1.I/O多路复用(IO multiplexing)
我们之前讲了I/O多路复用和其他I/O的区别,在这里,我们再具体讨论下I/O多路复用是怎么工作?
I/O 多路复用技术就是为了解决进程或线程阻塞到某个 I/O 系统调用而出现的技术,使进程不阻塞于某个特定的 I/O 系统调用。
select(),poll(),epoll()都是I/O多路复用的机制。I/O多路复用通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪,就是这个文件描述符进行读写操作之前),能够通知程序进行相应的读写操作。 但select(),poll(),epoll()本质上都是同步I/O,因为他们都需要用户进程在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现内核会负责把数据从内核拷贝到用户空间。
与多线程和多进程相比,I/O 多路复用的最大优势是系统开销小,系统不需要建立新的进程或者线程,从而也就不必维护这些线程和进程。
具体来说就是单个进程(process)就可以同时处理多个网络连接的IO。它的基本原理就是select/epoll这个函数(function)会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:
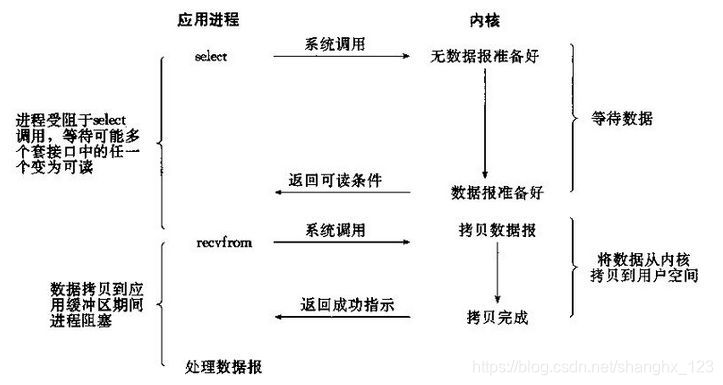
如果还不清楚,我们接下来一个一个来理解。
I/O多路复用—select
select系统调⽤是⽤来让我们的程序监视多个⽂件描述符的状态变化的;
程序会停在select这⾥等待,直到被监视的⽂件描述符有⼀个或多个发⽣了状态改变
1. 所需头文件
#include <sys/select.h>
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
2. 参数:
nfds : 要监视的文件描述符的范围,取当前监视的描述符中最大描述符的值+1,在 Linux 上最大值一般为1024。
readfds: 监视的可读描述符集合,只要有文件描述符即将进行读操作,这个文件描述符就存储到这。
writefds: 监视的可写描述符集合。
exceptfds: 监视的错误异常描述符集合
注:中间的”三个参数 readfds、writefds 和 exceptfds 指定我们要让内核监测读、写和异常条件的描述字。如果不需要使用某一个的条件,就可以把它设为空指针( NULL )。集合fd_set 中存放的是文件描述符,可通过以下四个宏进行设置:
a.清空集合:用来清除描述词组set的全部位
void FD_ZERO(fd_set *fdset);
b.设置:⽤来设置描述词组set中相关fd的位,将一个给定的文件描述符加入集合之中
void FD_SET(int fd, fd_set *fdset);
c.⽤来清除描述词组set中相关fd 的位,将一个给定的文件描述符从集合中删除
void FD_CLR(int fd, fd_set *fdset);
d.⽤来测试描述词组set中相关fd 的位是否为真 ,检查集合中指定的文件描述符是否可以读写
int FD_ISSET(int fd, fd_set *fdset);
timeout: 超时时间,它告知内核等待所指定描述字中的任何一个就绪可花多少时间。其 timeval 结构用于指定这段时间的秒数和微秒数。
- NULL: 则表示select()没有timeout,select将⼀直被阻塞,直到某个⽂件描述符上发⽣了事件;
- 0: 不阻塞 仅检测描述符集合的状态,然后立即返回,并不等待外部事件的发⽣。检查描述字后立即返回,这称为轮询,
- 特定的时间值: 如果在指定的时间段⾥没有事件发生,select将超时返回
struct timeval
{
time_t tv_sec; /* 秒 */
suseconds_t tv_usec; /* 微秒 */
};
3. 返回值
成功:就绪描述符的数目,超时返回 0,
失败:-1,错误原因存于errno,错误值可能为:
- EBADF :文件描述词为⽆效的或该⽂件已关闭
- EINTR :此调⽤被信号所中断
- EINVAL: 参数n为负值。
- ENOMEM: 核⼼内存不⾜
4. 功能
监视并等待多个文件描述符的属性变化(可读、可写或错误异常)。select()函数监视的文件描述符分 3 类,分别是writefds、readfds、和 exceptfds。调用后 select() 函数会阻塞,直到有描述符就绪(有数据可读、可写、或者有错误异常),或者超时( timeout 指定等待时间),函数才返回。当 select()函数返回后,可以通过遍历 fdset,来找到就绪的描述符。
接下来我们来理解select的执行过程
5.select原理
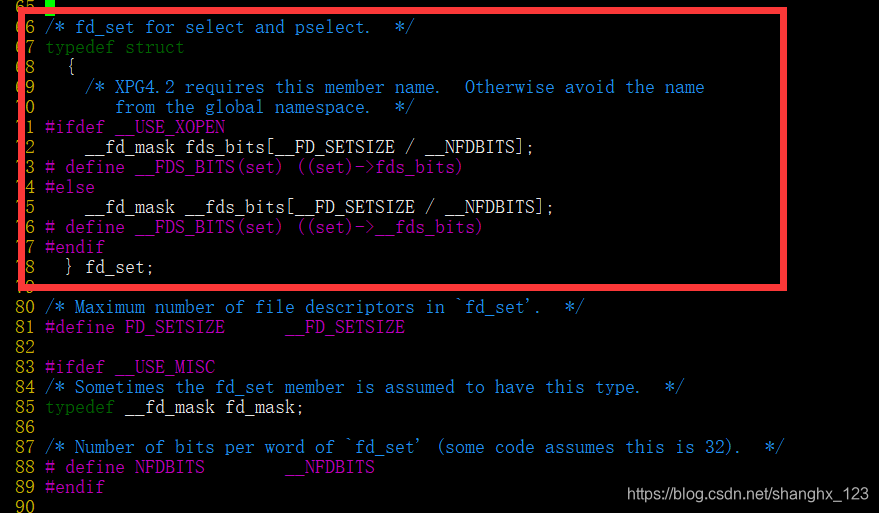
理解select模型的关键在于理解fd_set,其实这个结构就是⼀个整数数组, 更严格的说, 是⼀个 “位图”. 使⽤位图中对应的位来表⽰要监视的⽂件描述符。如图:fd_set结构体里面包含了一个长整型数组。

举个例子:
为说明⽅便,取fd_set⻓度为1字节,fd_set中的每⼀bit可以对应⼀个⽂件描述符fd。则1字节⻓的fd_set最⼤可以对应8个fd。
(1)执行fdset set; FD_ZERO(&set);则set用位表示是0000,0000。
(2)若fd=5,执⾏FD_SET(fd,&set);后set变为0001,0000(第5位置为1)
(3)若再加⼊fd=2,fd=1,则set变为0001,0011
(4)执⾏select(6,&set,0,0,0)阻塞等待
(5)若fd=1,fd=2上都发⽣可读事件,则select返回,此时set变为0000,0011。
注意:没有事件发⽣的fd=5被清空
6.select执行过程(重点)
重点内容:
首先,在调用select函数之前,我们事要设置select参数,即将我们要将要监控的fd(文件描述符)放入fd集合(readfds,writefds,exceptfds)中,在调用select之后,这些fd集合便会从用户态拷贝到内核态,这时程序会停在select阻塞等待,直到被监视的文件描述符有某一个或多个发生了状态改变。而此时内核做的工作就是将这些fd集合遍历一遍,看有没有事件就绪的fd。此时分为两种情况:
1.若有IO事件就绪,则内核就会将该事件所对应的fd标志位置1,由此来通知执行了select()的进程哪些Socket或文件可读可写, 而没有就绪的文件描述符fd 则会从集合中被剔除掉,也就是说最后返回都是就绪的文件描述符,然后,当select返回时,再将这些修改过的fd集合又从内核态拷贝到用户态,selec返回值为就绪fd的个数,最后用户进程就可以处理这些读写操作。
2.若此时内核遍历一遍没有就绪的文件描述符fd,那么内核将不做操作,而select这时也会返回(因为select是同步),只不过select这时还是阻塞的,它会一直轮询,直到有就绪的文件操作符fd,并且等待内核将就绪的文件操作符修改标志位,最后select返回就绪的文件描述符的个数,这样才会执行完毕。
以上就是select函数完整的执行过程,我们从中也发现他不少特点:
先来说缺点吧,
7.select优缺点(重点)
1.最大并发数限制
因为一个进程所打开的FD(文件描述符)是有限制的,由FD_SETSIZE设置(上图中有FD_SETSIZE),默认值是1024/2048,因此select模型的最大并发数就被相应限制了。
虽然用户可以自己修改FD_SETSIZE,然后重新编译内核,但是其实,并不推荐这么做,因为有可能导致程序崩溃,性能方面不言而喻肯定下降。
include/linux/posix_types.h:
#define __FD_SETSIZE 1024
因为Linux下fd_set是一个 1024 位的位图,因此当进程内的 fd 值 >= 1024 时,就会越界,可能会造成崩溃。对于服务器程序,fd >= 1024 很容易达到,只要连接数 + 打开的文件数足够大即可发生。性能方面不言而喻肯定下降。而性能方面内核每次都要遍历一遍全部的fd集合,fd越多,性能越慢。
2.效率问题:
就是我们上面说的,select每次调用都会内核都会线性扫描全部的fd集合,这样效率就会呈现线性下降.
3.内核/用户空间 内存拷贝问题
因为fd集合要从内核和用户之间拷贝多次,而当于服务端要面对成百上千的连接时,这时fd就非常多,性能不言而喻就非常慢了。
4.编码麻烦
每次有就绪事件发生时,都会修改描述符集合 ,把没有就绪的剔除出去,因此我们要监控的描述符每次循环都需要添加,并且select返回值并不会直接告诉用户哪个描述符就绪,因此需要遍历所有的描述符看哪一个就绪,导致编码麻烦。
说完了缺点,当然还有优点:
1.跨平台: select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点。epoll是仅只有Linux下。
2.适用于UDP,适用于单个描述符方便。并且监控的超时时间比较精细(精确到微秒,epoll只能到毫秒)
适用场景:
select适用于在单个描述符的监控上用的频率非常高
多路复用技术(select/epoll/poll)都是适用于有大量客户端连接,但是同一时间只有少量活跃的情况
还有poll 和 epoll ,下个博客介绍
资料参考:https://blog.csdn.net/gatieme/article/details/50979090
https://blog.csdn.net/tennysonsky/article/details/45745887