版权声明:有一种生活不去经历不知其中艰辛,有一种艰辛不去体会,不会知道其中快乐,有一种快乐,没有拥有不知其中纯粹 https://blog.csdn.net/wwwzydcom/article/details/83833118
Map阶段
1.待处理文本
2.客户端submit()前获取待处理数据信息,然后根据参数设置,形成一个任务分配的规划,切片信息
3.提交切片信息
job.split
wc.jar
job.xml
4.yarn RM 计算出maptask的数量 Mr appmaster nodemastask数量
拿到的是切片信息,多少个切片,就有多少个maptask
5.默认TextInputFormat
maptask 发出inputFormat —> RecordReader (流的拷贝)
返回 K-V对
6. Mapper逻辑运算 map(K,V) context.write(k,v) ----> outputCollector
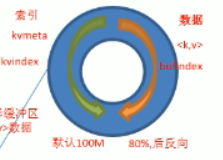
7. 向环形缓冲区写入<K,V>数据
一端是元数据索引(key-value-reduceTypenum:大小,长度,格式),一端是数据,默认是100M,达到80%反向,溢写数据
8.分区,实际是对索引的分区,分区内容的排序,对key进行排序,默认是字典排序,字典排序过程中是使用的快速排序
9.溢写文件(分区且区内有序) 环形再往回写 循环
很多次溢写,只要达到80%,
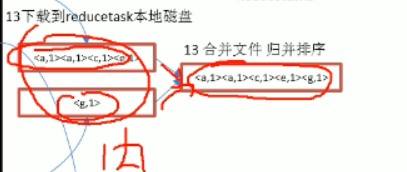
10.合并merge 归并排序
多次溢写



Reduce阶段
1.所有map结束
maptask不能小于分区数


- 拷贝自己处理分区的数据
- 先放到内存中,进行归并排序
优化重点:拷贝过来内存不够,写进磁盘,自己优化内存