2.1 字符集及字符编码(字符集——字符的集合,不同的字符集,收录的字符可能不同)
2.1.1多字节字符集及ANSI编码标准
(1)单字节编码:ASCII字符集及扩展——满足英语及西欧语言的需要
(2)双字节编码:——满足亚洲等国家语言文字的需要,如:
| 字符编码及 代码页 |
第1字节 (前导字节Lead Byte及最高位) |
第2字节 尾随字节Trailing Byte及最高位 |
字符数 |
说明 |
| GB2312 (1980) |
A1…F7(1) |
A1…FE(0) |
7445 |
简体字符集(基于区位码设计,高低字节各加了0xA0) |
| Big5 (1984,CP950) |
81…FE(1) |
40..7E(0) A1…FE(1) |
13461 |
繁体字符集(港、澳、台等地) |
| GBK1.0 (1993,CP936) |
81…FE(1) 共126张码表 |
40…FE(0) 80…FE(1) |
21886 |
兼容GB2312,支持Unicode1.1中定义的CJK(中、日、韩语) |
| GB18030 (2000,CP54936) |
27484 |
兼容GBK1.0支持Unicode3.1有单字节、双字节和四字节3种 |
①代码页(Code Page, CP):实际上是Windows为不同的字符编码方案所分配的一个数字编号。 对Windows 用户而言,总共会使用两个代码页。使用 Windows 图形用户界面的应用程序使用 Windows 代码页。Windows 代码页与 ISO 字符集兼容,也与 ANSI 字符集兼容。它们通常称为 ANSI 代码页。Windows 中的字符模式的应用程序(使用命令提示符窗口的应用程序)使用过去在 DOS 中使用的代码页。由于历史原因,这些代码页称为 OEM(原始设备制造商)代码页(注意:代码页是相对于ANSI编码而言的)
②CP936对GBK字符集的编解码。
在解析字节流的时候,如果遇到字节的最高位是0的话,那么就使用936代码页中的第1张码表进行解码,这就和单字节字符集的编解码方式一致了。当字节的高位是1的时候,确切的说,当第1个字节位于0x81–0xFE之间时,根据第1个字节不同找到代码页中的相应的码表。如编码“BA BA D7 D6 41 42 43”在简体中文环境下(GBK,CP936)下被映射成“汉字ABC”。其对应的码表分别为第BA张、第D7张、第1张(ASCII码表),见下图(其中41、42、43即ASCII表的ABC,为简便,此处省略ACII码表)

同样的编码,在繁体中文 (Big5, CP950),它就变成了“犖趼ABC”。如果选择ISO8859-1代码页的话,那我们会看到“ooó?ABC”。
(3)ANSI编码的特点——本地化编码
由于每个国家便针对本国的字符集指定了相应的字符编码标准,如GB2312、BIG5、JIS等仅适用于本国字符集的编码标准。这些字符编码标准统称为ANSI编码标准,他们有一些共同的特点:
①每种ANSI字符集只规定自己国家或地区使用的语言所需的“字符”;比如简体中文编码标准GB-2312的字符集中就不会包含韩国人的文字。
②ANSI字符集的空间都比ASCII要大很多,一个字节已经不够,绝大多数ANSI编码标准都使用多个字节来表示一个字符。这样的编码系统通常用简单的查表,也就是通过代码页就可以直接将字符映射为存储设备上的字节流了。(如“我”的GBK编码为0xCED2,存储时也是0xCED2这样的字节流(这里暂时不虑大小端))
③ANSI编码标准一般都会兼容ASCII码。
④我们现在通常说到ANSI编码,通常指的是平台的默认编码,例如对于英文文件是ASCII编码,对于简体中文文件是GB2312编码(只针对Windows简体中文版,如果是繁体中文版会采用Big5码),在日文操作系统下,ANSI 编码代表 JIS 编码,其他语言的系统的情况类似。
⑤无法解决在一份文档中显示所有字符的问题,因为每次只能以一种编码打开一份文件。
2.1.2 Unicode字符集及UTF-X等编码——国际化编码
(1)Unicode简介
①Unicode字符集涵盖了目前人类使用的所有字符,并为每个字符进行统一编号,分配唯一的字符码(Code Point),也称为Unicode码。Unicode字符集将所有字符按照使用上的频繁度划分为17个层面(Plane),每个层面上有216=65536个字符码空间。

②BMP(平面 0)的 Unicode 编码的布局

注意:中日韩文(CJK)字符的范围一般从U+4E00…U+9FA5,具体如下图所示
| UNICODE码 |
GB18030-2005 |
| 0x4E00-0x9FA5 |
CJK统一汉字的20902汉字 |
| 0x3400-0x4DB5 |
CJK统一汉字扩充A的6582汉字 |
| 0x20000-0x2A6D6 |
CJK统一汉字扩充B的42711汉字 |
| 2E81, 2E84, 2E88, 2E8B, 2E8C, 2E97, 2EA7, 2EAA, 2EAE, 2EB3, 2EB6, 2EB7, 2EBB, 2ECA |
CJK部首补充区的14个部首 |
| F92C, F979, F995, F9E7, F9F1, FA0C, FA0D, FA0E, FA0F, FA11, FA13, FA14, FA18, FA1F, FA20, FA21, FA23, FA24, FA27, FA28, FA29 |
CJK兼容汉字区的21个汉字 |
| 0x9FB4-0x9FBB |
CJK统一汉字区新增了这8个字符 |
③虽然每个字符在Unicode字符集中都能找到唯一确定的编号(字符码,又称Unicode码),他是字符和数字之间的映射,即每个字符映射到唯一的一个Unicode码,一般采用16进制加上前缀U+来表示, 如:A的码位是U+0041。但是决定最终字节流的却是具体的字符编码(这一点与ANSI编码是不同的!)。例如同样是对Unicode字符“A”进行编码,UTF-8字符编码得到的字节流是0x41,而UTF-16(大端模式)得到的是0x00 0x41。
(2)常见的Unicode编码
①UTF-8编码——变长编码,是以字节为编码单元,没有字节序的问题
| Unicode码 (CodePoint)范围 |
UTF-8编码(二进制) |
备注 |
| U+0000 – U+007F |
0xxxxxxx |
首字节前置1的数目代表正确解析所需要的字节数,剩余字节的高2位始终是10。例如首字节是1110yyyy,前置有3个1,说明正确解析总共需要3个字节,需要和后面2个以10开头的字节结合才能正确解析得到字符。 |
| U+0080 – U+07FF |
110xxxxx 10xxxxxx |
|
| U+0800 – U+FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
|
| U+10000 - U+1FFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
★“汉”字U+6C49用二进制表示是:0110 1100 0100 1001,对应U+0800 – U+0FFFF区间,将这些二进制位放入对应的位置后就变成了:11100110 10110001 10001001,再将其转换成十六进制是E6 B1 89。
★由上分析可见ASCII字母继续使用1字节储存,重音文字、希腊字母或西里尔字母等使用2字节来储存,而常用的汉字就要使用3字节。辅助平面字符则使用4字节。
②UTF-16编码方式——在WindowsVista以上的版本上,每个Unicode都是采用这种编码
UTF-16是Unicode字符集的一种转换方式,即把Unicode的码位转换为16比特长的码元串行,以用于数据存储或传递。
A、从U+0000至U+D7FF以及从U+E000至U+FFFF的码位
第一个Unicode平面(BMP),码位从U+0000至U+FFFF(除去代理区),包含了最常用的字符。UTF-16与其CodePoint(Unicode码)在数值是等价的。
B、从U+D800到U+DFFF的码位(代理区)
因为Unicode字符集的编码值范围为0-0x10FFFF,而大于等于0x10000的辅助平面区的编码值无法用2个字节来表示,所以Unicode标准规定:基本多语言平面内,U+D800..U+DFFF的值不对应于任何字符,为代理区。因此,UTF-16利用保留下来的0xD800-0xDFFF区段的码位来对辅助平面的字符的码位进行编码。
C、从U+10000到U+10FFFF的码位——(不常用,略)
③UTF-32:又称为UCS-4,它固定使用32 bits(四个字节)来表示一个字符。
(3)字节序及BOM——不同编码下将字符串"汉字ABC"保存到Text文件后在内存中的表示
| 编码形式 |
编码结果(含BOM)(内存从低到高地址) |
| UTF-8 |
EF BB BF E6 B1 89 E8 AF AD 41 42 43 |
| UTF-16 LE |
FF FE 49 6C 57 5B 41 00 42 00 43 00 (低字节低地址,高字节高地址) |
| UTF-16 BE |
FE FF 6C 49 5B 57 00 41 00 42 00 43 |
| UTF-32 LE |
FF FE 00 00 49 6C 00 00 57 5B 00 00 41 00 00 00 42 00 00 00 43 00 00 00 |
| UTF-32 BE |
00 00 FE FF 00 00 6C 49 00 00 5B 57 00 00 00 41 00 00 00 42 00 00 00 43 |
(说明:“汉”—U+0x6C49,“字”-U+0x5B57)
2.1.3 Locale和ANSI代码页
(1)Locale和LCID
Locale是指特定于某个国家或地区的一组设定,包括字符集,数字、货币、时间和日期的格式等。在Windows中,每个Locale可以用一个32位数字表示,记作LCID。在winnt.h中可以看到LCID的组成。它的高16位表示字符的排序方法,一般为0。在它的低16位中,低10位是primary language的ID,高4位指定sublanguage。sublanguage被用来区分同一种语言的不同编码。下面是部分primary language和sublanguage的常数定义:
#define LANG_CHINESE 0x04
#define LANG_ENGLISH 0x09
#define LANG_FRENCH 0x0c
#define LANG_GERMAN 0x07
#define SUBLANG_CHINESE_TRADITIONAL 0x01 // Chinese (Taiwan Region)
#define SUBLANG_CHINESE_SIMPLIFIED 0x02 // Chinese (PR China)
#define SUBLANG_ENGLISH_US 0x01 // English (USA)
#define SUBLANG_ENGLISH_UK 0x02 // English (UK)
好,现在我们可以计算简体中文的LCID了,将sublanguage的常数左移10位,即乘上1024,再加上primary language的常数:2*1024+4=2052,16进制是0804。美国英语是:1*1024+9=1033,16进制是0409。。繁体中文是1*1024+4=1028,16进制是0404。
(2)系统locale和用户locale
在Windows中,通过控制面板可以为系统和用户分别设置Locale。系统Locale决定代码页,用户Locale决定数字、货币、时间和日期的格式。使用GetSystemDefaultLCID函数和GetUserDefaultLCID函数分别得到系统和用户的LCID。用户程序缺省使用的代码页是当前系统Locale的ANSI代码页,可以称作ANSI编码,对于一个未指定编码方式的文本文件,Windows会按照ANSI编码解释。
每个Locale都联系着很多信息,可以通过GetLocaleInfo函数读取。其中最重要的信息就是字符集了,即Locale对应的语言文字的编码。Windows将字符集称作代码页。
每个Locale可以对应一个ANSI代码页和一个OEM代码页。Win32 API使用ANSI代码页,底层设备使用OEM代码页,两者可以相互映射。
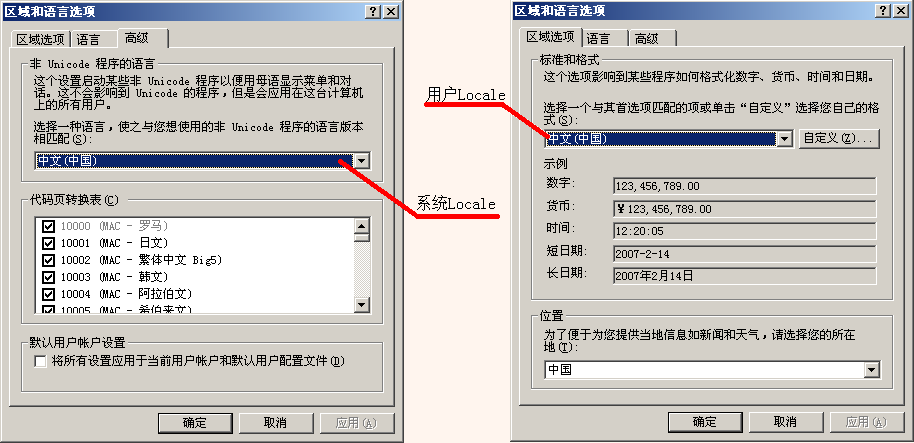
★调用GetSystemDefaultLCID和GetUserDefaultLCID函数可以获得区域信息标识符
要获得本地语言标识符可以调用GetSystemDefaultLangID和GetUserDefaultLangID
2.2 ANSI字符和Unicode字符与字符串数据类型
| ANSI |
Unicode |
通用 |
|
| C\C++ |
char |
wchar_t |
_TCHAR |
| Windows |
CHAR |
WCHAR |
TCHAR |
| 举例 |
char c='A' char szBuffer[100]= "A String" |
wchar_t c=L'A' WCHAR szBuffer[100]= L"A String" |
TCHAR c=TEXT('A') TCHAR szBuffer[100]= TEXT("A String") |
2.3 Windows中的Unicode函数和ANSI函数——函数名后带W或A的
★Windows从NT内核版本开始所有平台均完全基于UNICODE打造,Windows内部其实仅提供了UNICODE版的API,非UNICODE版的API在内部先将参数转换成UNICODE串,然后再调用UNICODE版的API,如果返回结果仍然是UNICODE,那么就再进行反向转换。可见在Ansi版函数的效率比较低、开销内存更多。为了效率和兼容性,建议应用程序使用Unicode来开发。
2.4 Unicode和ANSI字符串函数
(1)常用字符串函数
| 功能 |
ANSI(标准C/Win) |
Unicode(标准C/Win) |
通用版本(标准C/Win) |
| 合并字符串 |
strcat/lstrcatA |
wcscat/lstrcatW |
_tcscat/lstrcat |
| 比较字符串 |
strcmp/lstrcmpA |
wcscmp/lstrcmpW |
_wcscmp/lstrcmp |
| 字符串长度 |
strcpy/lstrcpyA 返回字节数) |
wcslen/lstrlenA |
_tclen/lstrlen 返回字符个数 |
| 打印字符串 |
printf/ |
wprintf/ |
_tprintf/ |
注意:
①使用标准c版时一般要选setlocale(或_tsetlocale),否则可能乱码。此外,C函数一般带“_t”,要选包含tchar.h文件)
②Windows版—WinBase.h或WinUser.h
(2)Windows版本的UNICODE字符串函数
| 函数 |
描述 |
| CharLower CharLowerBuff |
将字符或字符串转成小写(C函数为tolower,但Windows版的可作用于字符集中的任何字符(包非英文字符)注意,会改变原字符串! |
| CharUpper CharUpperBuff |
将字符或字符串转成大写 |
| CharNext |
移到字符串中的下一个字符 |
| CharPrev |
移动到字符串中的前一个字符 |
| IsCharAlpha |
字符是否是字母 |
| IsCharAlphaNumber |
字符是否字母数字 |
| IsCharLower |
字符是否小写 |
| IsCharUpper |
字符是否大写 |
| CompareString(Ex) |
字符串比较函数(要考虑区域设置) |
| CompareStringOrdinal |
字符串比较,只做Unicode的CodePoint比较,不考虑区域设置,速度快。 |
【UpperAndLower程序】大小写转换
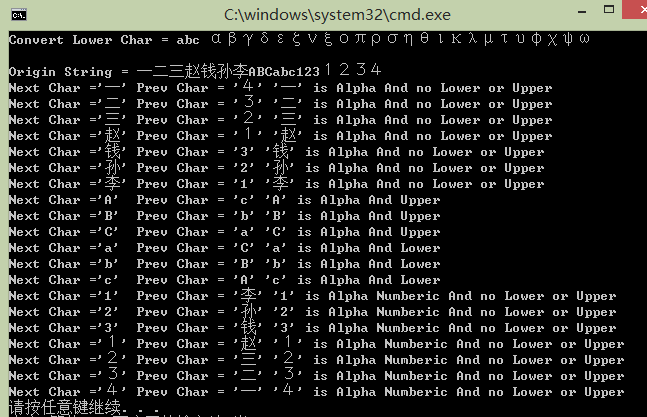
/*----------------------------------------------------------------------------------------------
大小写转换测试程序
-----------------------------------------------------------------------------------------------*/
#include <windows.h>
#include <tchar.h>
#include <locale.h>
int _tmain()
{
_tsetlocale(LC_ALL, _T("chs")); //调用C库Unicode函数,须写这行,否则会乱码
//大小写转换
TCHAR chLower[] = _T("abc αβγδεζνξοπρσηθικλμτυφχψω");
TCHAR *chUpper = NULL;
_tprintf(_T("Lower Char = %s\n"), chLower);
chUpper = CharUpper(chLower); //转换为大写
_tprintf(_T("Upper Char = %s\n"), chUpper);
_tprintf(_T("Upper Char Address = 0x%08X,\nLower Char Address = 0x%08X\n"), chUpper, chLower);
CharLower(chUpper);
_tprintf(_T("Convert Lower Char = %s\n"), chLower);
TCHAR pString[] = _T("一二三赵钱孙李ABCabc1231234");//注意,含有全角,CharUpper都可以转换!
int iLen = lstrlen(pString); //字符个数
TCHAR* pNext = pString; //指向第1个字符
TCHAR* pPrev = pString + sizeof(pString) / sizeof(pString[0]) - 1; //指向最后一个字符,即\0
_tprintf(_T("\nOrigin String = %s\n"), pString);
for (int i = 0; i < iLen;i++)
{
pPrev = CharPrev(pString, pPrev);
_tprintf(_T("Next Char ='%c'\tPrev Char = '%c' "), *pNext, *pPrev);
if (IsCharAlpha(*pNext))
{
_tprintf(_T("'%c' is Alpha"),*pNext);
}
else if (IsCharAlphaNumeric(*pNext))
{
_tprintf(_T("'%c' is Alpha Numberic"),*pNext);
}
else
{
_tprintf(_T("'%c'is Unkown Type"), *pNext);
}
if (IsCharLower(*pNext))
{
_tprintf(_T(" And Lower\n"));
}
else if (IsCharUpper(*pNext))
{
_tprintf(_T(" And Upper\n"));
}
else
{
_tprintf(_T(" And no Lower or Upper\n"));
}
pNext = CharNext(pNext);
}
}