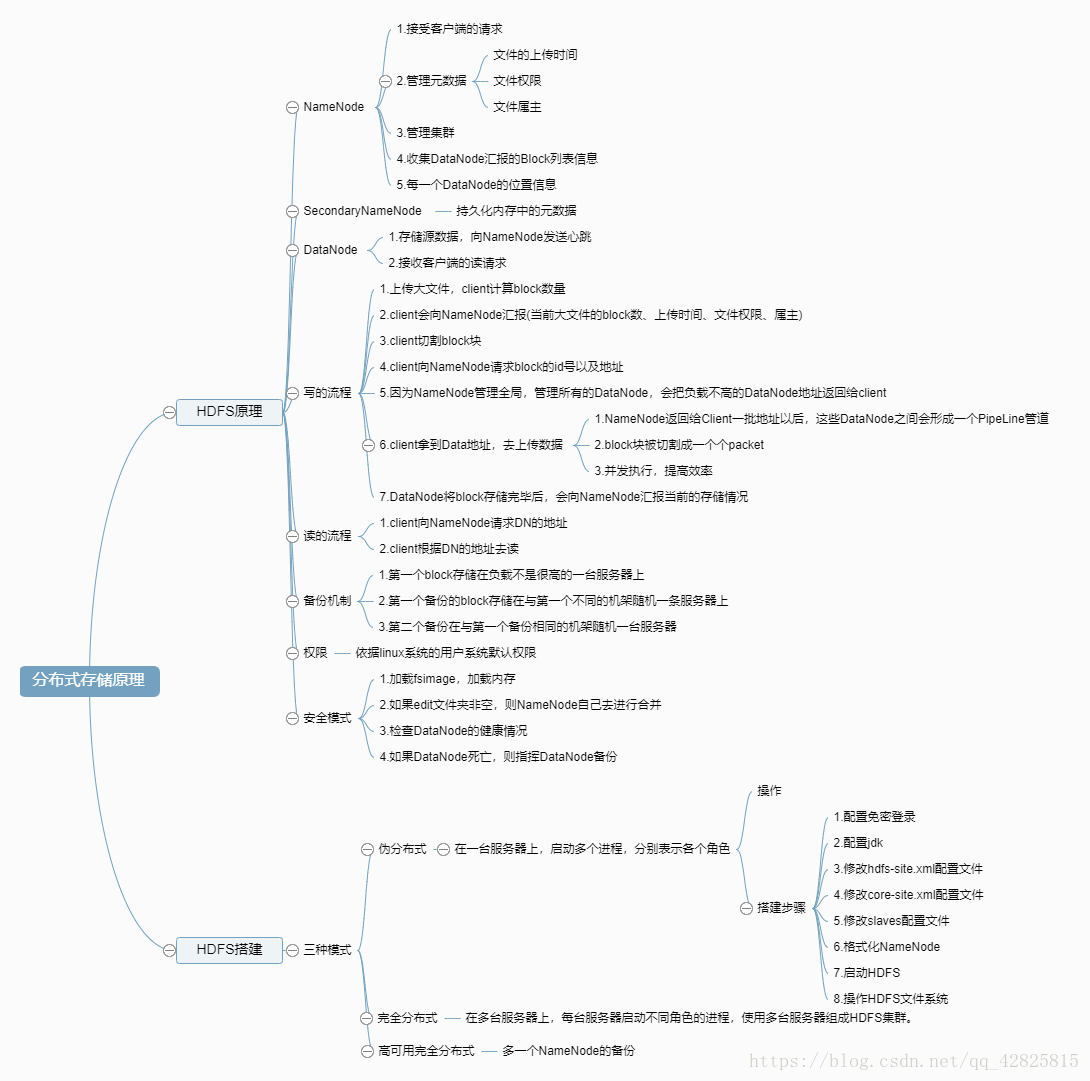
一、HDFS原理
- 当HDFS集群启动之时,DataNode会向NameNode发送信息,包括Block存储位置,DataNode地址。
- Client向NameNode汇报当前上传文件的信息(Block数量、文件上传时间、文件权限、拥有着)。
2.1 Client将大文件切割成一个个的block块(以字符为单位进行切割)。 - Client向NameNode发送请求,获得BlockId号,存储Block。
3.1 Client拿到BlockId号和DataNode地址开始上传文件。
1)NameNode返回给Client一批地址后,这些DataNode之间形成一个PipeLine管道。
2)Client把Block块切割成一个个Packet(64K)不断地往管道中输送。这样可以实现并发执行存储 ,从而提高上传效率。
1.数据备份机制
考虑到数据安全问题,需要给数据进行备份,默认有两个副本文件。
- 第一个Block存储在负载不是很高的一台服务器上。
- 第一个备份文件Block存储在与第一个Block不同的机架随机一台服务器上。
- 第二个备份文件存储在与第一个备份文件相同机架上的随机一台服务器。
2.持久化机制
防止系统故障导致数据丢失,故采用持久化机制。
- 在NameNode启动的过程中,生成edits和fsimage两个空文件;
- SecondaryNameNode拉取edits文件进行重演,从而产生元数据,然后元数据与fsimage合并完成后,将新的fsimage(fsimage.CheckPoint)推送给NameNode;
- 在SecondaryNameNode读取edits文件的同时,NameNode会创建edits.new这个文件,来存储SecondaryNameNode在合并过程中,其他数据的操作。
3.安全模式
安全模式是HDFS所处的一种特殊状态,在这种状态下,文件系统只接受读数据请求(能查看文件目录,但是无法读取文件内容),而不接受删除、修改等变更请求。
安全模式下NameNode所做的工作:
- 加载fsimage,加载到内存中。
- 若edits文件不为空,那么namenode自己来合并。
- 检查DataNode是否存活。
- 若DataNode死亡,则指挥DataNode进行备份操作。
4.NameNode的作用
- 接收客户端的请求。
- 管理元数据(文件的上传时间、文件权限、文件属主)。
- 管理集群。
- 收集DataNode汇报的Block列表信息。
- 每一个DataNode的位置信息。
5.DataNode作用
- 存储源数据,向NameNode发送心跳。
- 接收客户端的读请求。
6.HDFS写流程
- client计算大文件的block数量;
- client会向NameNode汇报(当前大文件的block数,当前大文件属主、权限,文件上传时间);
- client切割block;
- client向NameNode请求block块的Id号以及地址;
- 由于NameNode掌控全局,管理所有的DataNode,所以它将负载不高的DataNode地址返回给client;
- client拿到地址后,找到Data去上传数据;
- Data将block存储完毕后,会向NameNode汇报当前的存储情况。
7.HDFS读流程
- client请求NameNode获得block的位置信息,因为NameNode里存放了block位置信息的元数据。
- Namenode返回所有block的位置信息,并将这些信息返回给客户端。
- 客户端拿到block的位置信息读取block信息,采用就近原则。
二、HDFS的搭建
搭建集群的三种模式:
1.伪分布式:在一台服务器上,启动多个进程,分别表示各个角色。
2.完全分布式:在多台服务器上,每台服务器启动不同角色的进程,使用多台服务器组成HDFS集群。
3.高可用的完全分布式:多一个NameNode的备份。