课程:《程序设计与数据结构(下)》
班级:1723
姓名: 王志伟
学号:20172309
实验教师:王志强老师
实验日期:2018年11月2日
必修/选修: 必修
实验内容:
实验一:实现二叉树。
1.参考教材p212,完成链树LinkedBinaryTree的实现(getRight,contains,toString,preorder,postorder).
2.用JUnit或自己编写驱动类对自己实现的LinkedBinaryTree进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息.
3.课下把代码推送到代码托管平台.
实验二:前序、中序遍历构造二叉树。
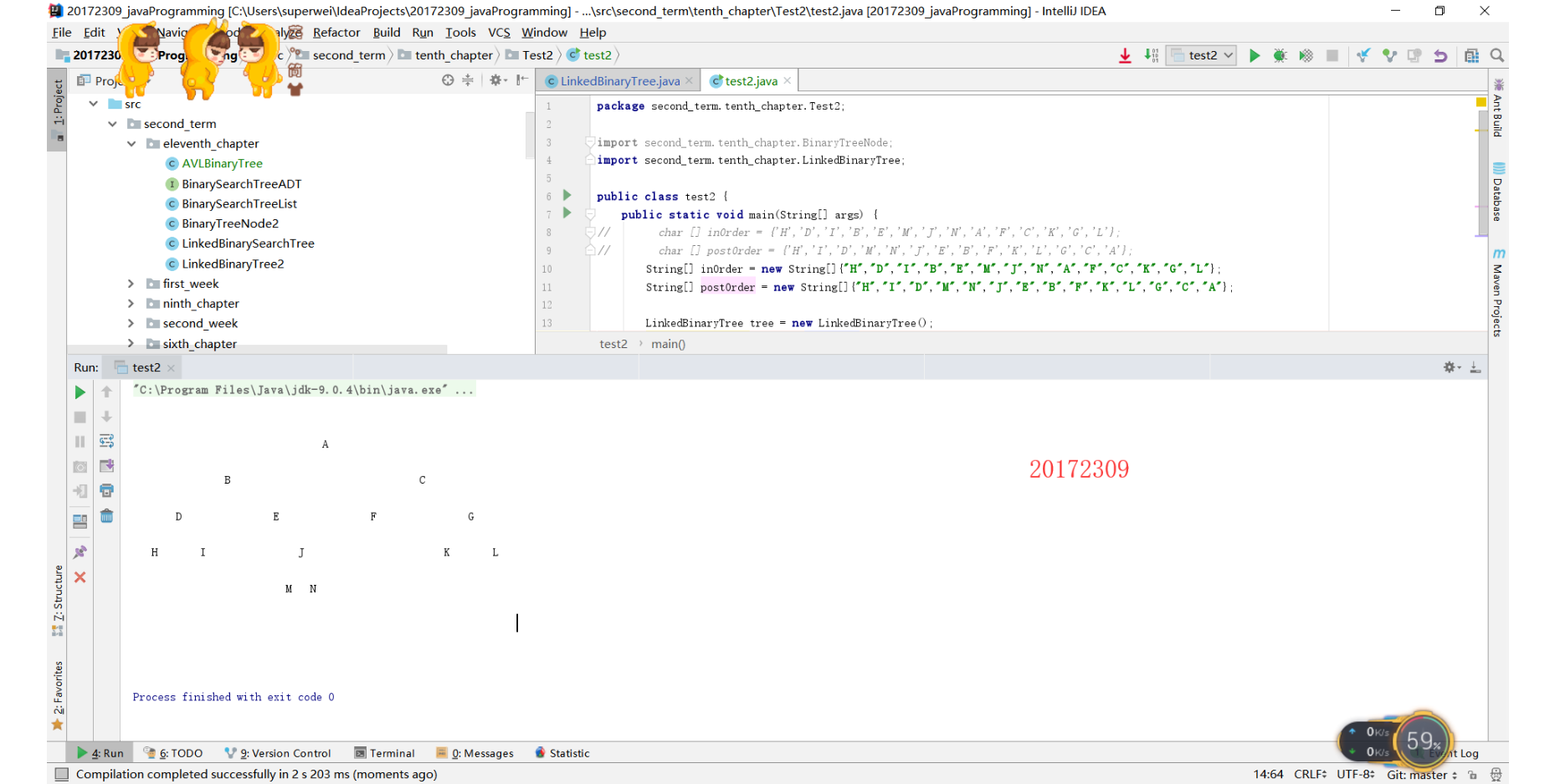
1.基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二㕚树的功能,比如给出中序HDIBEMJNAFCKGL和后序ABDHIEJMNCFGKL,构造出附图中的树.
2.用JUnit或自己编写驱动类对自己实现的功能进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息.
3.课下把代码推送到代码托管平台.
实验三:理解决策树。
1.自己设计并实现一颗决策树
2.提交测试代码运行截图,要全屏,包含自己的学号信息
3.课下把代码推送到代码托管平台
实验四:运用表达式树。
1.完成PP11.3
2.提交测试代码运行截图,要全屏,包含自己的学号信息
3.课下把代码推送到代码托管平台
实验五:实现二叉查找树。
1.完成PP11.3
2.提交测试代码运行截图,要全屏,包含自己的学号信息
3.课下把代码推送到代码托管平台
实验六:红黑树分析。
参考点击这里对Java中的红黑树(TreeMap,HashMap)进行源码分析,并在实验报告中体现分析结果。
(文件位于:C:\Program Files\Java\jdk-11.0.1\lib\src\java.base\java\util)
实验过程及结果:
实验一:
这个实验是要求我们实现几个方法,然后进行测试。
- 1.得到右子树:getright()
public LinkedBinaryTree<T> getRight()
{
return right;
}
//这个类是一个二叉树类,里面属性left、right,分别代表左子树和右子树,要想得到右子树,直接return right;即可!2.是否含有元素的方法:contains(T targeElement)
这里编写了两个方法,值得注意的是:一个是公有的(public),另一个是私有的(private)。说明公有的方法用于外部类调用,而这个私有类的方法被用于用于公有方法。
public boolean contains(T targetElement)
{
return findNode(targetElement,root)!=null;//调用私有方法findNode()
}
private BinaryTreeNode<T> findNode(T targetElement,
BinaryTreeNode<T> next)
{//这个方法在树中查找目标元素,没找到时,分别在其左右子树中查找、**运用了递归**!
if (next == null)
return null;
if (next.getElement().equals(targetElement))
return next;
BinaryTreeNode<T> temp = findNode(targetElement, next.getLeft());
if (temp == null)
temp = findNode(targetElement, next.getRight());
return temp;
}输出的方法:toString()
这个输出方法通过构建两个无序列表,分别应于放置结点和对应的级数,好用于计算后面输出的空格数。其中最难的是每一层相邻的两个结点之间的空格数。
public String toString()
{
UnorderedListADT<BinaryTreeNode<T>> nodes =
new UnorderedListArrayList<BinaryTreeNode<T>>();
UnorderedListADT<Integer> levelList =
new UnorderedListArrayList<Integer>();
BinaryTreeNode<T> current;
String result = "";
int printDepth = this.getHeight();
int possibleNodes = (int)Math.pow(2, printDepth + 1);
int countNodes = 0;
nodes.addToRear((BinaryTreeNode<T>) root);
Integer currentLevel = 0;
Integer previousLevel = -1;
levelList.addToRear(currentLevel);
while (countNodes < possibleNodes)
{
countNodes = countNodes + 1;
current = nodes.removefirst();
currentLevel = levelList.removefirst();
if (currentLevel > previousLevel)
{
result = result + "\n\n";
previousLevel = currentLevel;
for (int j = 0; j < ((Math.pow(2, (printDepth - currentLevel))) - 1); j++)
result = result + " ";
}
else
{
for (int i = 0; i < ((Math.pow(2, (printDepth - currentLevel + 1)) - 1)) ; i++)
{
result = result + " ";
}
}
if (current != null)
{
result = result + (current.getElement()).toString();
nodes.addToRear(current.getLeft());
levelList.addToRear(currentLevel + 1);
nodes.addToRear(current.getRight());
levelList.addToRear(currentLevel + 1);
}
else {
nodes.addToRear(null);
levelList.addToRear(currentLevel + 1);
nodes.addToRear(null);
levelList.addToRear(currentLevel + 1);
result = result + " ";
}
}
return result;
} 前序、后序遍历方法:preOrder()
前序遍历的顺序是:先遍历该结点,然后是他们的孩子。
因此用伪代码表示为://详细代码见here
Visit node;//前序遍历 preOrder(leftChild); preOrder(rightChild);
postOrder(leftChild); postOrder(rightChild); visit node;//后序遍历
运行结果:

实验二:
1.实验二是说给定咋们中序遍历和后序遍历的结果,让后让咋们生成一棵树。科普:当给定前序和后序遍历会结果得不到一棵树,因为分不清左右结点
2.我们基于一个事实:中序遍历一定是 { 左子树节点集合 },root,{ 右子树节点集合 }。
3.后序序遍历的作用就是找到每颗子树的root位置。
public void generateTree(T[] A,T[] B){//A、B两个数组分别是放前序、后序遍历结果的。
BinaryTreeNode<T> temp = getTree(A, B);
root=temp;
}
private BinaryTreeNode<T> getTree(T[] inOrder,T [] postOrder){
int length = postOrder.length;
T rootElement = postOrder[postOrder.length-1];
BinaryTreeNode<T> temp = new BinaryTreeNode<T>(rootElement);
if (length==1)
return temp;
else{
int index = 0;
while (inOrder[index]!=rootElement)
index++;
if (index>0){//分界结点的左边又可以生成一个子中序遍历数组和后序遍历数组。之后运用递归。
T [] leftInOrder = (T[])new Object[index];
for(int i=0;i<leftInOrder.length;i++)
leftInOrder[i]=inOrder[i];
T [] leftPostOrder = (T[])new Object[index];
for (int i=0;i<leftPostOrder.length;i++)
leftPostOrder[i] = postOrder[i];
temp.setLeft(getTree(leftInOrder,leftPostOrder));
}
if (length-index-1>0){//右边也一样,生成子两个数组,运用递归。
T [] rightInOrder = (T[])new Object[length-index-1];
for (int i=0;i<length-index-1;i++)
rightInOrder[i]=inOrder[i+index+1];
T [] rightPostOrder = (T[])new Object[length-index-1];
for (int i=0;i<length-index-1;i++)
rightPostOrder[i]=postOrder[i+index];
temp.setRight(getTree(rightInOrder,rightPostOrder));
}
}
return temp;
}
- 运行结果:
实验三:
- 这个实验就是自己制作一棵决策树,我们只要修改TXT文件就OK!
- 修改后的文件为:
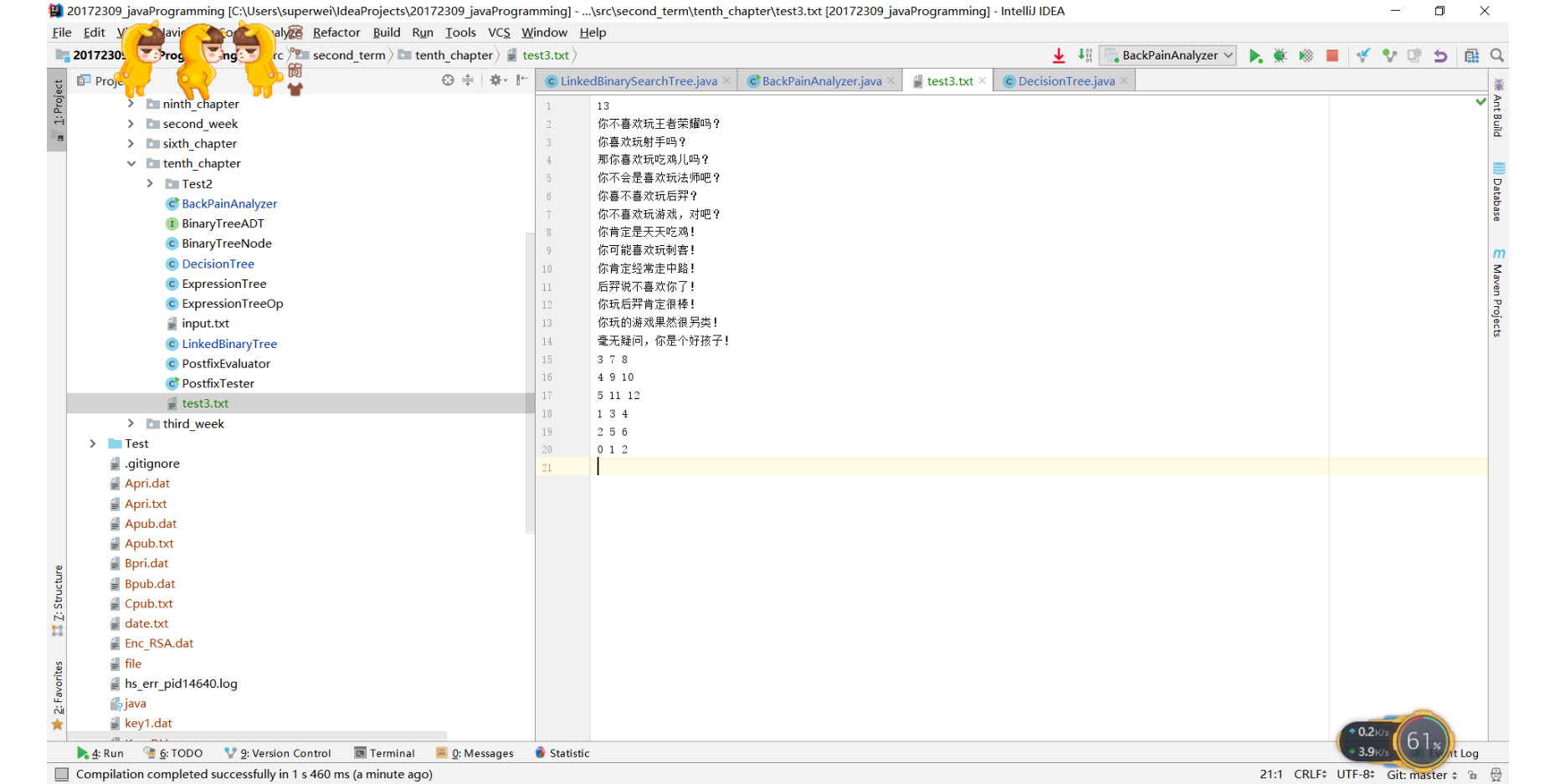
运行结果为:

实验四:
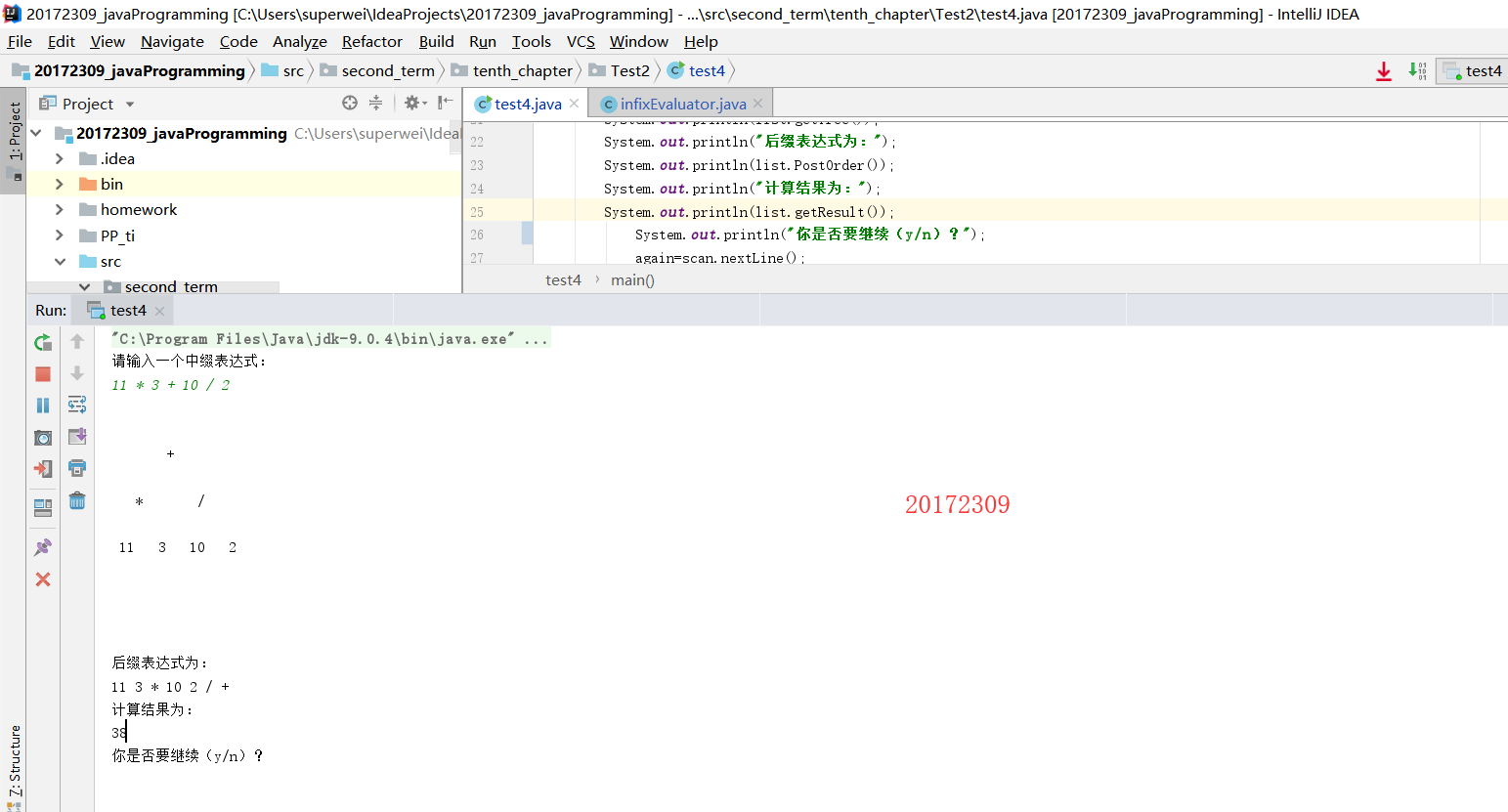
- 该实验是要求我们用树的性质将一个中缀表达式转换成后缀表达式,并得到计算结果。
- 因此我们大概可以想到:它的答题构架是这样的
public ExpressionTree getPostfixTree(String expression){//传进去的是一个中缀表达式
。。。一大串代码。。。
return EXpressionTree;//经过一大串代码得到一颗表达式树。
}- 经过我
TM打十把王者的时间,把它写好了。
ExpressionTree operand1,operand2;
char operator;
String tempToken;
Scanner parser = new Scanner(expression);
while(parser.hasNext()){
tempToken = parser.next();
operator=tempToken.charAt(0);
if ((operator == '+') || (operator == '-') || (operator=='*') ||
(operator == '/')){
if (ope.empty())
ope.push(tempToken);//当储存符号的栈为空时,直接进栈
else{
String a =ope.peek()+"";//因为当ope.peek()='-'时,计算机认为ope.peek()=='-'为false,所以要转化为string 使用equals()方法
if (((a.equals("+"))||(a.equals("-")))&&((operator=='*')||(operator=='/')))
ope.push(tempToken);//当得到的符号的优先级大于栈顶元素时,直接进栈
else {
String s = String.valueOf(ope.pop());
char temp = s.charAt(0);
operand1 = getOperand(treeExpression);
operand2 = getOperand(treeExpression);
treeExpression.push(new ExpressionTree
(new ExpressionTreeOp(1, temp, 0), operand2, operand1));
ope.push(operator);
}//当得到的符号的优先级小于栈顶元素或者优先级相同时时,数字栈出来两个运算数,形成新的树进栈
}
}
else
treeExpression.push(new ExpressionTree(new ExpressionTreeOp
(2,' ',Integer.parseInt(tempToken)), null, null));
}
while(!ope.empty()){
String a = String.valueOf(ope.pop());
operator = a.charAt(0);
operand1 = getOperand(treeExpression);
operand2 = getOperand(treeExpression);
treeExpression.push(new ExpressionTree
(new ExpressionTreeOp(1, operator, 0), operand2, operand1));
}
return treeExpression.peek();运行结果为:
生成树后,我们发现把这颗树直接后序遍历就可以得到后缀表达式。详细代码click here
实验五:
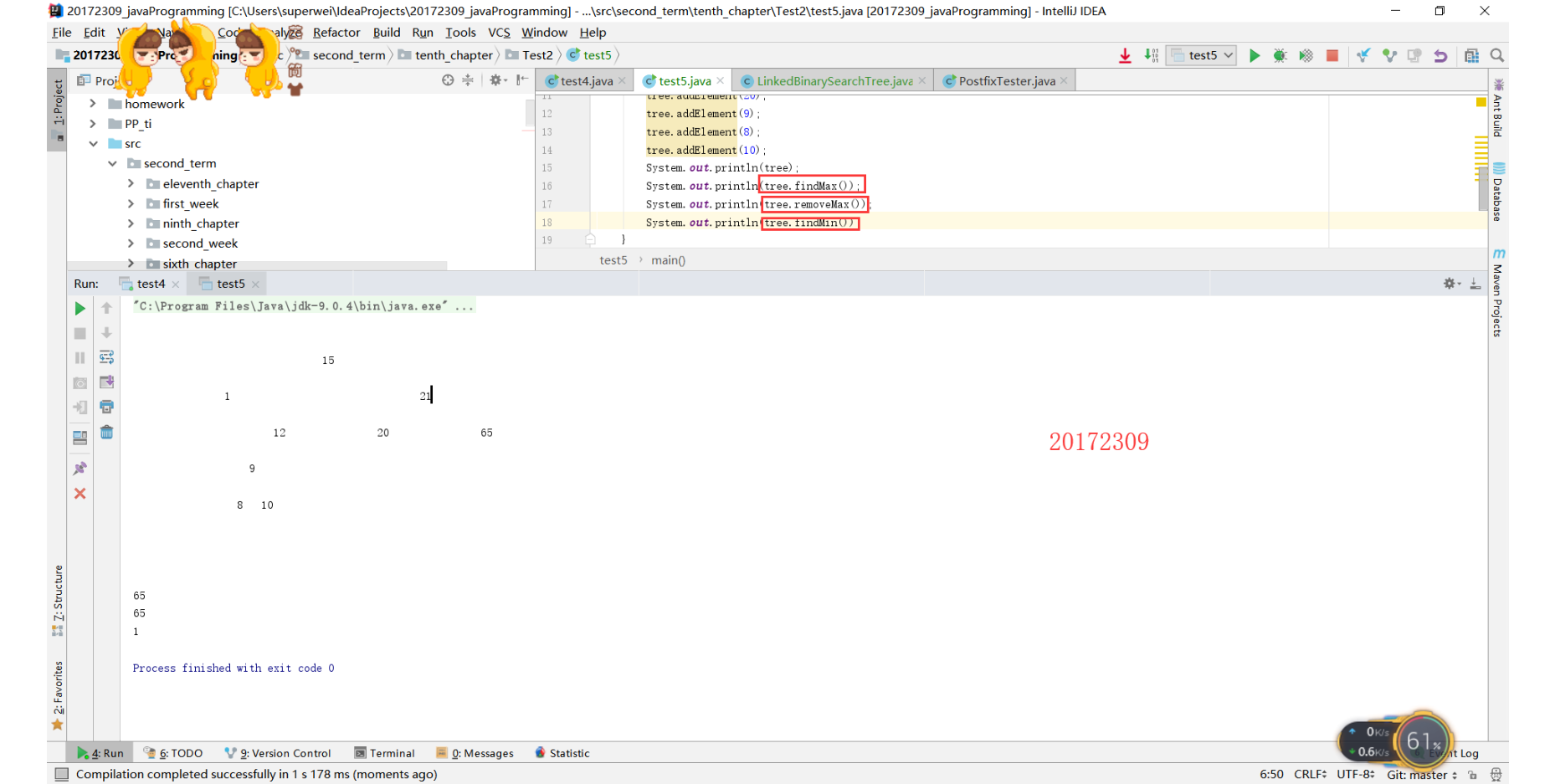
- 实验要求为完成findMax()、removeMax()、findMin()方法。
- 我们必须明白,二叉查找树具有左子树小于父结点,右子树大于或等于父结点的性质。因此树的最左侧会放置最小元素、而最右侧会放置最大元素。
代码如下:
去除最小元素方法。
public T removeMin() throws EmptyCollectionException
{
T result = null;
if (isEmpty())
throw new EmptyCollectionException("LinkedBinarySearchTree");
else
{
if (root.left == null)
{
result = root.element;
root = root.right;
}
else
{
BinaryTreeNode2<T> parent = root;
BinaryTreeNode2<T> current = root.left;
while (current.left != null)
{
parent = current;
current = current.left;
}
result = current.element;
parent.left = current.right;
}
modCount--;
}
return result;
}去除最大元素方法。
public T removeMax() throws EmptyCollectionException
{
T result= null;
if (isEmpty())
throw new EmptyCollectionException("LinkedBinarySearchTree!");
else{
if (root.right == null){
result = root.element;
root=root.left;
}
else{
BinaryTreeNode2<T> parent = root;
BinaryTreeNode2<T> current = root.right;
while(current.right != null){
parent = current;
current = current.right;
}
result = current.element;
parent.right = current.left;
}
modCount--;
}
return result;
}找到最大元素方法。
public T findMax() throws EmptyCollectionException {
if (isEmpty())
System.out.println("BinarySearchTree is empty!");
return findmax(root).element;
}- 实验结果:
实验六:
实验过程中遇到的问题:
- 问题一.为什么为实现某一个功能,一般都写两个方法:Public、Private方法,然后我们用就调用这个pubic方法?比如上面的实验二中的generateTree()方法与getTree()方法?
- 经过查资料知道这样做主要有两个好处:
- 一. 从代码上看,以上面的实验二方法为例、两者的传入数据虽然相同,都是两个数组。但是他们的返回值不同,也就是说:有返回值的方法,使用该方法时能够得到一些类型的数据再来利用。
- 二. 从整体上看,这是一种保护机制,不让自己这个类以外的方法去随便使用这个类的数据,可以保护他的数据,只能通过调用自己类的方法去操纵这些数据。这样会很安全。
- 经过查资料知道这样做主要有两个好处:
- 问题二.实验三TXT文件中的数字是什么东西?
- 经过与侯泽洋讨论才知道,这个东西是用于构建树的,而数字是它们每个数字的索引。
像是这样:
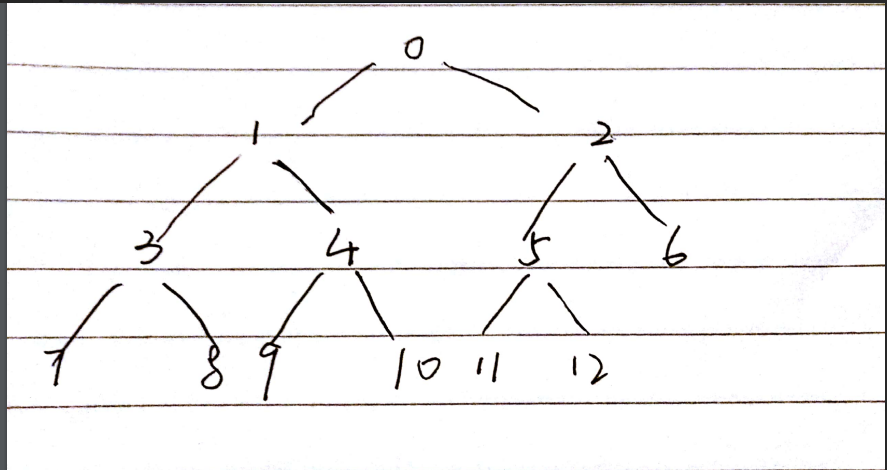
还有一个问题就是为什么他的顺序是
3 7 8 4 9 10 5 11 12 1 3 4 2 5 6 0 1 2//这样的0 1 2
2 5 6
1 3 6
5 11 12
4 9 10
3 7 8//而非得是倒着来呢?- 其实这样是很合理的,因为我们构建一颗决策树时,是先构建子树,然后再把子树联合起来的。所以是倒着来的。
- 经过与侯泽洋讨论才知道,这个东西是用于构建树的,而数字是它们每个数字的索引。
- 问题三及问题四.进行实验四的时候出现:
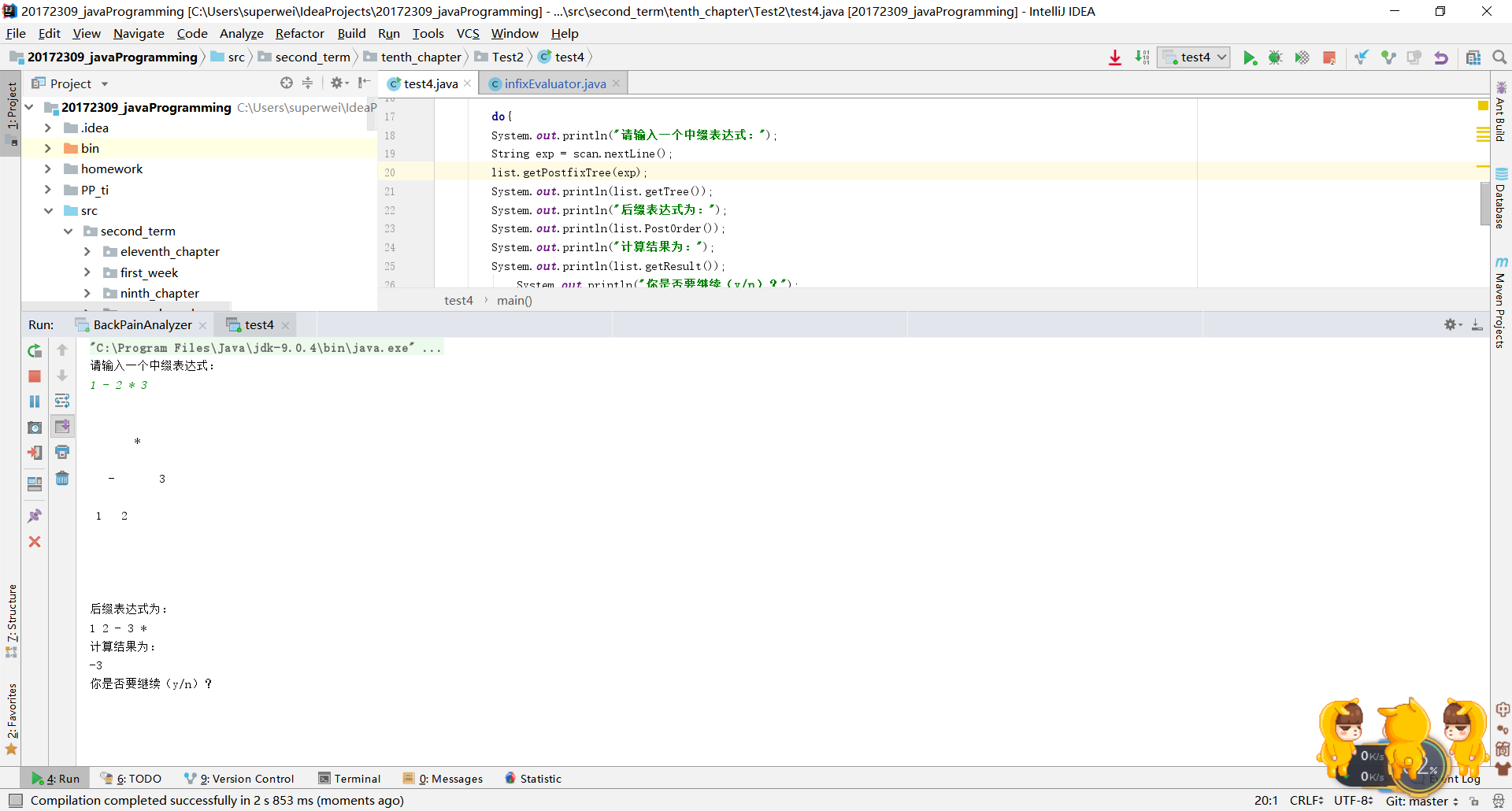
-然后经过自习调试才发现是判断条件出现了问题:当ope.peek()=“+”时,他认为ope.peek()=="+"为false,我也不知道怎么回事!
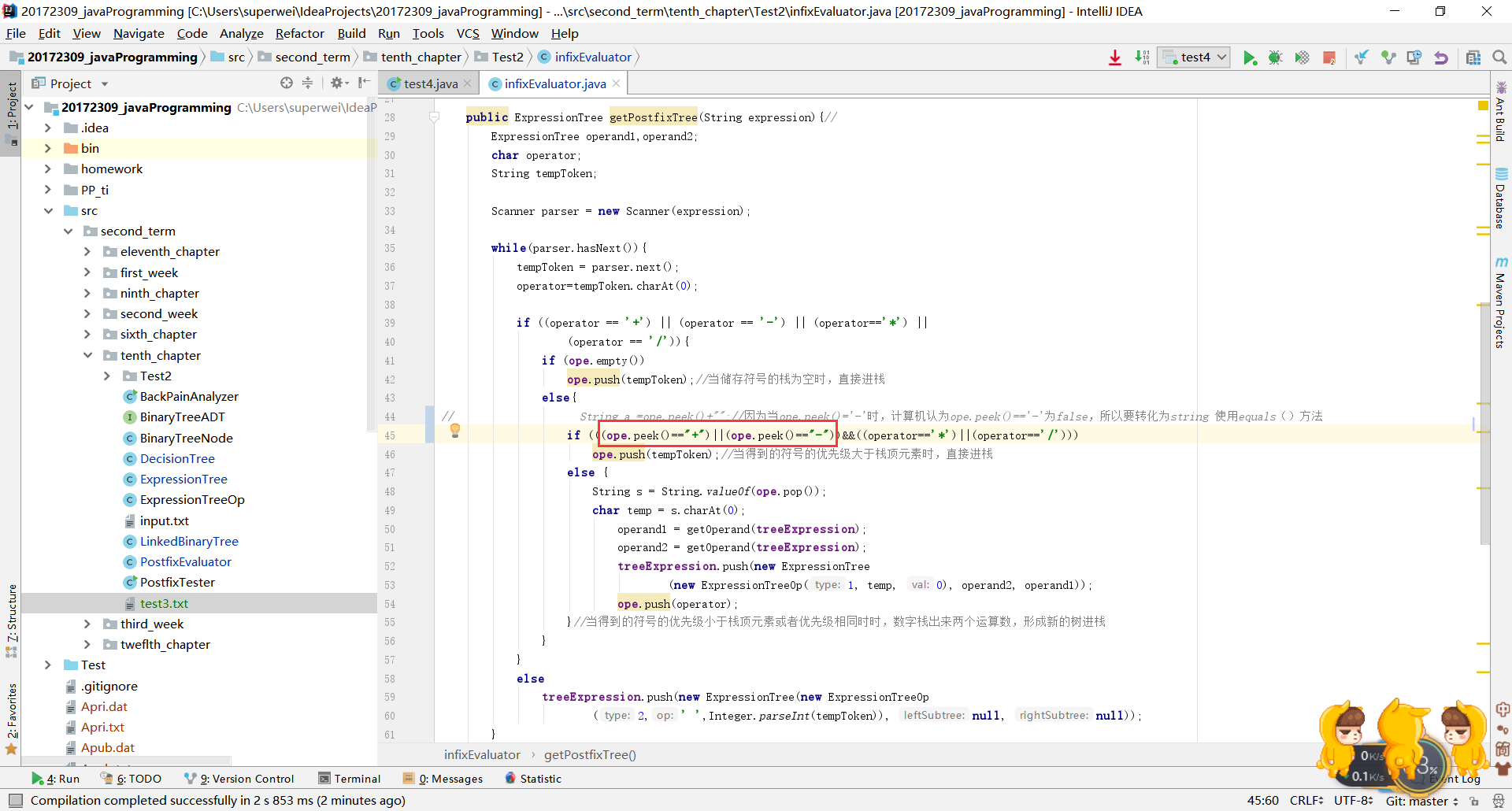
经过修改:ope.Peek().equals("+")解决了这个问题。

- 但是在后面又出现了问题:结果表明又是符号优先级出现问题!但是我保证、后面的答案也证明我的逻辑没错!

- 经过调试,还是发现那个判断条件出现了问题!!!烦的一批!!!
- 之后我直接把所有的数据转换成String类型再来判断、才解决了问题!
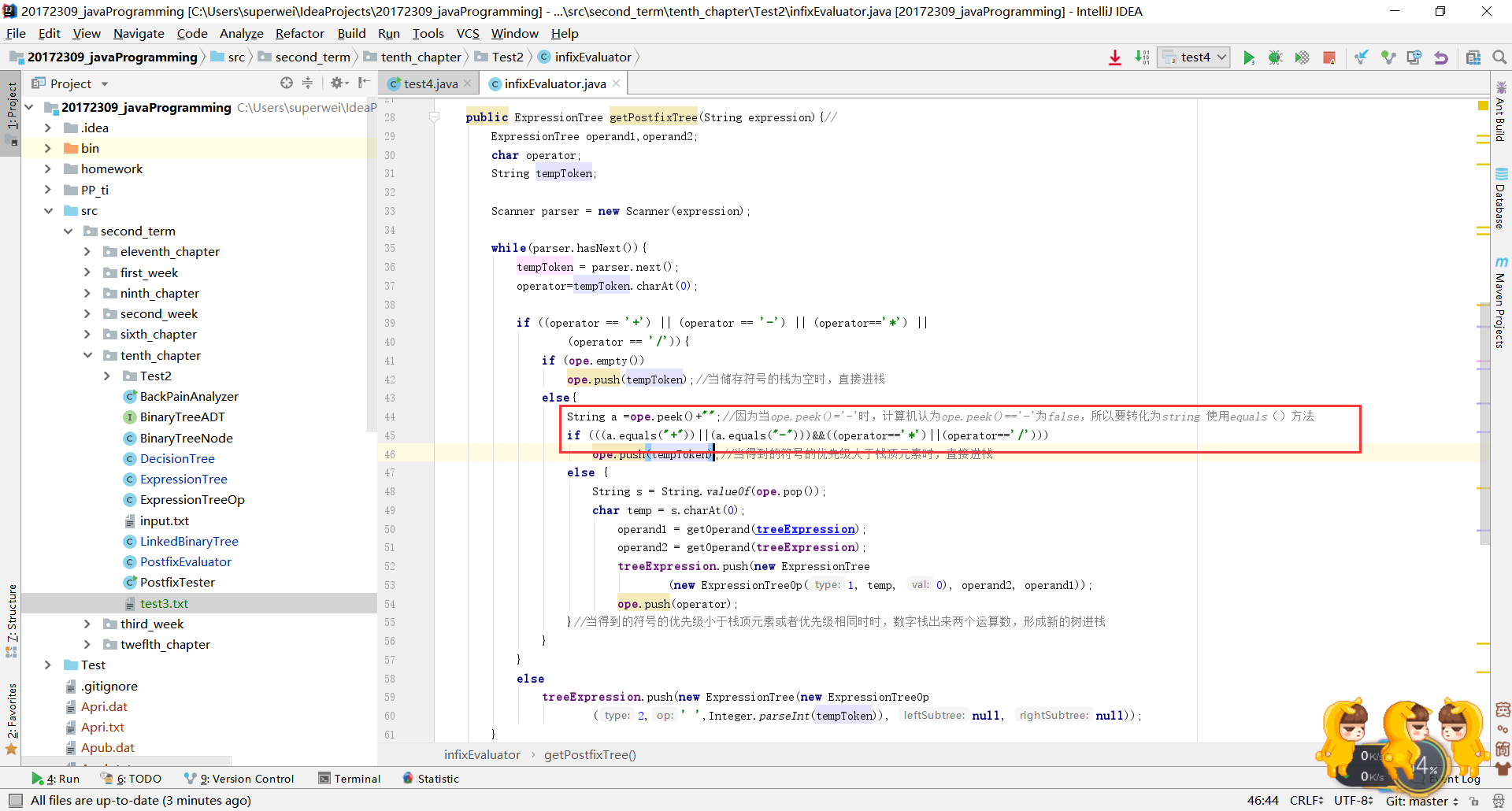
- 之后我直接把所有的数据转换成String类型再来判断、才解决了问题!
收获感悟
这一章的实验虽然只有几个难一点的,比如实验四和实验六,但确实让人更头疼!他别是实验四,看到在实验提交前好多人都不管在什么课上都在想怎么做!然后自己在三四小时就把它解决了,想想还是可以的!也许这就是不间断地思考一个问题的好处吧!