Java编译(二)Java前端编译:
Java源代码编译成Class文件的过程
在上篇文章《Java三种编译方式:前端编译 JIT编译 AOT编译》中了解到了它们各有什么优点和缺点,以及前端编译+JIT编译方式的运作过程。
下面我们详细了解Java前端编译:Java源代码编译成Class文件的过程;我们从官方JDK提供的前端编译器javac入手,用javac编译一些测试程序,调试跟踪javac源码,看看javac整个编译过程是如何实现的。
1、javac编译器
1-1、javac源码与调试
javac编译器是官方JDK中提供的前端编译器,JDK/bin目录下的javac只是一个与平台相关的调用入口,具体实现在JDK/lib目录下的tools.jar。此外,JDK6开始提供在运行时进行前端编译,默认也是调用到javac,如图:

javac是由Java语言编写的,而HotSpot虚拟机则是由C++语言编写;标准JDK中并没有提供javac的源码,而在OpenJDK中的提供;我们需要在Eclipse中调试跟踪javac源码,看整个编译过程是如何实现的。
javac编译器源码下载(JDK8):http://hg.openjdk.java.net/jdk8u/jdk8u-dev/langtools/archive/tip.tar.bz2
javac编译器源码目录:**\src\share\classes\com\sun\tools\javac
在Eclipse新建工程导入后,可以看到javac源码的目录结构如下:
javac编译器程序入口:com.sun.tools.javac.Main类中的main()方法;
运行javac程序,先是解析命令行参数,由com.sun.tools.javac.main.Main.compile()方法处理,代码片段如下:
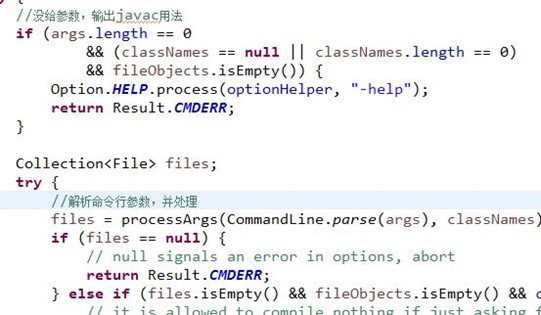
因为没有给参数,可看到输出的是javac用法,如下:
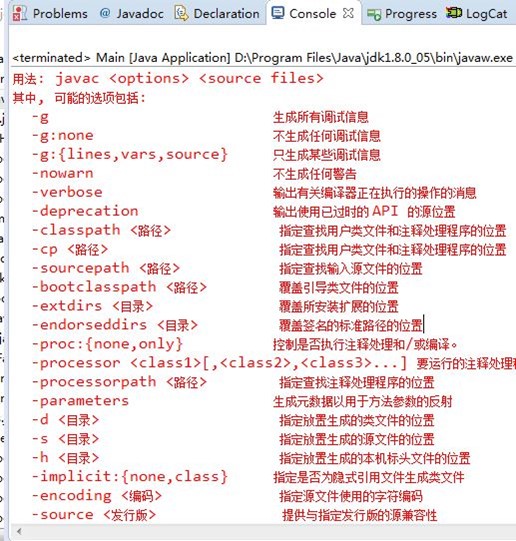
这就是平时我们用JDK/bin/javac的用法,更多javac选项用法请参考:http://docs.oracle.com/javase/8/docs/technotes/tools/unix/javac.html
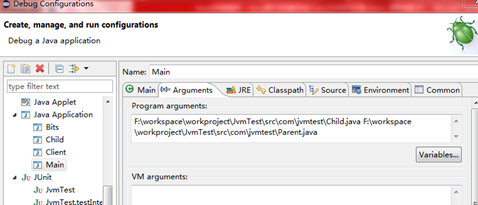
调试编译文件,需要右键工程 -> Debug As -> Debug Configurations ->切换到Arguments选项卡,在Program arguments中输入我们要用javac编译的Java程序文件的路径即可;然后就可以打断点Debug运行调试了,如图:
1-2、javac编译过程
JVM规范定义了Class文件结构格式,但没有定义如何从java程序文件转化为Class文件,所以不同编译器可以有不同实现。
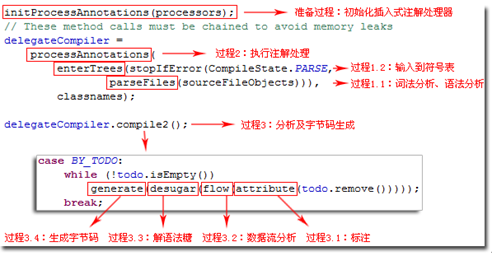
从javac编译器源码来看,其编译过程可以分为3个子过程:
1、解析与填充符号表过程:解析主要包括词法分析和语法分析两个过程;
2、插入式注解处理器的注解处理过程;
3、语义分析与字节码的生成过程;
如图所示(来自参考4):

javac编译动作入口: com.sun.tools.javac.main.JavaCompiler类;
3个编译过程逻辑集中在这个类的compile()和compile2()方法;
如图所示:
1-3、javac中的访问者模式
访问者模式可以将数据结构和对数据结构的操作解耦,使得增加对数据结构的操作不需要修改数据结构,也不必修改原有的操作,而执行时再定义新的Visitor实现者就行了。
Javac经过第一步解析(词法分析和语法分析),会生成用来一棵描述程序代码语法结构的抽象语法树,每个节点都代表程序代码中的一个语法结构,包括:包、类型、修饰符、运算符、接口、返回值、甚至注释等;而后的不同编译阶段都定义了不同的访问者去处理该语法树(节点)。
了解这些更容易理解javac的编译过程实现,而后面分析过程中会再对访问者模式的实现作相关说明。
2、解析与填充符号表
2-1、解析:词法、语法分析
解析包括:词法分析和语法分析两个过程;
2-1-1、词法分析
1、概念解理
词法分析是将源代码的字符流转变为标记(Token)集合;
标记:
标记是编译过程的最小元素;
包括关键字、变量名、字面量、运算符(甚至一个".")等;
2、源码分析:
由com.sun.tools.javac.parser.Scanner类实现对外部提供服务;
由com.sun.tools.javac.parser.JavaTokenizer类实现具体的Token分析动作(JavaTokenizer.readToken()方法);
Scanner.nextToken()调用JavaTokenizer.readToken()方法读取下一个Token;
返回com.sun.tools.javac.parser.Tokens.Token类实例表示的一个Token;
Scanner.nextToken()方法如下:

注意,下面语法分析时才会不断调用Scanner.nextToken()读取一个个Token进来解析。
2-1-2、语法分析
1、概念解理
语法分析是根据Token序列构造抽象语法树的过程;
抽象语法树(Abstract Syntax Tree,AST):
是一种用来描述程序代码语法结构的树形表示方式;
每个节点都代表程序代码中的一个语法结构;
语法结构(Construct)包括:包、类型、修饰符、运算符、接口、返回值、甚至注释等;
2、源码分析:
由com.sun.tools.javac.parser.JavacParser类完成整个过程,该类实现com.sun.tools.javac.parser.Parser接口;
一个类文件解析产生的抽象语法树的所有内容保存在JCCompilationUnit类实例里,JCCompilationUnit类是由com.sun.tools.javac.tree.JCTree类扩展;
JCTree是个抽象类,实现了Tree接口,Tree接口里有一个"<R,D> R accept(TreeVisitor<R,D> visitor, D data)"方法用来接收访问者,所以Tree接口是访问者模式中的抽象节点元素;
JCTree类中有一个Visitor内部类,同时也是一个抽象类,作为访问者模式中的抽象访问者;
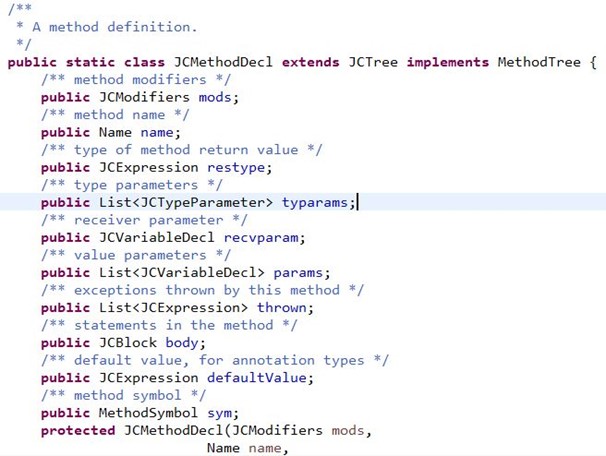
一个JCTree类实例相当于抽象语法树的一个节点,它会扩展许多类型,对应不同语法结构类型的树节点,如JCStatement,JCClassDecl,JCMethodDecl,JCBlock等等,这些类是访问者模式中的具体节点元素;
JCTree扩展的JCMethodDecl方法类型节点结构如下:
代码执行的解析过程,如下:
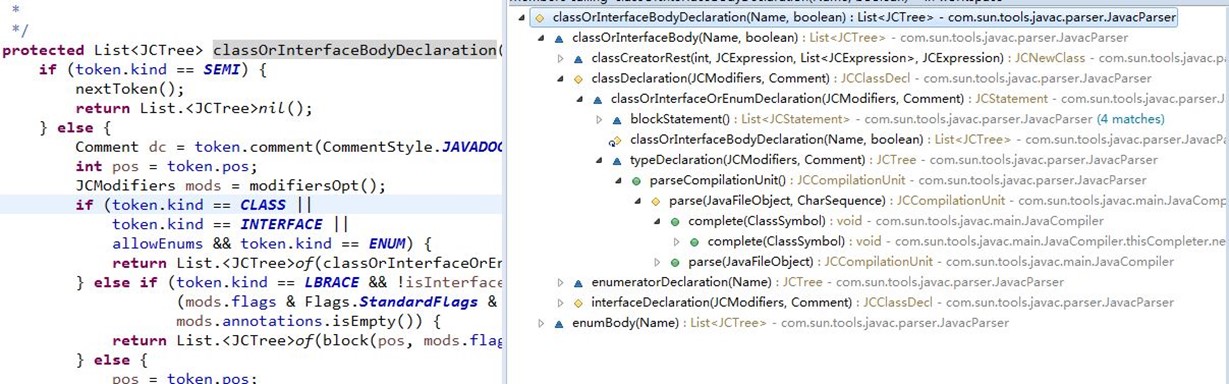
1)、由JavaCompiler.compile()方法调用JavaCompiler.parseFiles()方法完成参数输入的所有文件的编译;
2)、JavaCompiler.parseFiles()方法中又调用本类中的parse()方法对其中一个文件进行编译;
该方法中生成JavacParser类实例,然后调用该实例的parseCompilationUnit()方法开始进行整个文件的解析(包括"package"包名),如下:
Parser parser = parserFactory.newParser(content, keepComments(), genEndPos, lineDebugInfo);
tree = parser.parseCompilationUnit();返回的tree是JCCompilationUnit类型实例,保存了一个类文件解析产生的抽象语法树的所有内容,也可以说是抽象语法树的根节点;
3)、JavacParser.parseCompilationUnit()方法中调用JavacParser.typeDeclaration()进行文件中所有类型定义的解析;
JavacParser.typeDeclaration()又调用JavacParser.classOrInterfaceOrEnumDeclaration()进行类或接口的解析;
如果是类又调用classDeclaration()对该类进行解析....
JCTree def = typeDeclaration(mods, docComment);返回一个JCTree类实例表示文件中所有类型定义定义的语法树(不包括"package"包名);
这期间会不断调用Scanner.nextToken()读取一个个Token进来解析;
3、编译测试:
下面我们用javac编译JavacTest.java文件来跟踪整个解析过程,测试文件代码如下:
package com.jvmtest;
public class JavacTest {
private int i;
public int getI() {
return i;
}
public void setI(int i) {
this.i = i;
}
}
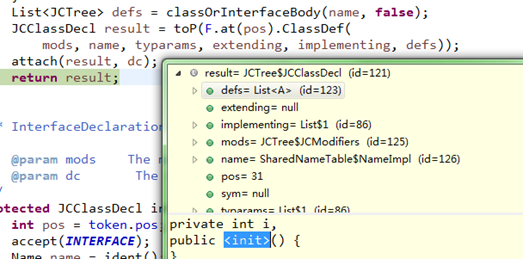
对于解析JavacTest.java文件生成的抽象语法树,由返回的JCCompilationUnit类实例表示,如下图所示:

最外层节点为"com.jvmtest"包名的定义,同时它也是语法树的根节点;
再里一层是"public class JavacTest"类的定义;
再里面可以看到一个字段变量"i"的结构节点,以及两个方法"getI"和"setI"节点;
4、类实例构造函数重名为<init>():
先在再上面的测试程序中加入类实例构造函数:
Public JavacTest() {
}需要注意的是,在classOrInterfaceBodyDeclaration()解析类时,如果遇到添加的类构造函数,会重名为<init>(),如下:
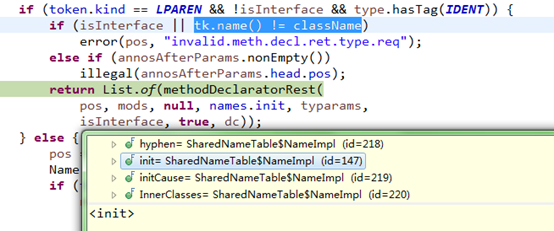
如测试程序中加入类构造函数,可以看到被重命名<init>(),但在生成的树结构上名称还是表现为"JavacTest",如下
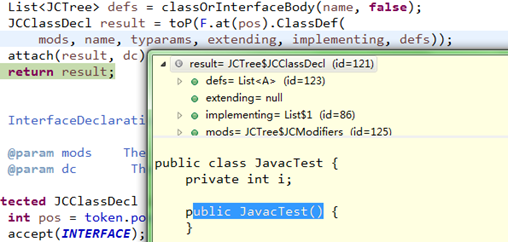
经过上面解析,后续所有操作都建立在抽象语法树之上,下面不会再对源码文件操作;
2-2、填充符号表
1、概念解理
符号表(Symbol Table)是由一组符号地址和符号信息构成的表格,可以想象成哈希表中K-V值的形式;
符号表登记的信息在编译的不同阶段都要用到,如:
1)、用于语义检查和产生中间代码;
2)、在目标代码生成阶段,符号表是对符号名进行地址分配的依据;
2、源码分析:
根据上一步生成的抽象语法树列表,由JavaCompiler.enterTrees()方法完成填充符号表;
由com.sun.tools.javac.comp.Enter类实现填充符号表动作,Enter类继承JCTree.Visitor内部抽象类,重写了一些visit**()方法来处理抽象语法树,作为访问者模式中的具体访问者;
符号由com.sun.tools.javac.code.Symbol抽象类表示, 实现了Element接口,Element接口里有一个accept()方法用来接收访问者,所以Element接口是访问者模式中的抽象节点元素;
Symbol类扩展成多种类型的符号,如ClassSymbol表示类的符号、MethodSymbol表示方法的符号等等,这些类是访问者模式中的具体节点元素;
Symbol类和MethodSymbol类定义如下:
public abstract class Symbol extends AnnoConstruct implements Element {
/** The kind of this symbol.
* @see Kinds
*/
public int kind;
/** The flags of this symbol.
*/
public long flags_field;
/** An accessor method for the flags of this symbol.
* Flags of class symbols should be accessed through the accessor
* method to make sure that the class symbol is loaded.
*/
public long flags() { return flags_field; }
/** The name of this symbol in Utf8 representation.
*/
public Name name;
/** The type of this symbol.
*/
public Type type;
/** The owner of this symbol.
*/
public Symbol owner;
/** The completer of this symbol.
*/
public Completer completer;
/** A cache for the type erasure of this symbol.
*/
public Type erasure_field;
// <editor-fold defaultstate="collapsed" desc="annotations">
/** The attributes of this symbol are contained in this
* SymbolMetadata. The SymbolMetadata instance is NOT immutable.
*/
protected SymbolMetadata metadata;
......
}
/** A class for method symbols.
*/
public static class MethodSymbol extends Symbol implements ExecutableElement {
/** The code of the method. */
public Code code = null;
/** The extra (synthetic/mandated) parameters of the method. */
public List<VarSymbol> extraParams = List.nil();
/** The captured local variables in an anonymous class */
public List<VarSymbol> capturedLocals = List.nil();
/** The parameters of the method. */
public List<VarSymbol> params = null;
/** The names of the parameters */
public List<Name> savedParameterNames;
/** For an attribute field accessor, its default value if any.
* The value is null if none appeared in the method
* declaration.
*/
public Attribute defaultValue = null;
......
}
从上面可以看到它们包含了哪些信息;
代码执行的填充过程,如下:
1)、JavaCompiler.enterTrees()方法调用Enter.main()方法;
根据上一步生成的抽象语法树列表完成填充符号表,返回填充了类中所有符号的抽象语法树列表;
2)、Enter.main()方法调用中本类的complete()方法;
complete()方法先调用Enter.classEnter()方法完成填充包符号、类符号以及导入信息等;
3)、接着complete()方法还会不断调用前面生成的每个类的类符号实例的ClassSymbol.complete()方法;
ClassSymbol.complete()方法会调用到MemberEnter.complete(),以完成整个类的填充符号表;
4、MemberEnter.complete()中会添加类的默认构造函数(如果没有任何的);
还会调用 MemberEnter.finish()方法完成对类中字段和方法符号的填充;
等等(其实先处理注解信息)...
注意,EnterTrees()方法最终完成返回一个待处理列表("todo" list),其实该列表还是抽象语法树列表,符号只是填充到上一步生成的抽象语法树列表中;可以从上面语法分析给出的JCMethodDecl类中看到有一个MethodSymbol类的成员变量;
3、编译测试
还用上面的JavacTest.java文件测试,其中getI()方法的符号如下(显示符号名称):
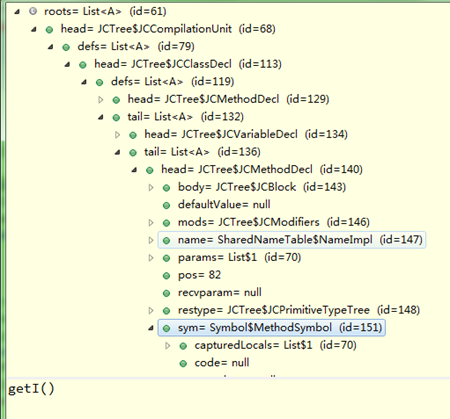
测试JavacTest.java文件填充符号表的前后,抽象语法树列表变化(红色)如下:
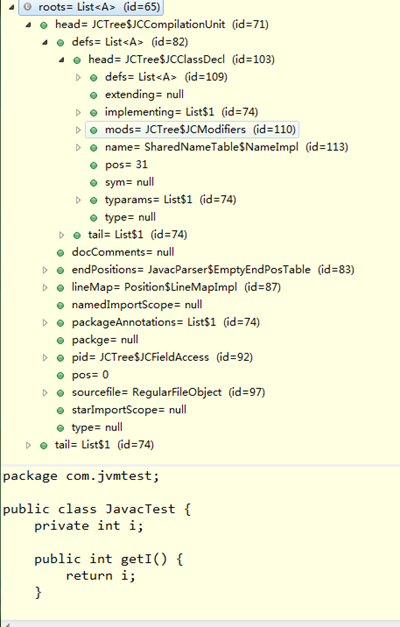
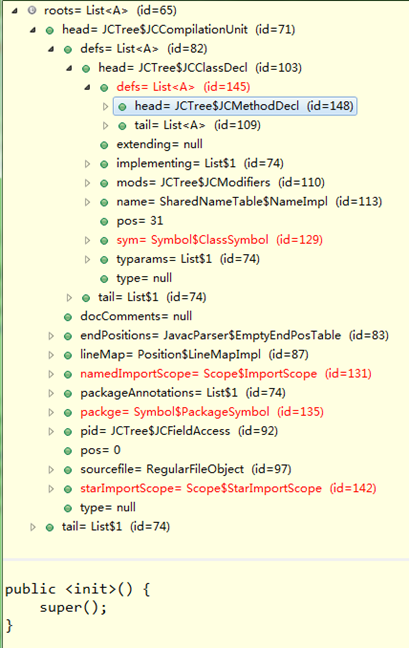
4、计算方法的特征签名
其实MethodSymbol方法符号中的MethodType类型的type成员就是其特征签名;
在.MemberEnter.visitMethodDef(JCMethodDecl tree)中填充方法符号的时候计算特征签名,如下:
public void visitMethodDef(JCMethodDecl tree) {
......
MethodSymbol m = new MethodSymbol(0, tree.name, null, enclScope.owner);
......
// Compute the method type
m.type = signature(m, tree.typarams, tree.params,
tree.restype, tree.recvparam,
tree.thrown,
localEnv);
......
}
MethodType如下:
public static class MethodType extends Type implements ExecutableType {
public List<Type> argtypes;
public Type restype;
public List<Type> thrown;
/** The type annotations on the method receiver.
*/
public Type recvtype;
public MethodType(List<Type> argtypes,
Type restype,
List<Type> thrown,
TypeSymbol methodClass) {
super(methodClass);
this.argtypes = argtypes;
this.restype = restype;
this.thrown = thrown;
}
......
}可以看到特征签名包含了返回值类型,其实方法特征签名在Java语言层面和JVM层面是不同的:
Java语言层面特征签名:
方法名、参数类型和参数顺序;
JVM层面特征签名:
方法名、参数类型、参数顺序和返回值类型;
这个在后面文章介绍Class文件格式再详细说明;
5、添加默认类实例构造函数、"this"类变量符号、"super"父类变量
这个阶段,编译器自动添加默认类实例构造函数、"this"类变量符号、"super"父类变量符号:
(a)、如果类中没有定义任何实例构造函数,编译器会自动添加默认的类实例构造函数;
在完成一个类的填充符号时调用:
MemberEnter.complete(Symbol sym){
......
// Add default constructor if needed.
if ((c.flags() & INTERFACE) == 0 &&
!TreeInfo.hasConstructors(tree.defs)) {
......
if (addConstructor) {
MethodSymbol basedConstructor = nc != null ?
(MethodSymbol)nc.constructor : null;
JCTree constrDef = DefaultConstructor(make.at(tree.pos),
c, basedConstructor, typarams,
argtypes, thrown, ctorFlags, based);
tree.defs = tree.defs.prepend(constrDef);
}
......
}
......
}
测试JavacTest.java文件添加的实例构造函数如下:
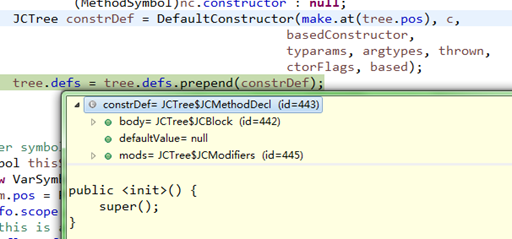
可以看到添加的类实例构造名称为<init>(),虽然树结构上名称还是表现为"JavacTest";
还有添加的时候会判断当前类的类型如果不是Object类型,都会在构造函数里添加"super();",表示调用父类的构造函数,如下:
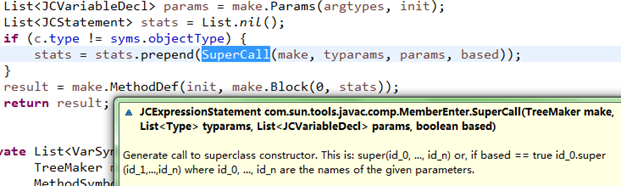
(b)、添加"this"类变量
在类实例作用域添加"this"符号,表示当前类实例,如下:
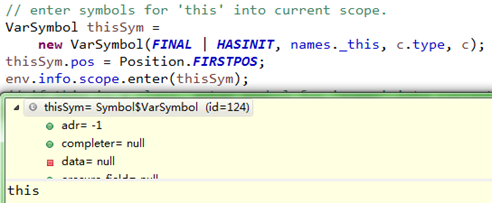
(c)、"super"父类变量符号
接着,在类实例作用域添加"super"符号,表示类父,如下:
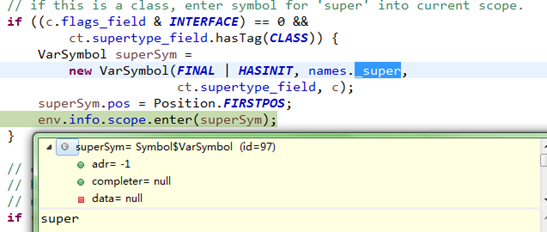
3、插入式注解处理器的注解处理过程
JDK1.5后,Java语言提供了对注解(Annotation)的支持,注解和Java代码一样,可以在运行期间发挥作用;
JDK1.6中提供一组插件式注解处理器的标准API(JSR 269: Pluggable AnnotationProcessing API),取代 APT(JEP 117: Remove the Annotation-ProcessingTool),可以实现API自定义注解处理器,干涉编译器的行为;
注解处理器可以看作编译器的插件,在编译期间对注解进行处理,可以对语法树进行读取、修改、添加任意元素;但如果有注解处理器修改了语法树,编译器将返回解析及填充符号表的过程,重新处理,直到没有注解处理器修改为止,每一次重新处理循环称为一个Round。
如Hibernate Validator Annotation Process:用于校验Hibernate标签。
1、源码分析
注解处理器的初始化过程在JavaCompiler.initProcessAnnotations()方法中完成;
执行过程则是JavaCompiler.processAnnotations()方法;
如果有多个注解处理器,在JavacProcessingEnvironment.doProcessing()继续处理;
2、注解处理器实现与运行
代码实现:继承抽象类javax.annotation.processing.AbstractProcess,并覆盖abstract方法:"process()";
运行/测试:通过javac -processor参数附带编译时的注解处理器;
这里我们没有实现注解处理器,运行javac编译JavacTest.java不会处理语法树;
4、语义分析与字节码生成
上面我们获得了填充了符号表的抽象语法树列表;
它能表示程序的结构,但无法保证程序的符合逻辑。
4-1、语义分析
主要任务是对结构上正确的源程序进行上下文有关性质的审查(如类型审查);
语义分析过程分为标注检查、数据及控制流分析两个步骤;
4-1-1、标注检查
1、概念解理
标注检查步骤检查的内容包括变量使用前是否已被声明、变量与赋值的数据类型是否能匹配等;
还有比较重要的动作称为常量折叠;
如前面测试程序"int i;"改为"int i=1+2;",会被折叠成字面量"3",与"int i=3"一样,如图:
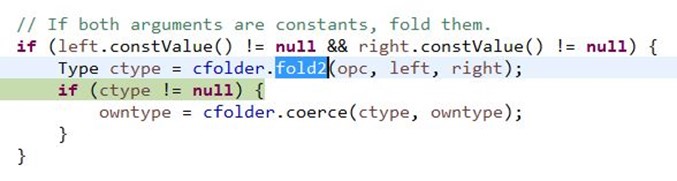
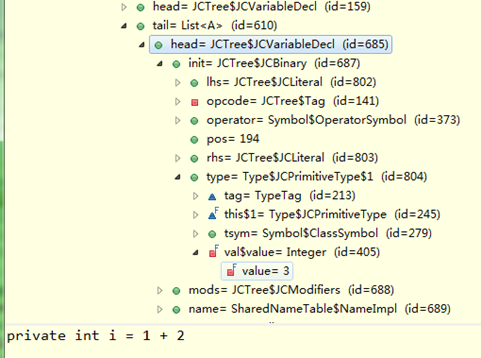
2、源码分析
主要由com.sun.tools.javac.comp.Attr类和com.sun.tools.javac.comp.Check类完成,调用关系如下图:
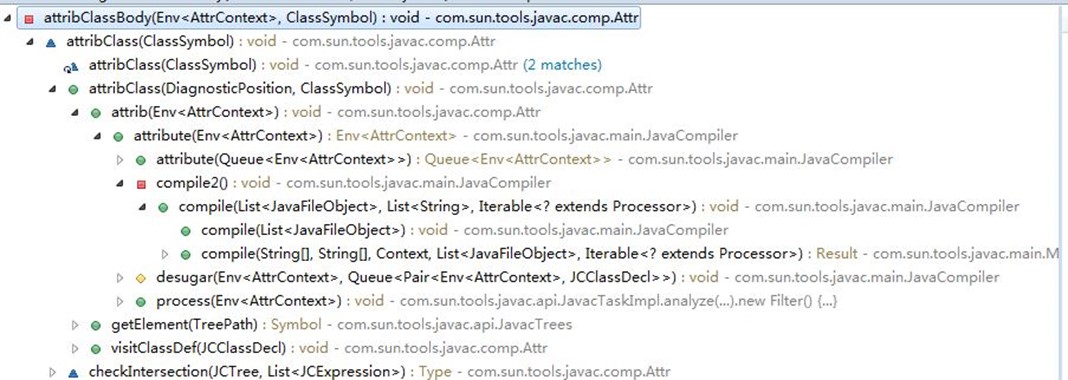
由JavaCompiler.attribute()入口分析整个类的语法树的标注;
到Attr.attribClassBody()分析类的主体部分,如进行所有定义的检查:
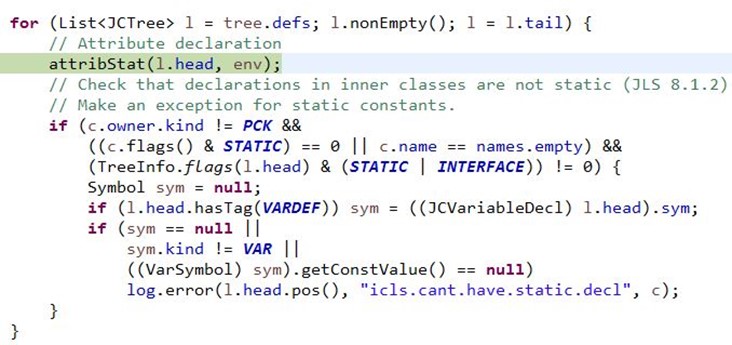
comp.Check类的实例在Attr.attribClassBody()分析中进行定义、类型等检查;
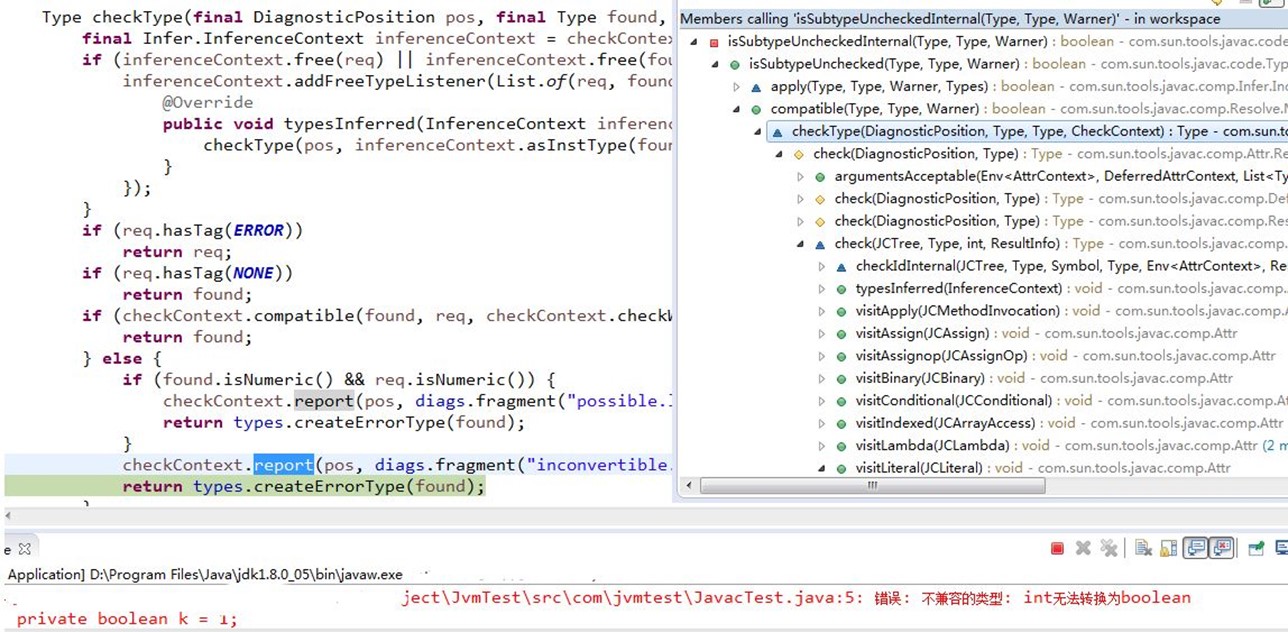
如"boolean k = 1",最终是通过类型检查赋值数据"1"的类型"int"不是接收者"k"的类型"Boolean"的父类来确定错误,如下:

3、自动添加super():
方法检查时,如果发现(自己定义的)类实例构造函数没有显式调用super()或this(),会添加super()的父类构造函数调用,如下:
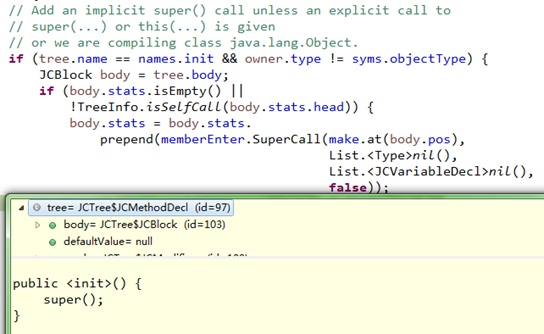
但是,前面说过如果没有自定定义任何构造函数,前面填充符号表时,就已经添加含有super()的默认构造函数了;
4、标注检查结果
标注检查中已经使用Env<AttrContext>类实例作为类编译信息的存储形式,它包含了一些访问上下文环境。
还是前面的测试程序,标注检查前后变化(红色)如下:
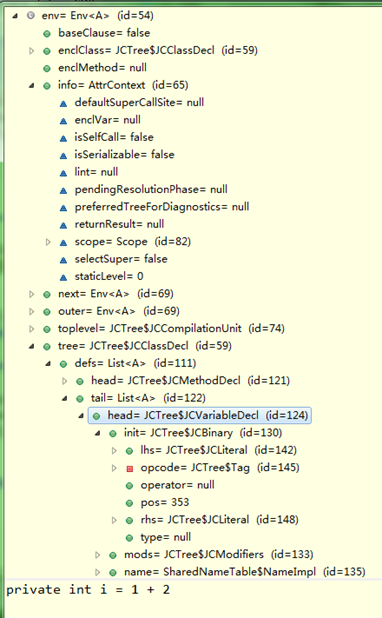
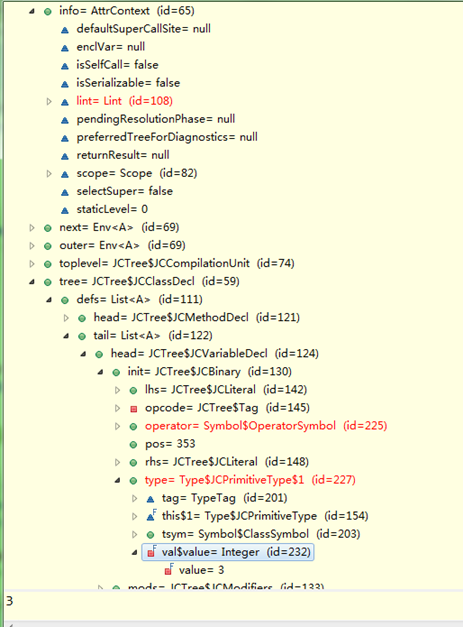
4-1-2、数据及控制分析
1、概念解理
数据及控制分析是对程序上下方逻辑更进一步的验证;
如检查变量的初始化、方法每个执行分支是否都有返回值、是否所有的异常都被正确处理等;
注意这阶段并不会对变量赋值;
这个时期与类加载时的数据及控制分析的目的一致,但校验范围不同;
如final修饰的局部变量:
final修饰的局部变量是在这个编译阶段处理的;
有没有final修饰符,编译出来的Class文件都一样,在常量池没有CONSTANT_Fiedref_info称号引用;
即在运行期没有影响,参数不变性由编译器在编译期保障;
2、源码分析
主要由 com.sun.tools.javac.comp.Flow类实现;
调用关系如下:

主要在其analyzeTree()方法中完成分析,如下:
public void analyzeTree(Env<AttrContext> env, TreeMaker make) {
//1、活性分析:检查每个语句是否可访问;
new AliveAnalyzer().analyzeTree(env, make);
//2、(i)、赋值分析:检查确保每个变量在使用前已被初始化;
// (ii)、未赋值分析:检查确保final修饰变量的不变性(不会被第二次赋值);
// 还用于标记"effectively-final"局部变量/参数;
// 使用活性分析的结果;
new AssignAnalyzer().analyzeTree(env);
//3、异常分析:检查确保每个异常被抛出、声明或捕获;
// 需要使用活性分析设置的一些信息;
new FlowAnalyzer().analyzeTree(env, make);
//4、"effectively-final"分析:这检查每个来自lambda body/local内部类的局部变量引用是"final or effectively";
// 由于effectively final变量在DA/DU期间被标记,所以该步骤必须在AssignAnalyzer之后运行;
new CaptureAnalyzer().analyzeTree(env, make);
}
1)、活性分析
new AliveAnalyzer().analyzeTree(env, make);
检查每个语句是否可访问;
它里面有一个方法makeDead(),它的调用关系如下:
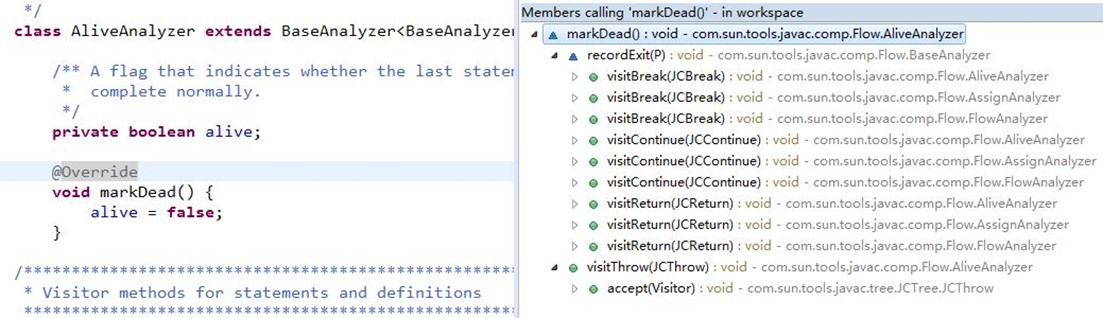
可以看到访问到return/break/continue以及thorw关键字,就会调用标记后面的语句不能再访问;
如果还有就会发现编译错误:
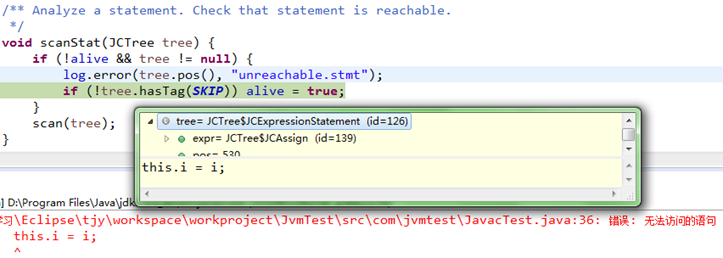
(A)、如程序中,方法return后,还有逻辑,就会发生错误,如下:
public void setI(int i) {
return ;
this.i = i;
}会发生:错误:无法访问的语句(unreachable stmt),如图:
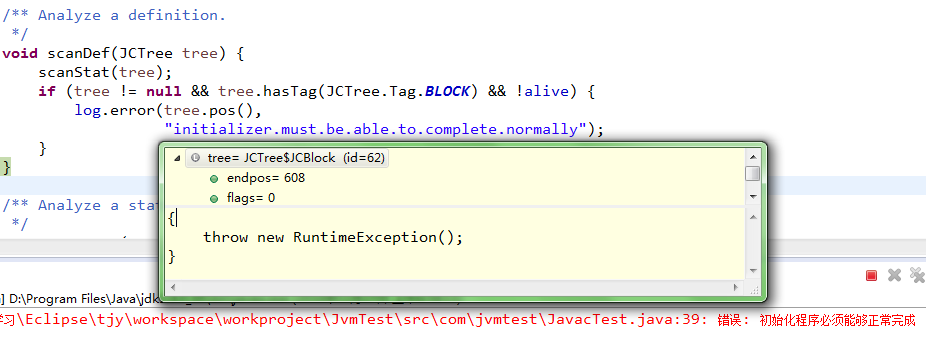
(B)、还有throw的情况,如在类普通块中直接抛出异常:
会发生:错误: 初始化程序必须能够正常完成(error: initializer must be able to complete normally),如图
{
throw new RuntimeException();
}
2)、赋值分析
new AssignAnalyzer().analyzeTree(env);
检查确保每个变量在使用前已被初始化;
检查确保final修饰变量的不变性(不会被第二次赋值);
注意,如果实例成员方法中为final成员变量赋值,会在标注检查阶段分析出错误;
这里的检查主要是对象final修饰的变量,下面我们用另一个程序编译测试,如下:
public class JavacTest {
public static int s_uinit;
public static int s = 1;
public final int f_uinit; //错误: 变量f_uinit未在默认构造器中初始化
public final int f = 2;
public static final int sf_uinit; //错误: 变量sf_uinit未在默认构造器中初始化
public static final int sf = 3;
private int i_uinit;
private int i = 4;
public void test(final int methodParam_f) {
final int method_f_uinit;
final int method_f = methodParam_f;
this.i = method_f_uinit; //错误: 可能尚未初始化变量method_f_uinit
this.i = method_f;
method_f_uinit = 1;
method_f_uinit = 2; //错误: 可能已分配变量method_f_uinit
//f_uinit = 12; //错误(属于标注检查错误)
}
}
这个程序编译会出现四个错误,我们看下是怎么检查的:
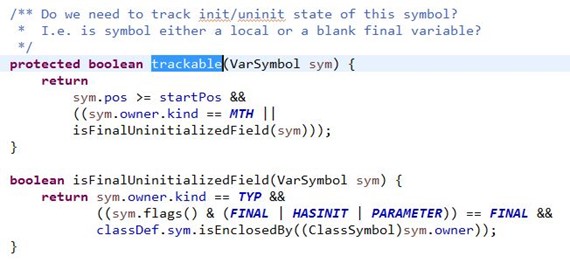
AssignAnalyzer里面有一个trackable()方法,说明这里应该关注什么样的字段/变量符号的初始化;
从它实现中可以看出检查主要是对象final修饰的字段/变量,如下:
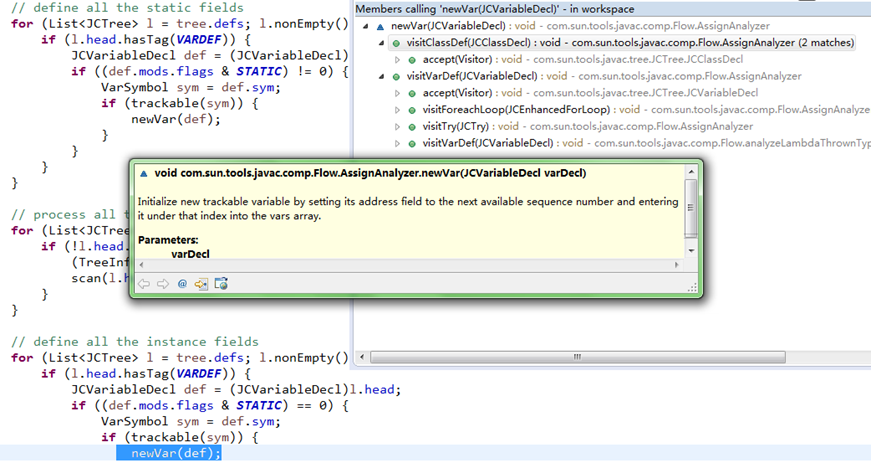
还有一个newVar()方法,当然发现应该关注检查的字段/变量后,newVar()方法会把这个符号记录下来;
它在三个地方调用,在visitClassDef()里检查static类字段和非static类实例字段时,以及在visitVarDef()检查方法中的变量及参数,调用如下:
(A)、检查static类字段和非static类实例字段
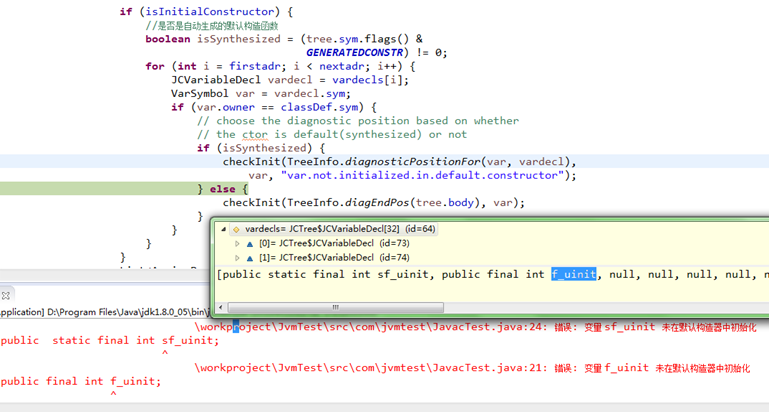
从上图可以看到,先是检查static类字段和非static类实例字段,把关注的未进行初始化的final字段记录下来;
而后再检查方法,先是检查类实例构造方法;
这时会把前面记录的字段,通过checkInit()再次检查确认;
如果的确定是未进行初始化的final字段,报告相关错误,如下:
错误: 变量 sf_uinit 未在默认构造器中初始化(var not initialized in default constructor)
错误: 变量 f_uinit 未在默认构造器中初始化
(B)、检查方法的传入参数
接着还是visitMethodDef()检查类中的方法(访问者模式);
先检查方法参数,如下:
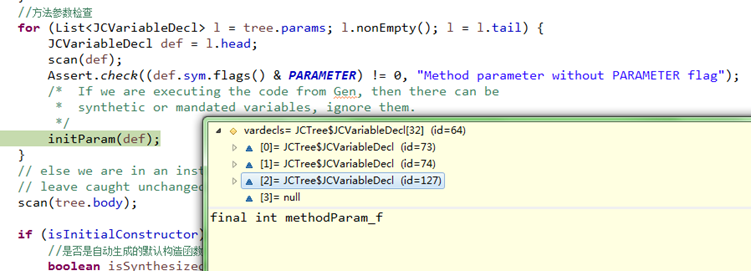
虽然scan()中检查并记录了测试程序test()方法methodParam_f参数,但是下面立刻调用initParam()删除了记录;
所以方法的final参数未初始化并不影响下面的使用;
可以认为运行时传入的final参数都是赋值初始化了的;
(C)、检查方法中的变量定义
接着检查方法体中定义的变量;
其中method_f_uinit变量未初始化,被记录下来;
而method_f变量虽然开始被记录下来,
但它初始化为methodParam_f参数值,所以立即调用letInit()删除了相关记录,如下图:
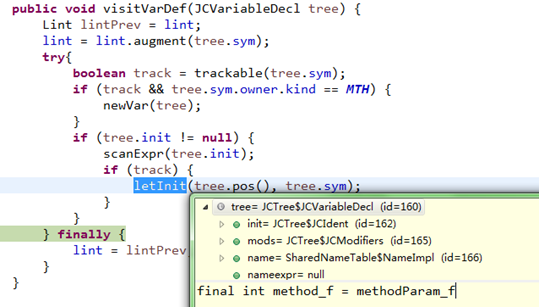
所以下面它也可以被使用(this.i = method_f);
(D)、检查方法运行中的变量使用
注意,上面检查方法中的参数和变量,只是记录下来定义时未初始化final变量,这里才是检查使用前已被初始化;
可以看到method_f_uinit变量在上面被记录下来,使用时作为"Ident"检查;
在visitIdent()中调用checkInit()确定其未初始化,然后打印错误,如下:
错误: 可能尚未初始化变量method_f_uinit(var might not have been initialized);
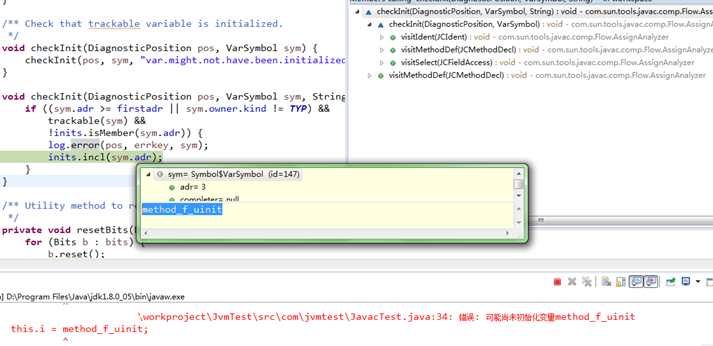
而method_f变量初始化为methodParam_f,未被记录,所以checkInit()检查通过,正常使用;
(E)、检查final修饰变量不会被二次赋值
注意,如果实例成员方法中为final成员变量赋值(方法中f_uinit = 12),会在标注检查阶段分析出错误;
但在类块{}中为未初始化的final成员变量赋值(相当于在构造函数赋值),也会发生检查二次赋值的情况;
方法中两次为method_f_uinit变量赋值;
检查赋值操作是visitAssign()方法,里面会为左值method_f_uinit变量调用letInit();
第一次因为定义时没有初始化,所以letInit()中调用uninit()把前面定义时未初始化的记录删除;
第二次因为没有了记录,所以letInit()中打印出错误,如图:
错误:可能已分配变量method_f_uinit(var might already be assigned);
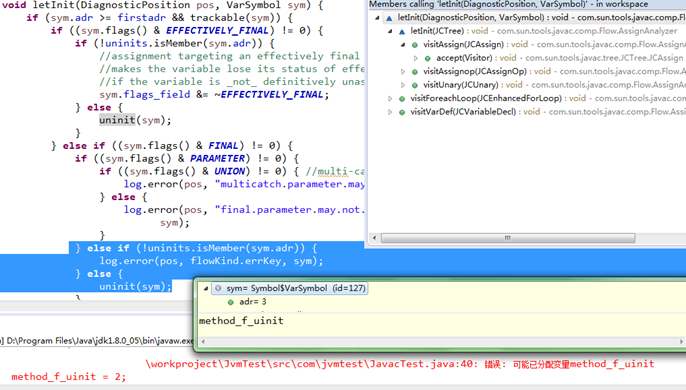
正如前面说的:
final修饰的局部变量是在这个编译阶段处理的;
有没有final修饰符,编译出来的Class文件都一样,在常量池没有CONSTANT_Fiedref_info称号引用;
即在运行期没有影响,参数不变性由编译器在编译期保障;
4-2、解语法糖
1、概念解理
语法糖(Syntactic Sugar)也称粮衣语法;
对象语言功能没有影响,只是简化程序,提高效率,增可读性,减少出错;
但使得程序员难以看清程序的运行过程;
Java最常用的有:
泛型、变长参数、自动装箱/拆箱、遍历循环、内部类、断言等;
JVM不支持这些语法;
在编译阶段还原回简单的基础语法结构,称为解语法糖;
2、源码分析
入口调用com.sun.tools.javac.main.JavaCompiler.desugar()完成;
主要由com.sun.tools.javac.comp.TransTypes类和com.sun.tools.javac.comp.Lower类实现;
3、泛型与类型擦除
拿泛型来说,泛型是JDK1.5的新增特性;
本质是参数化类型(Parametersized Type)的应用;
即所操作的数据类型被指定为一个参数;
可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口和泛型方法;
(A)、Java泛型与C#泛型
C#的泛型在程序、编译后、运行期都是存在的;
对于List<int>和List<String>是两种不现的类型,在运行期有自己的虚方法表和类型数据;
这种实现方法称为类型膨胀,基于这种方法实现的泛型称为真实泛型;
Java语言泛型在编译后的字节码文件中,就被替换为原来的原生类型(Raw Type);
并在相应地方插入强制转型代码;
对于ArrayList<int>和ArrayList<String>,在运行期是同一种类型;
这种实现方法称为类型擦除,基于这种方法实现的泛型称为伪泛型;
(B)、运行时识别(反射)泛型参数类型
对于泛型类型擦除后,需要在运行时识别(反射)泛型参数类型的问题:
JVM规范引入了Signature、LocalVariableTypeTable等Class属性;
Signature存储一个方法在字节码层面的特征签名,保存了参数化类型的信息;
这也是能通过反射手段取得参数化类型的根本依据;
相关Class属性会在后面文章介绍Class文件格式时再说明;
(C)、编译测试
测试程序JvmTest10_2.java,如下:
package com.jvmtest;
import java.util.HashMap;
import java.util.Map;
public class JvmTest10_2 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("hello", "java");
System.out.println(map.get("hello"));
}
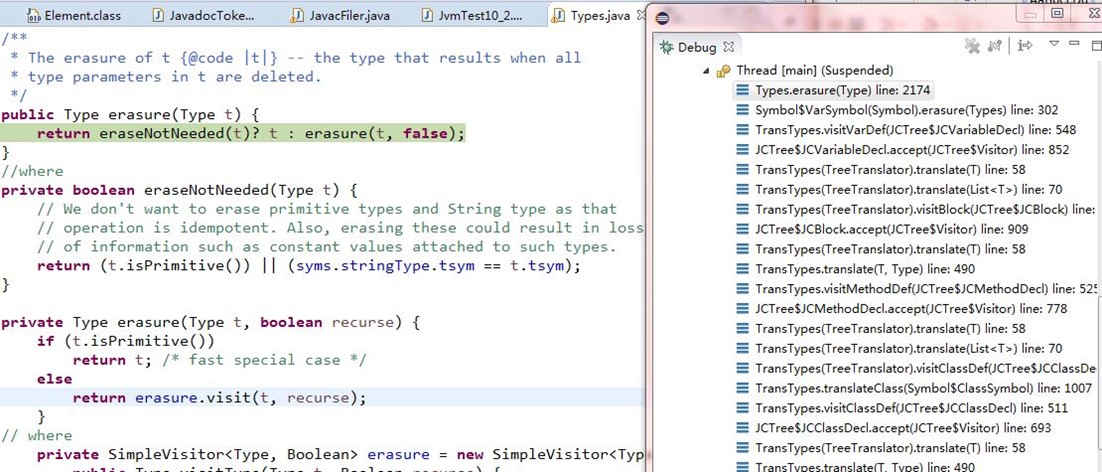
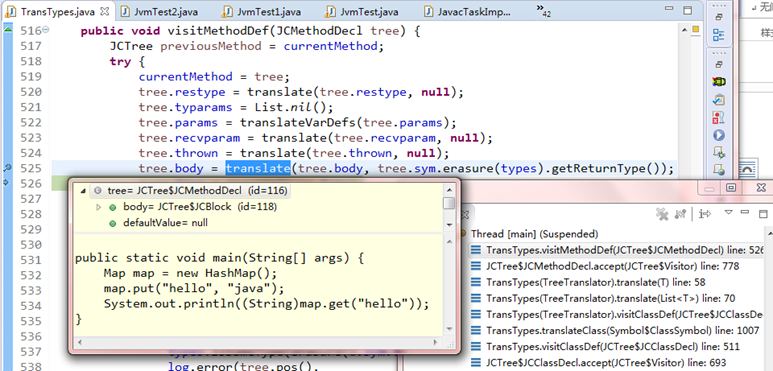
}泛型擦除调用关系及关键代码,如下:
测试程序中泛型经过编译类型被擦除,如下:
4-3、字节码生成
1、概念理解
把前面生成的语法树、符号表等信息转化成字节码,然后写到磁盘Class文件中;
2、源码分析
由com.sun.tools.javac.jvm.Gen类实现添加代码和转换字节码;
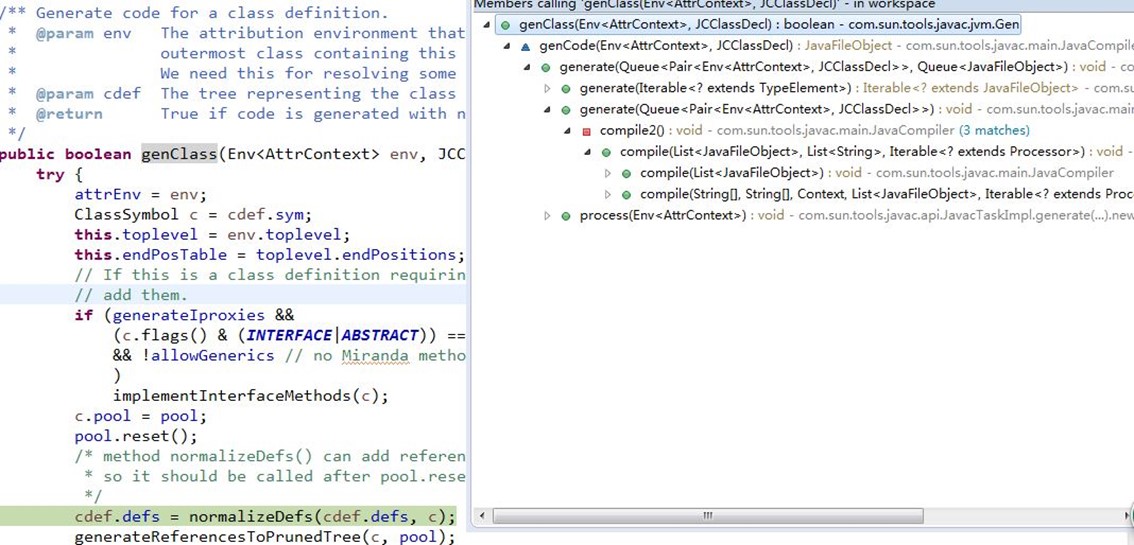
入口调用com.sun.tools.javac.jvm.Gen.genClass(),调用关系如下:
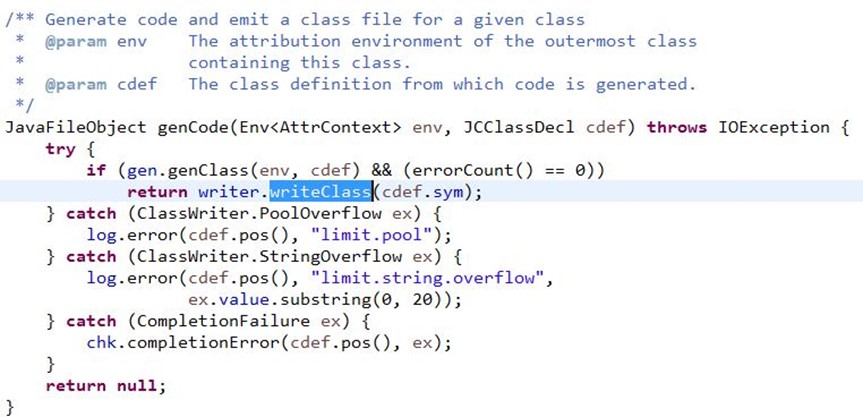
完成转换后,由com.sun.tools.javac.main.JavaCompiler的writer()方法写到磁盘Class文件,如下:
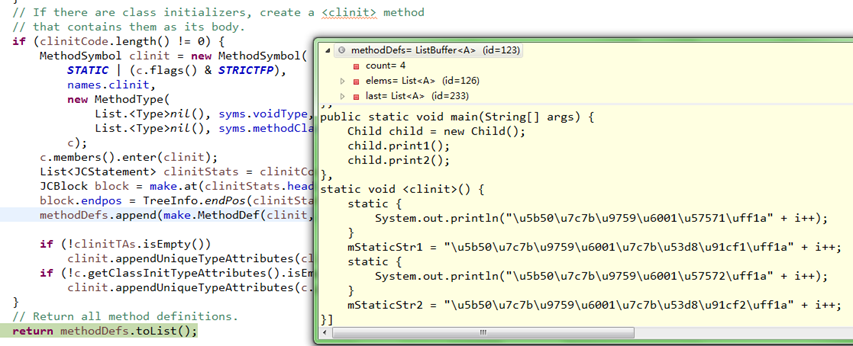
3、类构造器<clinit>()与实例构造器<init>()
另外,还进行了少量代码添加,如类构造器<clinit>()到语法树中;
注意,通过前面的分析可以知道,对于实例构造器<init>(),如果程序代码中定义有构造函数,它在解析的语法分析阶段被重命名为<init>();如果没有定义构造函数,则实例构造器<init>()是在填充符号表时添加的。
并把需要初始化的变量以及需要执行的语句块添加到相应的构造器中;
Gen.genClass()中会调用Gen.normalizeDefs()方法,进行添加实例构造器<init>()和类构造器<clinit>()到语法树;
用下面的程序测试Parent.java和Child.java,看添加了什么内容到两个构造器中,Parent.java如下:
package com.jvmtest;
public class Parent {
static int i = 1;
{
System.out.println("父类实例块1:" + i++);
}
static {
System.out.println("父类静态块1:" + i++);
}
private String mStr1="父类实例变量1:" + i++;
private static String mStaticStr1="父类静态类变量1:" + i++;
{
System.out.println("父类实例块2:" + i++);
}
static {
System.out.println("父类静态块2:" + i++);
}
private String mStr2="父类实例变量2:" + i++;
private static String mStaticStr2="父类静态类变量2:" + i++;
public Parent() {
System.out.println("父类构造器:" + i++);
}
public void print1() {
String str="父类局部变量:" + i++;
System.out.println("父类方法print1():\n " +
mStaticStr1 + "\n " + mStaticStr2 + "\n " +
mStr1 + "\n " + mStr2 + "\n " +
str);
}
}Child.java如下:
package com.jvmtest;
public class Child extends Parent{
{
System.out.println("子类实例块1:" + i++);
}
static {
System.out.println("子类静态块1:" + i++);
}
private String mStr1="子类实例变量1:" + i++;
private static String mStaticStr1="子类静态类变量1:" + i++;
{
System.out.println("子类实例块2:" + i++);
}
static {
System.out.println("子类静态块2:" + i++);
}
private String mStr2="子类实例变量2:" + i++;
private static String mStaticStr2="子类静态类变量2:" + i++;
public Child() {
System.out.println("子类构造器:" + i++);
}
public void print2() {
String str="子类局部变量:" + i++;
System.out.println("子类方法print2():\n " +
mStaticStr1 + "\n " + mStaticStr2 + "\n " +
mStr1 + "\n " + mStr2 + "\n " +
str);
}
public static void main(String[] args){
Child child = new Child();
child.print1();
child.print2();
}
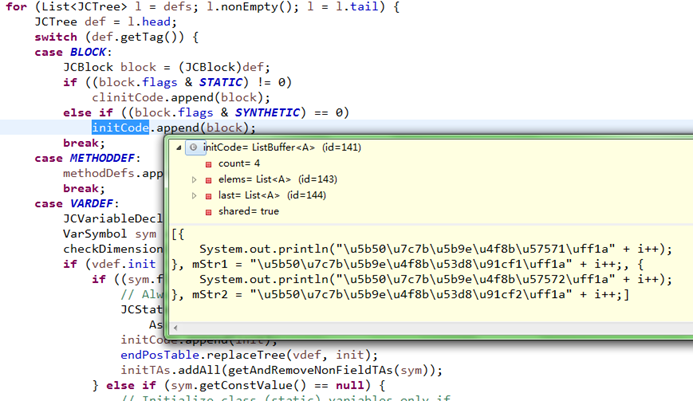
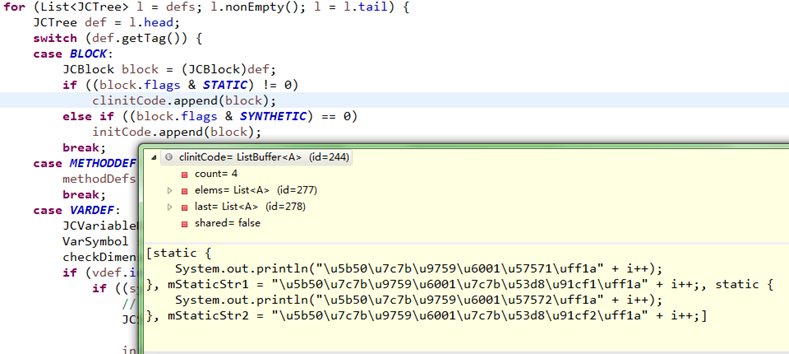
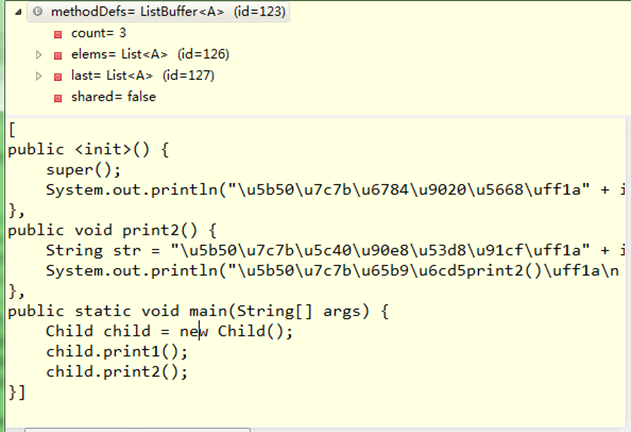
}1)、它先把一个类的定义声明符号分为三类保存
A、initCode:保存需要初始化执行的实例变量和块(非static);
B、clinitCode:保存需要初始化执行的类变量和块(static);
C、methodDefs:保存方法定义符号;
程序代码分类后的如下:
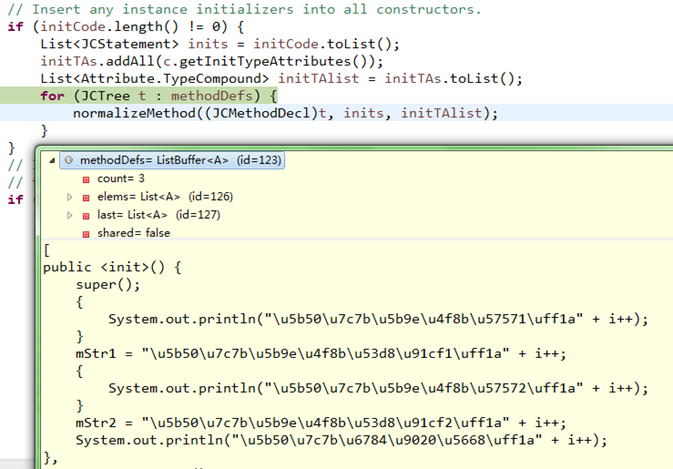
2)、把initCode中的定义插入到实例构造器<init>()中
注意,对于实例构造器<init>(),如果程序代码中定义有构造函数,它在解析的语法分析阶段被重命名为<init>();
如果没有定义构造函数,则实例构造器<init>()是作为默认构造函数,是在填充符号表时添加的;
另外<init>()中的super()调用父类<init>(),
在语义分析的标注检查在方法检查时,如果发现自己定义的类构造函数没有显式调用super()或this(),会添加super()的父类构造函数调用;
如果没有自定定义任何构造函数,在前面填充符号表时添加的默认构造函数就已经含有super()了;
initCode插入<init>()原有代码的前面;
添加后的<init>()如下:
3)、把clinitCode中的定义插入到类构造器<clinit>()中
类构造器<clinit>()是在这时候创建的;
然后clinitCode插入到<clinit>(),再把<clinit>()放到方法定义methodDefs的后面,如下:
可以看到,<clinit>()并不调用父类的<clinit>(),这是由JVM保证的其执行;
我们运行上面的程序,可以看到输出(后面的数字表明自执行顺序):
测试表明执行顺序如下:
先执行类构造器<clinit>():
父类静态成员变量初始化、静态语句块(static{})执行;
子类静态成员变量初始化、静态语句块(static{})执行;
静态成员变量与静态语句块不区分,按照在代码中的位置顺序执行;
不调用父类的类构造器,由JVM保证其执行;
而后执行实例构造器<init>():
父类实例成员变量初始化、实例语句块({})执行;
父类实例构造器调用;
实例成员变量初始化、实例语句块({})执行;
实例成员变量、实例语句块不区分,按照在代码中的位置顺序执行;
<init>()无论如何(自定义或编译器添加)都有父类<init>()(super())调用;
而由于initCode插入<init>()原有代码的前面,所以实例成员变量初始化、实例语句块({})执行输出要先于构造器原来的代码执行输出;
即按照先父类,后子类;先静态、后实例的原则;
另外,<clinit>()是在Class文件被类加载器加载的时候(初始化阶段)执行,并且只执行一次(加锁 );而<init>()在每次实例化对象时都会执行。
到这里,我们大体了解javac把Java源代码编译成Class文件的过程,可以用JDK提供的javap工具查看反编译后的文件,如查看JavacTest.class文件:"javap -verbose JavacTest > JavacTest.txt"输出到文件、
后面我们将分别去了解: 前端编译生成的Class文件结构、以及JIT编译--在运行时把Class文件字节码编译成本地机器码的过程……
【参考资料】
1、javac源码
2、《编译原理》第二版
3、《深入分析Java Web技术内幕》修订版 第4章
4、《深入理解Java虚拟机:JVM高级特性与最佳实践》第二版 第10章
5、《The Java Virtual Machine Specification》Java SE 8 Edition:https://docs.oracle.com/javase/specs/jvms/se8/html/index.html
6、实时Java,第2部分: 比较编译技术--本地 Java 代码的静态编译和动态编译中的问题:www.ibm.com/developerworks/cn/java/j-rtj2/
7、很多文章都提到JVM对class文件的编译,那么编译后的文件是在内存里还是在哪?怎么查看?:https://www.zhihu.com/question/52487484/answer/130785455