服务新数据节点
当原有的数据节点容量达不到存储数据需求,需要在原有集群基础上动态添加新的数据节点
-
准备一台虚拟机
-
修改ip,主机名称.以及hosts
-
配置jdk以及hadoop的环境
-
修改xcall和xsync文件,增加新节点,同步ssh
修改xcall
修改xsync
设置免密码登录ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa将生成的公钥拷贝到主机testnote1里 .ssh目录下 authorized_keys
scp authorized_keys root@testnote04:`pwd`同步集群
xsync authorized_keys -
删除原来HDFS文件系统的日志文件以及 data
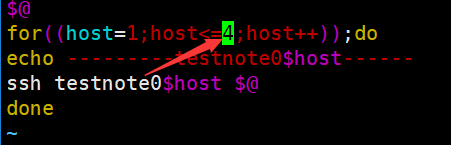
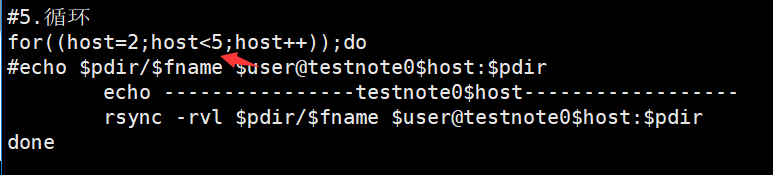
具体准备:
6. 在 namenode 的/opt/module/hadoop-2.7.2/etc/hadoop 目录下创建 dfs.hosts 文件
[root@testnote01 .ssh]# cd /opt/module/hadoop-2.7.2/etc/hadoop/
[root@testnote01 hadoop]# touch dfs.hosts
[root@testnote01 hadoop]# vim dfs.hosts
testnote01
testnote02
testnote03
testnote04
-
在 namenode 的 hdfs-site.xml 配置文件中增加 dfs.hosts 属性即testnote01的主机上
<property> <name>dfs.hosts</name> <value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value> </property> -
刷新namenode
扫描二维码关注公众号,回复: 4011486 查看本文章
[root@testnote01 hadoop]# hdfs dfsadmin -refreshNodes Refresh nodes successfu -
更新resourcemanager节点
[root@testnote01 hadoop]# yarn rmadmin -refreshNodes 18/11/07 03:54:31 INFO client.RMProxy: Connecting to ResourceManager at testnote02/192.168.18.51:8033 -
在namenode的slaves文件中增加新的主机名称
[root@testnote01 hadoop]# cat slaves testnote01 testnote02 testnote03 testnote04 -
在单独命令启动新的数据节点和节点管理器
[root@testnote04 .ssh]# hadoop-daemon.sh start datanode starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-testnote04.out [root@testnote04 .ssh]# yarn-daemon.sh start nodemanager starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-testnote04.out
访问主页:http://testnote01:50070/dfshealth.html#tab-overview
点击liveVies
http://testnote01:50070/dfshealth.html#tab-datanode

退役旧数据节点
1)在 namenode 的/opt/module/hadoop-2.7.2/etc/hadoop 目录下创建 dfs.hosts.exclude 文件
[root@testnote01 hadoop-2.7.2]# vim dfs.hosts.exclude
[root@testnote01 hadoop-2.7.2]# cat dfs.hosts.exclude
testnote04
/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.exclude 在这个目录下
-
在namenode的hdfs-site.xml的配置文件中增加dfs.hosts.exclude
[root@testnote01 hadoop-2.7.2]# vim etc/hadoop/hdfs-site.xml <property> <name>dfs.hosts.exclude</name> <value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.exclude</value> </property> -
刷新namenode,刷新resourcemanager
[root@testnote01 hadoop-2.7.2]# hdfs dfsadmin -refreshNodes Refresh nodes successful [root@testnote01 hadoop-2.7.2]# yarn rmadmin -refreshNodes 18/11/07 04:39:33 INFO client.RMProxy: Connecting to ResourceManager at testnote02/192.168.18.51:8033
4)检查 web 浏览器,退役节点的状态为 decommission in progress(退役中),说明数据节点正在复制块到其他节点。

- 等待退役节点状态为 decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。

注意:如果副本数是3,服务节点小于等于3,是不能退役成功的,需要修改副本数后才能退役
-
停止节点
[root@testnote04 .ssh]# hadoop-daemon.sh stop datanode stopping datanode [root@testnote04 .ssh]# yarn-daemon.sh stop nodemanager stopping nodemanager -
从include文件中删除退役节点,再运行刷新节点的命令
(1)从 namenode 的 dfs.hosts 文件中删除退役节点 testnote04 [root@testnote01 hadoop]# vim dfs.hosts [root@testnote01 hadoop]# cat dfs.hosts testnote01 testnote02 testnote03 (2)刷新namenode,刷新resourcemanager [root@testnote01 hadoop]# hdfs dfsadmin -refreshNodes Refresh nodes successful [root@testnote01 hadoop]# yarn rmadmin -refreshNodes 18/11/07 04:51:40 INFO client.RMProxy: Connecting to ResourceManager at testnote02/192.168.18.51:8033
没有节点

-
从namenode的slave文件中删除退役节点testnote04
[root@testnote01 hadoop]# vim slaves [root@testnote01 hadoop]# cat slaves testnote01 testnote02 testnote03 -
如果数据不平衡,可以用命令实现集群的再平衡
[root@testnote01 hadoop]# start-balancer.sh starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-balancer-testnote01.out -
同步文件实现集群间的文件相同
[root@testnote01 hadoop]# xsync ./