和儿子讨论算法,儿子建议我参考一下AlphaGo的原理,发给我参考资料看了一下,感觉很受启发。
一、AlphaGo的数学模型
1.1 围棋问题的本质
围棋问题本质上是一个数据分类问题。
围棋问题可以这样描述:给你一个围棋的布局,求出最佳落子位置。换句话讲:
- 输入是围棋布局,可以抽象为19x19阶矩阵,元素取值-1、0、1。
- 输出是一个位置,共有19x19=361种可能。
容易联想到,实质上这是把19x19尺寸图像分成361类的问题。
1.2 图像分类的 CNN 模型
这里给出图像分类的CNN网络模型示意图:
图1. 用于图像分类的CNN模型示意图
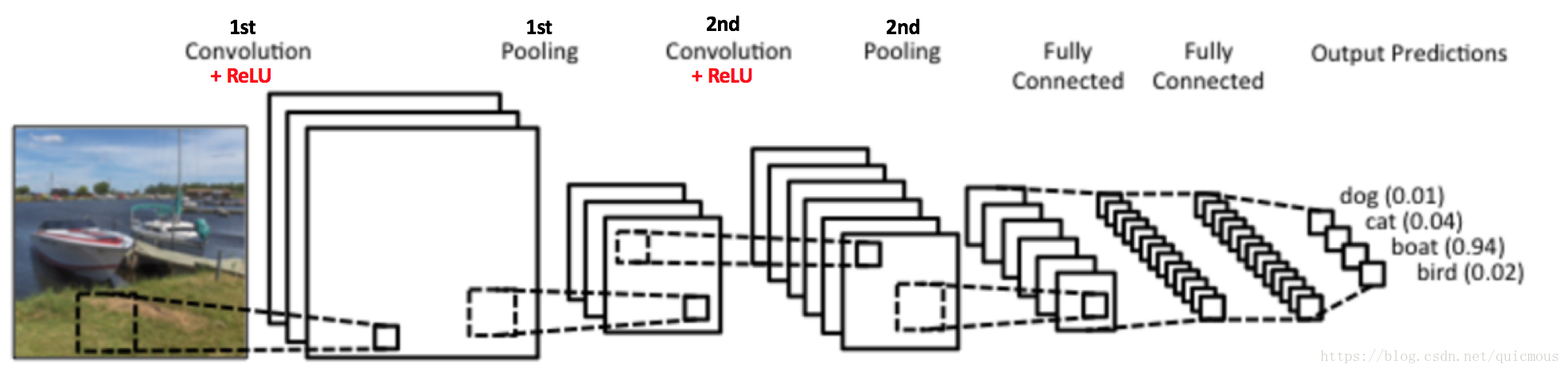
图中输入一幅图片,输出一个四维向量,给出了输入图像是 dog、cat、boat、bird 四类目标的概率分布。
1.3 围棋的 CNN 模型
围棋的 CNN 模型和图像分类模型本质上是一样的,输入是19x19分辨率的棋局“图像”,输出是361维概率分布向量。其中,概率最大的那个位置就是最佳落子位置。
1.4 聪明的谷歌研究团队
围棋问题抽象成纯粹的数学问题,是AlphaGo的核心问题。AlphaGo很聪明,把该问题抽象成了CNN网络模型,这是令人拍案叫绝的地方。
有时候不得不佩服谷歌的研究团队,当年读谷歌的FaceNet那篇论文时,我都有要自杀的感觉,真的,我觉得那个三元组模型太聪明了,通过一个间接的方法构造损失函数,避免了对海量组合样本的标注(其实人脸特征提取模型也不可能人工标注训练样本)。当年我苦思冥想也没找到如此巧妙的途径,这一点对谷歌俺是心悦诚服。
深度学习技术的推广普及,谷歌功不可没。谷歌为人类文明进步做出巨大贡献,是一家伟大的公司。希望我们中国的企业也能把目光放远一些,肩负起解放全人类的光荣使命。
二、模型和训练
2.1 向人类学习
人类积累了大量的棋谱,展示了各种棋局如何落子的示例。这些可以作为训练样本。谷歌从围棋对战平台KGS上获得了人类选手的围棋对弈棋谱,对于每一种棋局,都会有一个人类进行的落子,这也就是一个天然训练样本 ,如此可以得到3000万个训练样本。
谷歌的实验结果表明,这个方法不够好。估计有两原因:
- 数量太少:数量不足以覆盖所有情况。
- 质量太差:人类的经验未必正确,跟臭棋篓子学下棋,肯定学不好。
2.2 MCTS 蒙特卡洛搜索树
MCTS这个想法很奇妙,不需要任何人类的棋谱。
2.2.1 决策树
我们可以这样设想,围棋的所有可能的局面和落子方法如果全部展开,是一个无比庞大的决策树。每个节点对应一个棋局,每个棋局都有一个最佳落子推荐位置。这样围棋问题就搞定了。
由于这棵决策树过于庞大,我们可以构造其一部分,用这一部分做训练样本,然后其余的部分,通过训练卷积神经网络模型来进行预测计算。
2.2.2 MCTS 决策树
MCTS开始构造搜索树之前,首先假定任何棋局在任何位置落子,取胜的机会都是相同的。也就是说,当出现一个新的棋局时,MCTS会为该棋局构造一个初始的19x19阶落子决策权重矩阵,每个落子位置的权重被初始化成相同的值。
图2. 棋局和决策权重矩阵示意图
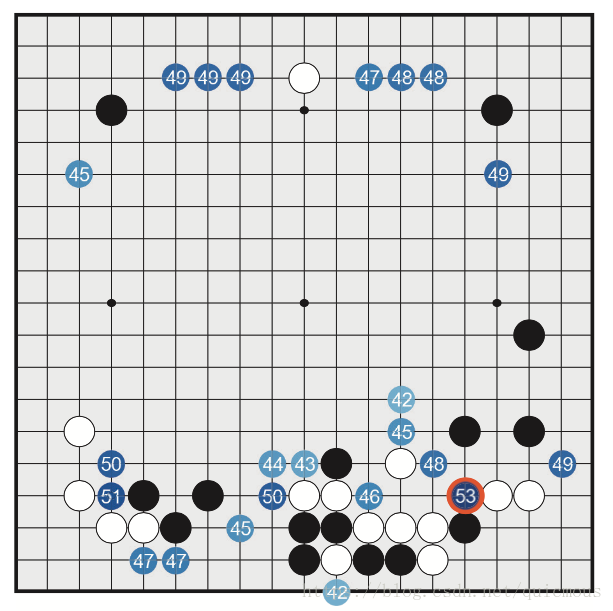
从空白棋局开始,随机落子,直至对弈结束。把对弈过程中出现的棋局放入决策树,各个棋局根据最终胜负调整其决策矩阵权重。接下来下第二盘时,我们就有了一个稍微有一点点经验的的落子参考权重指导。如此下去,对弈10万盘,我们将构造出一个有一定”智力“的决策树。
2.2.3 MCTS 特点分析
MCTS有如下几个特点:
- MCTS 不仅可以用于构建训练样本,而且在对弈过程中,也可以根据对手落子情况继续”在线“模拟。可以想象,进行得了大量随机模拟后,可以得出最佳的走起方法。这种方法谷歌论文中称为Rollout。
- MCTS 可以并行计算,可以通过增加计算资源数量提升计算速度。
2.3 人类经验 + MCTS,增强算法能力
MCTS的棋局落子权重矩阵,可以根据人类的棋谱初始化,可以提高训练速度。实验表明,在开局前面的20步人类的经验是可以起到有效作用的。
三、强化学习和自我对弈
接下来的故事就没前面精彩了,但是引入了另外一项新技术——强化学习,于是乎诞生了 AlphaGo Zero。限于篇幅,强化学习和AlphaGo Zero 以后再慢慢讨论吧。