生产跑sql
select sum(col) from (select 1 col from zbg_serv.tf_f_user_svc_item where month_id='201811' and day_id='05' limit 1 union all select 1 col from zbg_serv.tf_f_user_svc where month_id='201811' and day_id='05' limit 1 union all select 1 col from zbg_serv.tf_f_user where month_id='201811' and day_id='05' limit 1)t
报错:

业务前端报错如下:

查找原因:
查看yarn web页面对应的job日志,第二个节点日志显示为killed


但是重新执行就能成功。
还没找出具体原因,又有新的sql报错同样错误,报错如下:
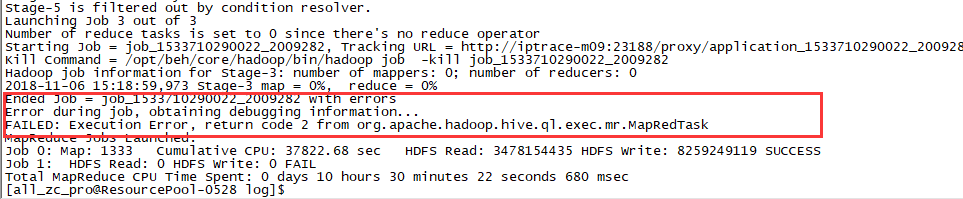
从节点日志看来,没有明显的报错信息 ,看到后面都是stop命令,并且业务侧也没有明显报错,再次重新跑也能重新跑过去。。
从另一个方面着手解决:
(1)优化am内存
yarn.app.mapreduce.am.resource.mb
yarn.app.mapreduce.am.command-opts
这两也可以加大 一倍,现在报错都是am出问题

(2)增加切换次数到5

从截图看都在10分钟左右超时切换2次失败了(application master默认是2次)
mapreduce.am.max-attempts 5
yarn.resourcemanager.am.nax-attempts 5
(3)增加超时时间和mr类似
yarn.am.liveness-monitor.expiry-interval-ms
更改后需要重启rm,切换即可,也可滚动重启
注:mapreduce.am.max-attempts 这个是map-site文件
其他在yarn-site文件
最后总结:集群失败重跑能过去的JOB,我们需要优化5个参数,其中三个在接口机,两个在Yarn

更改后需要滚动重启yarn