一、链表的理解:
1,各个节点间地址存放可以不连续,虽说是表,但是指针存在是为了找到其他的节点,如果连续了,都没必要用链表了。
2,各节点依赖上一节点,要找到某一个节点必须找到他的上一个节点,所以要访问链表,必须要知道头指针,然后从头指针访问开始。
3,各节点间原来是独立的,本来没有联系,只有数据部分。但是想把这些节点数据联系起来,就可以通过地址去联系起来,所以地址就作为节点一部分,用来指向下一节点。这个地址呢还是指向这个结构体类型的。
4,建立联系就是相当于要建立链表。各个节点加上地址(申请空间即得到地址),得到地址之后,再指定前后连接关系,就形成了一条链。
5,链表的头head是不变的,中间对链表的操作可以通过另指定一个指针操作。
6,创建链表过程:
a,为每个没有地址的节点创建地址*node(独立节点);
b,设置空链表即 * head, head= NULL;
c,链表中的的节点通用*p,初始化时p=head;
d,刚开始的链表中的第一个节点即head,这个地址可以“随便给一个”,即head= node,只是将第一个独立节点的地址传给head,就相当于给head赋个初值,但并不会影响独立节点node。
if (i = 0)
{
head = node;
}
e,建立联系。
else
{
p->next = node;
p = node;
}
f,指定最后一个节点的next为NULL.
p->next = NULL;
g,输出链表
if (head != NULL)
{
for(p = head; p!= NULL; p = p->next) //不要写成p->next != NULL,那样判断的就是最后一个节点的后一个为空的作为条件,那个就会把最后一个节点舍掉了
{
printf("%d",p->score);
}
}
二,对链表的复杂操作
1,链表的冒泡排序:千万不能当成普通的冒泡排序,如果还是按照n-1次去循环交换就不是对链表操作了。而是应该当成单纯的节点交换排序方法,然后更新尾部节点。每排一次序,结束交换的节点就可以了。冒泡排序时间复杂度:内层循环是n-1次,外层循环是n-1次,内外总的就是 (n-1) + (n-2) + ... + 1 = n * (n - 1) / 2
方法一:
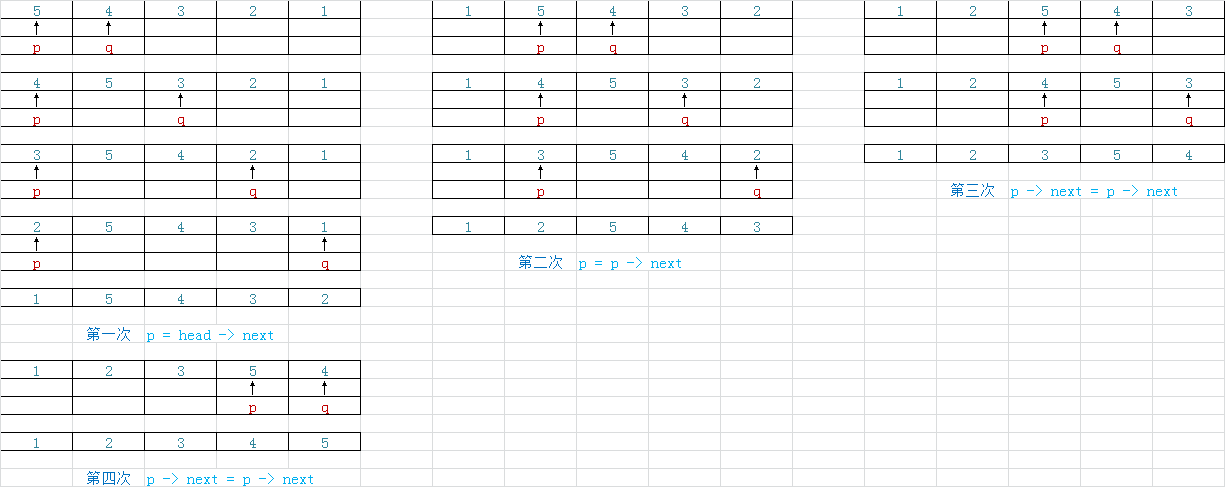
实现是:
p = head;
tail = head->next;while (p->next != NULL)
{
while (tail != NULL)
{
if(p->score > tail->score)
{
temp = tail->score;
tail->score = p->score;
p->score = temp;
}
tail = tail->next;
}
p = p->next;
tail = p->next;
}
删除节点:
struct student *node, *p;
if(head->score == x)/* 要单独考虑 */
{
node = head;
head = head->next;
free(node);
}
for(p = head;p->next != NULL; p = p->next)
{
node = p->next; /*删除节点时,要用删除的前一个节点来指向删除节点的后一个,删除的节点肯定不能再用了就 */
if(node->score == x)
{
p->next = node->next;
free(node);
}
}
上述删除操作用例不能通过,需要按下面方法:
struct student *delete_node(struct student *head, int x)
{
struct student *node, *p, *temp;
p = head;
node = head->next;
while(p != NULL)/*p 和node都进行了判空操作*/
{node = p->next; /*与p = p->next的位置需要根据判断条件先后而定,如果先判断p,则node应该在之后进行移 动,如果先判断node,则node应该在判断之前就应移动,从而准备好*/
if(head->score == x)
{
temp = head;
head = head->next;
p = head;
node = p->next;/**/
free(temp);
}
else if(node != NULL)
{
if (node->score == x)
{
p->next = node->next;
free(node);
}
p = p->next;
}
}
return head;
}
快排:
1,每次划分都把每次的基准元素放在了他最后应该呆的地方。
2,最后先发原则:每次应该从最后 j 开始,因为j先开始,才能每次把比基准小的元素放在他的左侧。如果先从左侧开始 i 找(比基准大的元素),那就是先将比他大的元素与 j 交换,,如果 最后一个元素比第一个元素(基准大),那这次交换白费功夫了(相当于还是比基准的元素排到前面来了)。其实从最右开始的根因是将最左侧的第一个元素作为了基准,这样从最右开始,能保证这次一定是把比基准小的元素放在基准的前面,即 i=0,i刚开始不移动,即保证了只拿j元素与i=0(基准,已知)比较。而当从最左开始时,比较的是i移动后的,i++与j交换,而此时两个都未知,没有比较的基准,那交换就自然不能保证比基准更小的元素放在基准的前面了,也不能保证元素大的在最后面。
链表实现:
void quik_sort(struct student *head, struct student *tail)
{
int temp,temp1,key;
struct student *left, *right;
if(head == NULL || head == tail)
{
return;
}
left = head;
right = left->next;
while(left != tail && right!=NULL)
{
if (right->score < head->score)
{
left = left->next;/* */
temp = left->score;
left->score = right->score;
right->score = temp;
}
right = right->next;
}
temp1= left->score;
left->score = head->score;/*与head交换,因为每次讲head作为分界标志*/
head->score = temp1;
quik_sort(head, left);
quik_sort(left->next, tail);
}
综上注意点:当用到前后多个移动指针组合对链表完成操作时,则这几个指针都需进行判断异常处理。