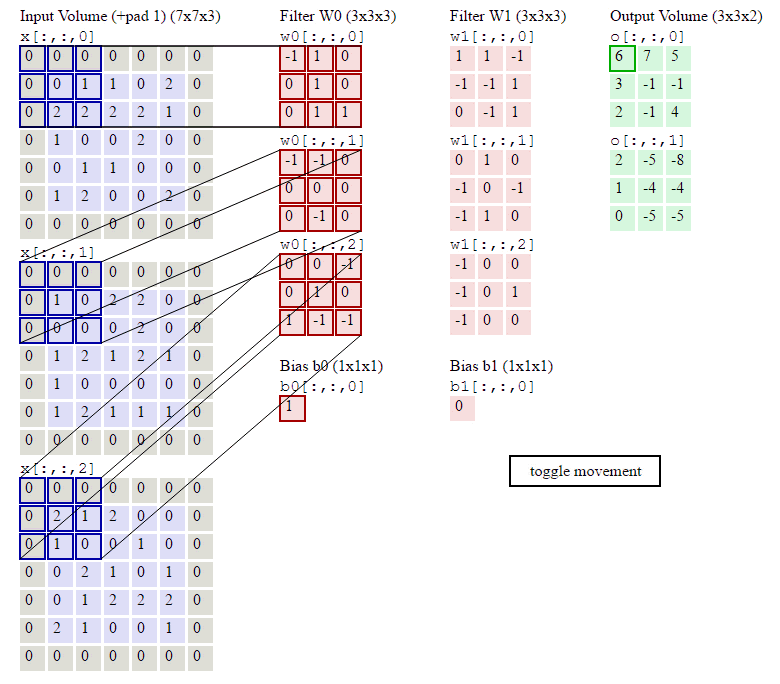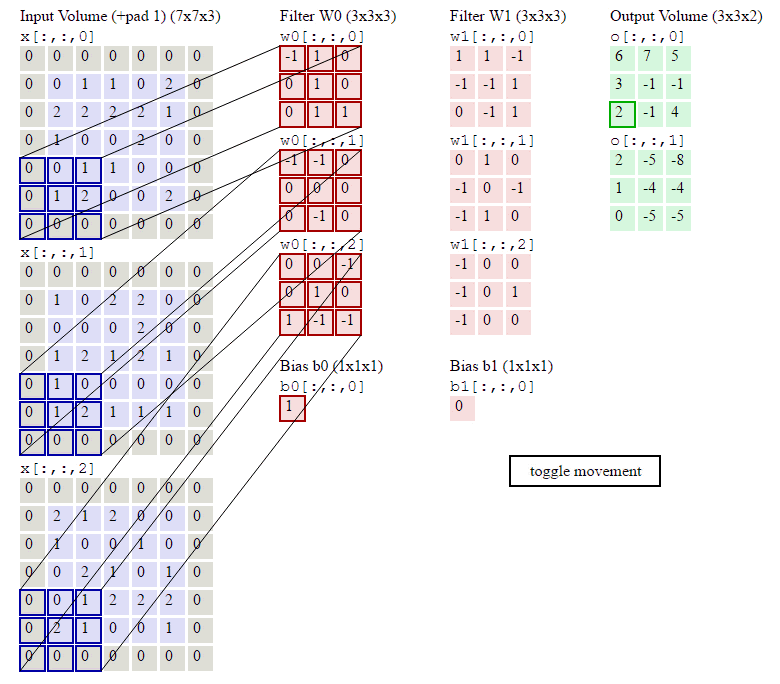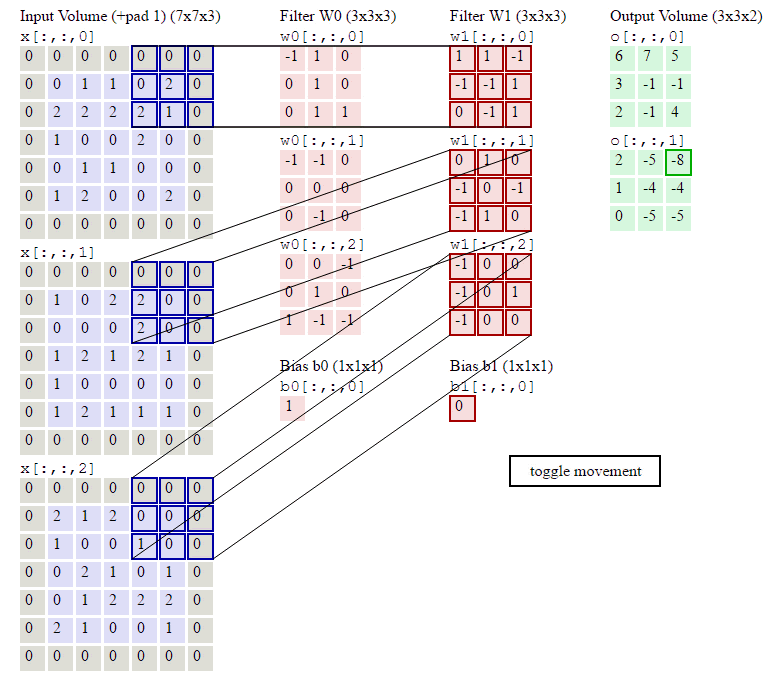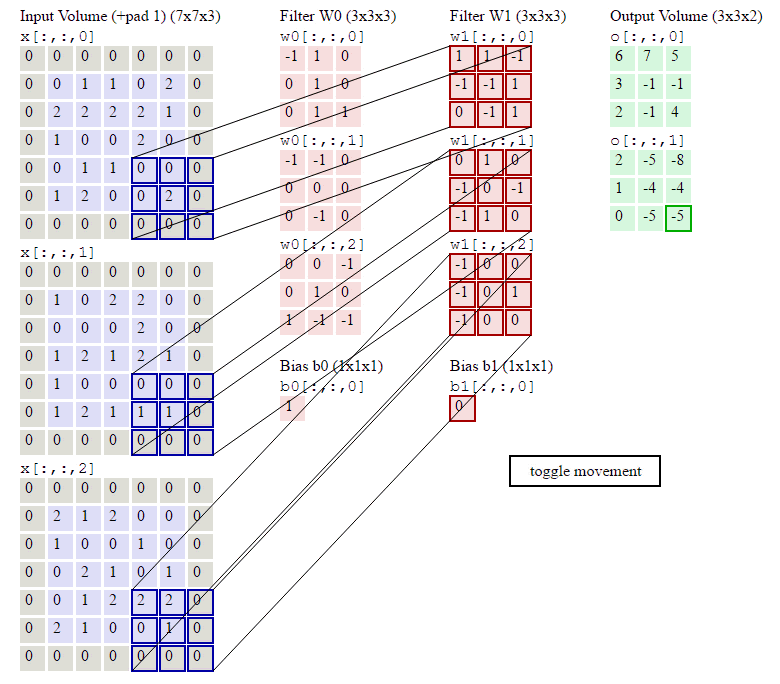
原图最外圈补0:zero padding,便于提取图像边缘的特征。
局部连接:feature map上每个值仅对应着原图的一小块区域,原图上的这块局部区域称作感受野(receptive field)。局部连接的思想,受启发于生物学里面的视觉系统,视觉皮层的神经元就是局部接受信息的。


池化(下采样):保留特征的同时压缩数据量
池化(Pooling)也叫做下采样(subsampling),用一个像素代替原图上邻近的若干像素,在保留feature map特征的同时压缩其大小。
池化的作用:
- 防止数据爆炸,节省运算量和运算时间。
- 用大而化之的方法防止过拟合、过学习。防止培养出高分低能,在考场(训练集)称霸但在社会上(测试集)混不下去的人工智障。
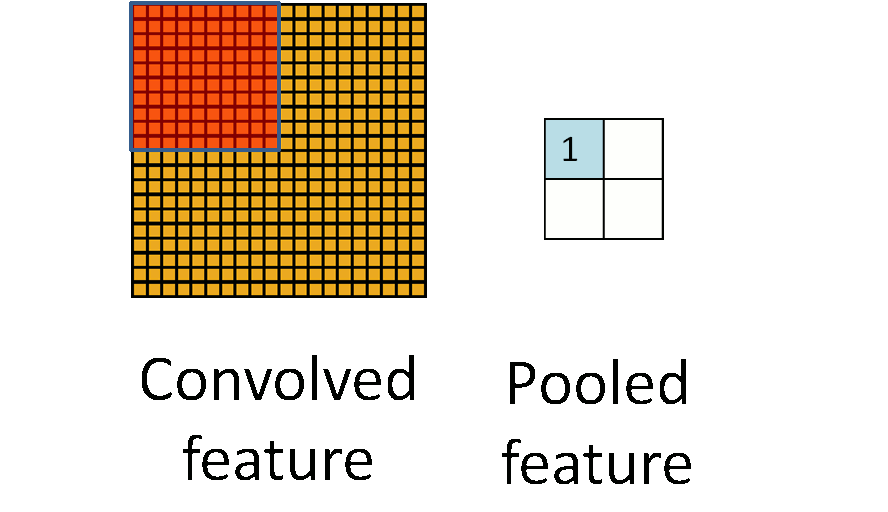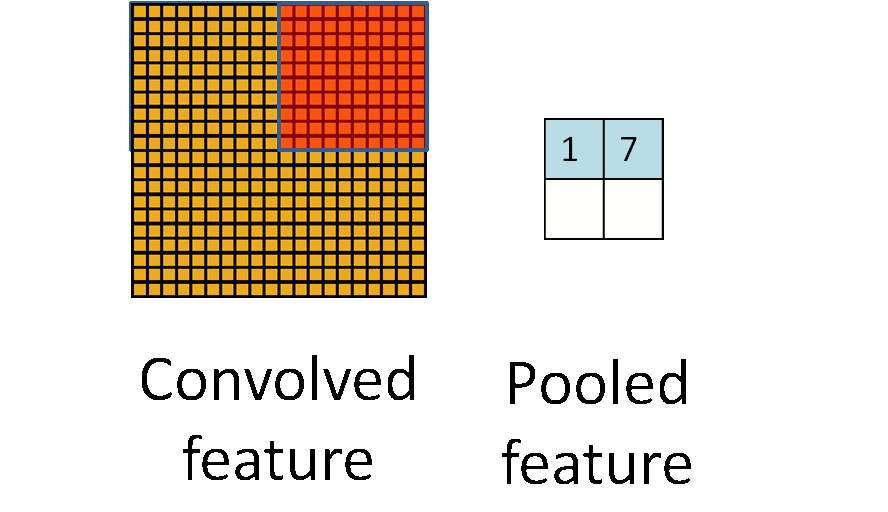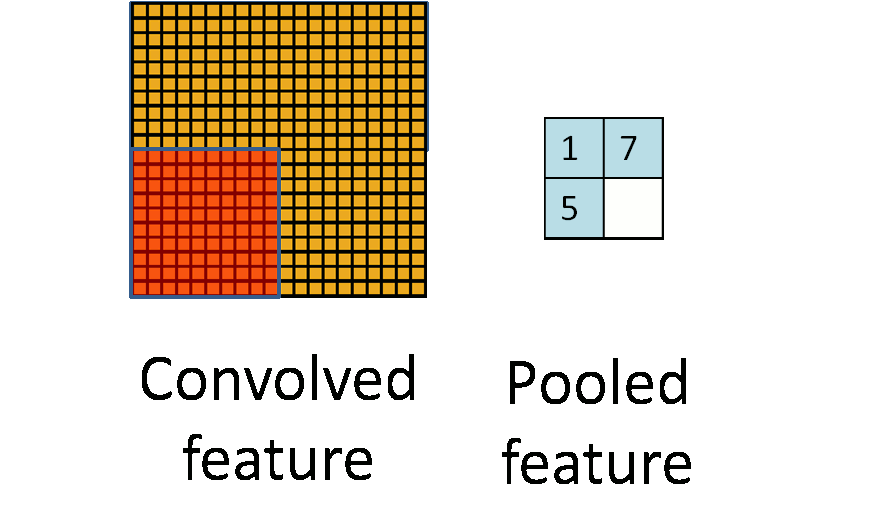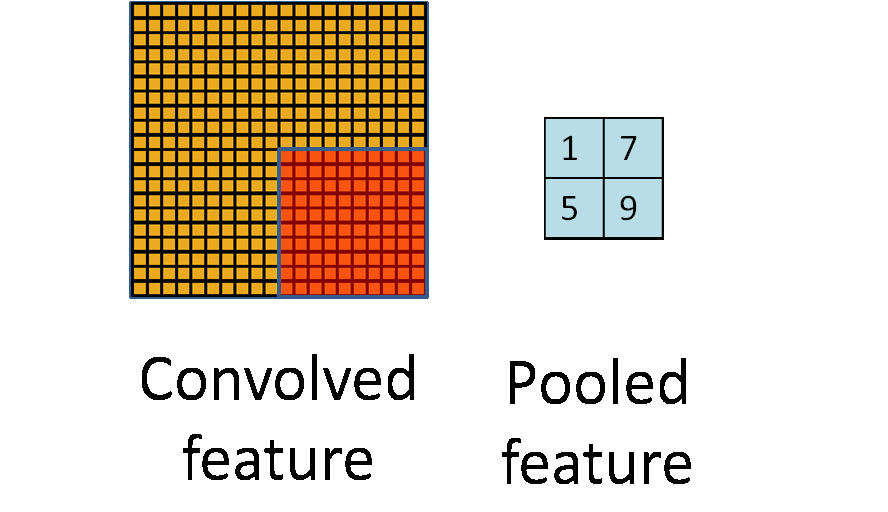
可以用这些像素的最大值作为代表,也可以用平均值作为代表。


全连接:通过加权计算得出结果

全连接层:输出的每个神经元都和上一层每一个神经元连接。
卷积核的数量、大小、移动步长、补0的圈数是事先人为根据经验指定的,全连接层隐藏层的层数、神经元个数也是人为根据经验指定的(这叫做超参数),但其内部的参数是训练出来的。
在手写字体识别可视化卷积神经网络中,有两个全连接层:
第一层全连接层:

第二层全连接层:

输出结果:

模型训练过程
损失函数
计算神经网络的推测结果与图片真实标签的差距,构造损失函数,训练的目标就是将找到损失函数的最小值。
梯度下降
将损失函数对各种权重、卷积核参数求导,慢慢优化参数,找到损失函数的最小值。

随机梯度下降
在减小损失函数的过程中,采用步步为营的方法,单个样本单个样本输入进行优化,而不是将全部样本计算之后再统一优化。虽然个别样本会出偏差,但随着样本数量增加,仍旧能够逐渐逼近损失函数最小值。

前途是光明的,道路是曲折的。——《毛泽东选集》(第四卷)《关于重庆谈判》
4、几个经典的卷积神经网络模型
LeNet-5:识别手写字体的经典卷积神经网络
LeNet-5模型是Yann LeCun教授于1998年在论文Gradient-based learning applied to document recognition中提出的,它是第一个成功应用于数字识别问题的卷积神经网络。LeNet-5模型一共有7层。
当年美国大多数银行就是用它来识别支票上面的手写数字的,它是早期卷积神经网络中最有代表性的实验系统之一。Yann LeCun教授不是中国人,是法国人,在上世纪80年代读博期间提出“人工神经网络”,但后来该理论一度被认为过时,他本人甚至被拒绝参加学术会议。LenNet-5共有7层(不包括输入层),每层都包含不同数量的训练参数。
李飞飞 imagenet 2009年开始成立ImageNet网站,采用众包模式,鼓励全世界志愿者上传、筛选、标注、整理图片数据。并每年组织ImageNet图像分类竞赛。
AlexNet:2012年ImageNet竞赛冠军
2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计,官方提供的数据模型,准确率达到57.1%,top 1-5 达到80.2%。AlexNet引爆了整个深度学习领域,更多学者开始研究卷积神经网络。

GoogLeNet:2014年ImageNet冠军

VGGNet:2014年ImageNet亚军
牛津大学的VGG模型是2014年ILSVRC竞赛的第二名,第一名是GoogLeNet。但是VGG模型在多个迁移学习任务中的表现要优于googLeNet。而且,从图像中提取CNN特征,VGG模型是首选算法。它的缺点在于,参数量有140M之多,需要更大的存储空间。但是这个模型很有研究价值。
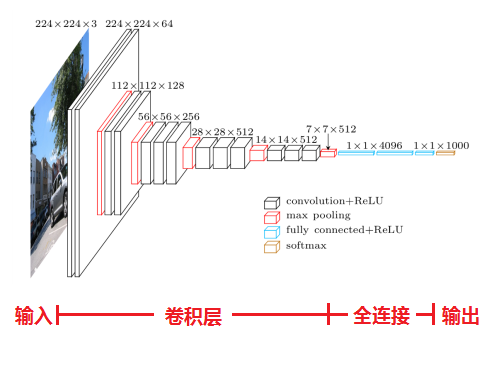
ResNet深度残差卷积神经网络
ResNet在2015年ImageNet比赛分类任务中获得第一名,在图像分类方面已超过人眼。ResNet共有152层,但它不仅仅靠深度取胜,而是通过残差学习的方法训练模型,通过“跨层抄近道”的方法减少参数数量,简单而实用。衍生出ResNet50和ResNet101旁支,Alpha Zero(只训练8个小时就打败了AlphaGo的下棋机器)也使用了ResNet。
ResNet的作者何恺明是2003年广东省理科高考状元,本科毕业于清华大学,博士毕业于香港中文大学,曾在微软亚洲研究院孙剑领导的研究组实习。何恺明在图像去雾领域也成果颇丰。


各种模型识别成功率比较

top1和top5是什么?
每次识别图片,模型都会给出它认为最像的前五个结果。top1指的是模型认为最像的确实是真实答案的成功率。top5指的是模型认为最像的前五个里有真实答案的成功率。


LeCun教授、李飞飞、Hinton、Alex、何恺明都是人工智能领域的泰山北斗,
5、一些轻松易上手的计算机视觉项目
微软年龄测试API

自动生成图片描述—captionbot

微软Custom Vision —不用写代码,三分钟开发一个图像分类应用

Github开源人脸识别项目face_recognition


在树莓派微型电脑上安装OpenCV


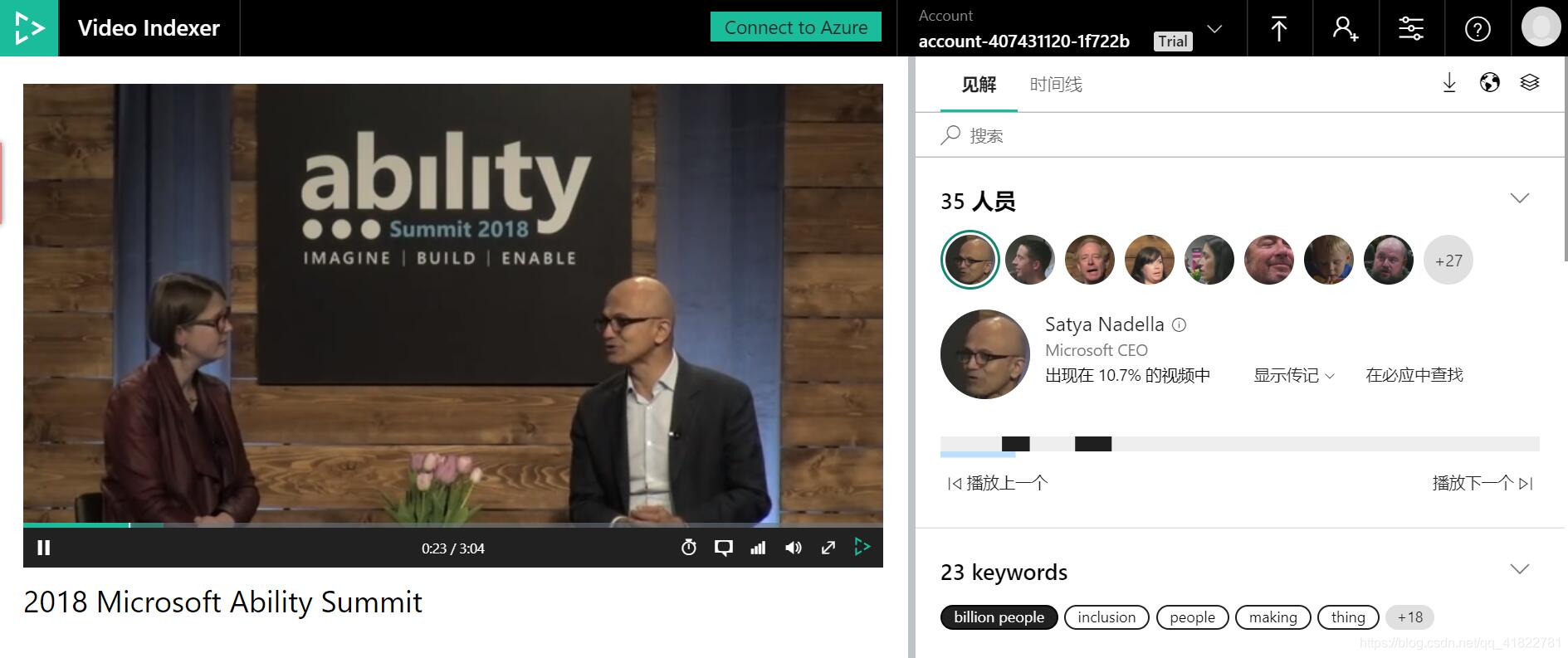
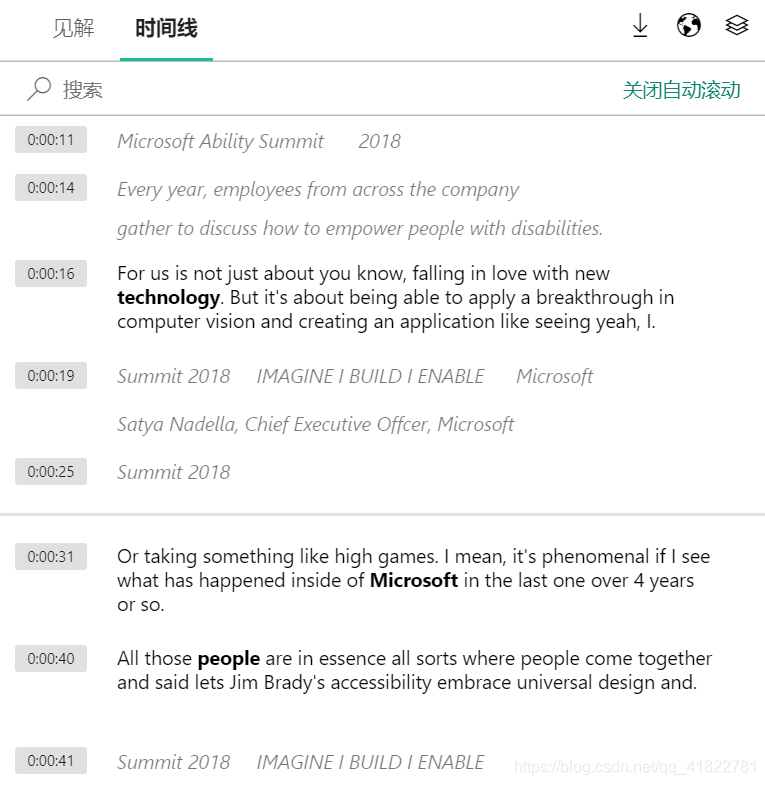
视频剪辑师的福音—微软Video Indexer
Video Indexer是非常强大的视频和音频处理工具,用户只需上传视频或音频,即可得到关键词分析、时间线字幕、视频中出现的名人及其讲话时段、情绪分析、关键帧以及带字幕和字幕翻译的视频。
6、参考文献与扩展阅读
用微软Custom Version识别水果:三分钟开发人工智能小应用
视频:How Convolutional Neural Networks work
一个时代的终结:ImageNet 竞赛 2017 是最后一届
用Microsoft Custom Vision技术识别点东西吧
作者介绍:
张子豪,同济大学在读研究生。微信公众号 人工智能小技巧 运营者。致力于用人类能听懂的语言向大众科普人工智能前沿科技。目前正在制作《说人话的人工智能视频教程》、《零基础入门树莓派趣味编程》等视频教程。西南地区人工智能爱好者高校联盟联合创始人,重庆大学人工智能协会联合创始人。充满好奇的终身学习者、崇尚自由的开源社区贡献者、乐于向零基础分享经验的引路人、口才还不错的程序员。
说人话的零基础深度学习、数据科学视频教程、树莓派趣味开发视频教程等你来看!
微信公众号:人工智能小技巧
知乎专栏:人工智能小技巧
Github代码仓库:TommyZihao
个人主页:www.python666.org
同济大学开源软件协会
同济大学微软学生俱乐部
西南人工智能爱好者联盟
重庆大学人工智能协会
