认识Hystrix
Hystrix是Netflix开源的一款容错框架,包含常用的容错方法:线程隔离、信号量隔离、降级策略、熔断技术。
在高并发访问下,系统所依赖的服务的稳定性对系统的影响非常大,依赖有很多不可控的因素,比如网络连接变慢,资源突然繁忙,暂时不可用,服务脱机等。我们要构建稳定、可靠的分布式系统,就必须要有这样一套容错方法。
本文主要讨论线程隔离技术。
为什么要做线程隔离
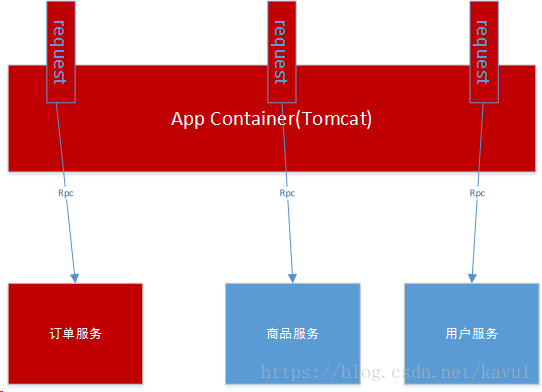
比如我们现在有3个业务调用分别是查询订单、查询商品、查询用户,且这三个业务请求都是依赖第三方服务-订单服务、商品服务、用户服务。三个服务均是通过RPC调用。当查询订单服务,假如线程阻塞了,这个时候后续有大量的查询订单请求过来,那么容器中的线程数量则会持续增加直致CPU资源耗尽到100%,整个服务对外不可用,集群环境下就是雪崩。如下图
订单服务不可用.png:
整个tomcat容器不可用.png

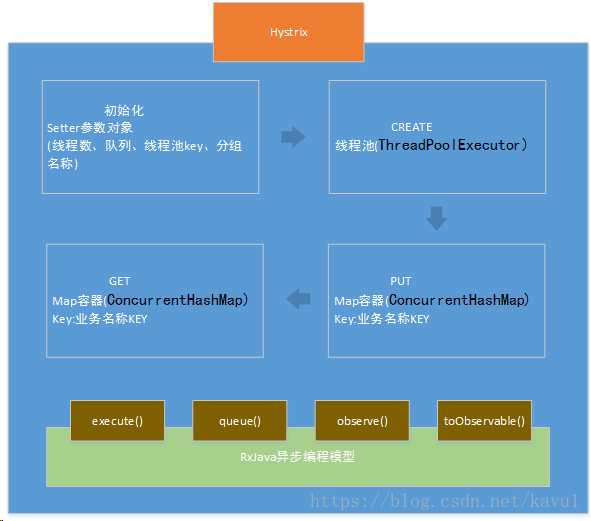
Hystrix是如何通过线程池实现线程隔离的
Hystrix通过命令模式,将每个类型的业务请求封装成对应的命令请求,比如查询订单->订单Command,查询商品->商品Command,查询用户->用户Command。每个类型的Command对应一个线程池。创建好的线程池是被放入到ConcurrentHashMap中,比如查询订单:
final static ConcurrentHashMap<String, HystrixThreadPool> threadPools = new ConcurrentHashMap<String, HystrixThreadPool>();
threadPools.put(“hystrix-order”, new HystrixThreadPoolDefault(threadPoolKey, propertiesBuilder));
当第二次查询订单请求过来的时候,则可以直接从Map中获取该线程池。具体流程如下图:
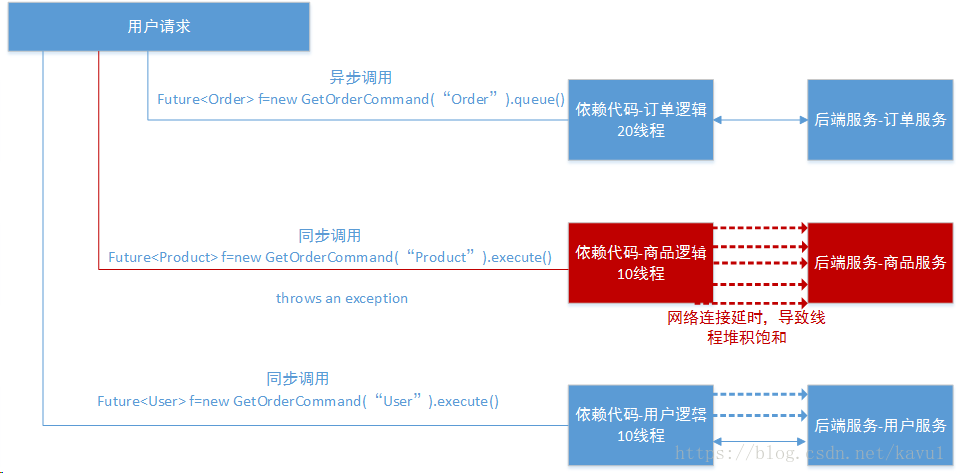
hystrix线程执行过程和异步化.png
创建线程池中的线程的方法,查看源代码如下:
public ThreadPoolExecutor getThreadPool(final HystrixThreadPoolKey threadPoolKey, HystrixProperty<Integer> corePoolSize, HystrixProperty<Integer> maximumPoolSize, HystrixProperty<Integer> keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
ThreadFactory threadFactory = null;
if (!PlatformSpecific.isAppEngineStandardEnvironment()) {
threadFactory = new ThreadFactory() {
protected final AtomicInteger threadNumber = new AtomicInteger(0);
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r, "hystrix-" + threadPoolKey.name() + "-" + threadNumber.incrementAndGet());
thread.setDaemon(true);
return thread;
}
};
} else {
threadFactory = PlatformSpecific.getAppEngineThreadFactory();
}
final int dynamicCoreSize = corePoolSize.get();
final int dynamicMaximumSize = maximumPoolSize.get();
if (dynamicCoreSize > dynamicMaximumSize) {
logger.error("Hystrix ThreadPool configuration at startup for : " + threadPoolKey.name() + " is trying to set coreSize = " +
dynamicCoreSize + " and maximumSize = " + dynamicMaximumSize + ". Maximum size will be set to " +
dynamicCoreSize + ", the coreSize value, since it must be equal to or greater than the coreSize value");
return new ThreadPoolExecutor(dynamicCoreSize, dynamicCoreSize, keepAliveTime.get(), unit, workQueue, threadFactory);
} else {
return new ThreadPoolExecutor(dynamicCoreSize, dynamicMaximumSize, keepAliveTime.get(), unit, workQueue, threadFactory);
}
}
执行Command的方式一共四种,直接看官方文档(https://github.com/Netflix/Hystrix/wiki/How-it-Works),具体区别如下:
-
execute():以同步堵塞方式执行run()。调用execute()后,hystrix先创建一个新线程运行run(),接着调用程序要在execute()调用处一直堵塞着,直到run()运行完成。
-
queue():以异步非堵塞方式执行run()。调用queue()就直接返回一个Future对象,同时hystrix创建一个新线程运行run(),调用程序通过Future.get()拿到run()的返回结果,而Future.get()是堵塞执行的。
-
observe():事件注册前执行run()/construct()。第一步是事件注册前,先调用observe()自动触发执行run()/construct()(如果继承的是HystrixCommand,hystrix将创建新线程非堵塞执行run();如果继承的是HystrixObservableCommand,将以调用程序线程堵塞执行construct()),第二步是从observe()返回后调用程序调用subscribe()完成事件注册,如果run()/construct()执行成功则触发onNext()和onCompleted(),如果执行异常则触发onError()。
-
toObservable():事件注册后执行run()/construct()。第一步是事件注册前,调用toObservable()就直接返回一个Observable对象,第二步调用subscribe()完成事件注册后自动触发执行run()/construct()(如果继承的是HystrixCommand,hystrix将创建新线程非堵塞执行run(),调用程序不必等待run();如果继承的是HystrixObservableCommand,将以调用程序线程堵塞执行construct(),调用程序等待construct()执行完才能继续往下走),如果run()/construct()执行成功则触发onNext()和onCompleted(),如果执行异常则触发onError()
-
注:
execute()和queue()是在HystrixCommand中,observe()和toObservable()是在HystrixObservableCommand 中。从底层实现来讲,HystrixCommand其实也是利用Observable实现的(看Hystrix源码,可以发现里面大量使用了RxJava),尽管它只返回单个结果。HystrixCommand的queue方法实际上是调用了toObservable().toBlocking().toFuture(),而execute方法实际上是调用了queue().get()。
如何应用到实际代码中
package myHystrix.threadpool;
import com.netflix.hystrix.*;
import org.junit.Test;
import java.util.List;
import java.util.concurrent.Future;
/**
* Created by wangxindong on 2017/8/4.
*/
public class GetOrderCommand extends HystrixCommand<List> {
OrderService orderService;
public GetOrderCommand(String name){
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("ThreadPoolTestGroup"))
.andCommandKey(HystrixCommandKey.Factory.asKey("testCommandKey"))
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey(name))
.andCommandPropertiesDefaults(
HystrixCommandProperties.Setter()
.withExecutionTimeoutInMilliseconds(5000)
)
.andThreadPoolPropertiesDefaults(
HystrixThreadPoolProperties.Setter()
.withMaxQueueSize(10) //配置队列大小
.withCoreSize(2) // 配置线程池里的线程数
)
);
}
@Override
protected List run() throws Exception {
return orderService.getOrderList();
}
public static class UnitTest {
@Test
public void testGetOrder(){
// new GetOrderCommand("hystrix-order").execute();
Future<List> future =new GetOrderCommand("hystrix-order").queue();
}
}
}
总结
执行依赖代码的线程与请求线程(比如Tomcat线程)分离,请求线程可以自由控制离开的时间,这也是我们通常说的异步编程,Hystrix是结合RxJava来实现的异步编程。通过设置线程池大小来控制并发访问量,当线程饱和的时候可以拒绝服务,防止依赖问题扩散。
线程隔离.png
线程隔离的优点:
- 1、:应用程序会被完全保护起来,即使依赖的一个服务的线程池满了,也不会影响到应用程序的其他部分。
- 2、:我们给应用程序引入一个新的风险较低的客户端lib的时候,如果发生问题,也是在本lib中,并不会影响到其他内容,因此我们可以大胆的引入新lib库。
- 3、:当依赖的一个失败的服务恢复正常时,应用程序会立即恢复正常的性能。
- 4、:如果我们的应用程序一些参数配置错误了,线程池的运行状况将会很快显示出来,比如延迟、超时、拒绝等。同时可以通过动态属性实时执行来处理纠正错误的参数配置。
- 5、:如果服务的性能有变化,从而需要调整,比如增加或者减少超时时间,更改重试次数,就可以通过线程池指标动态属性修改,而且不会影响到其他调用请求。
- 6、:除了隔离优势外,hystrix拥有专门的线程池可提供内置的并发功能,使得可以在同步调用之上构建异步的外观模式,这样就可以很方便的做异步编程(Hystrix引入了Rxjava异步框架)。
尽管线程池提供了线程隔离,我们的客户端底层代码也必须要有超时设置,不能无限制的阻塞以致线程池一直饱和。
线程隔离的缺点:
-
1、线程池的主要缺点就是它增加了计算的开销,每个业务请求(被包装成命令)在执行的时候,会涉及到请求排队,调度和上下文切换。不过Netflix公司内部认为线程隔离开销足够小,不会产生重大的成本或性能的影响。
-
2、Netflix API每天使用线程隔离处理10亿次Hystrix Command执行。 每个API实例都有40多个线程池,每个线程池中有5-20个线程(大多数设置为10个)。
(官方原话:The Netflix API processes 10+ billion Hystrix Command executions per day using thread isolation. Each API instance has 40+ thread-pools with 5–20 threads in each (most are set to 10).) -
3、对于不依赖网络访问的服务,比如只依赖内存缓存这种情况下,就不适合用线程池隔离技术,而是采用信号量隔离,后面文章会介绍。
因此我们可以放心使用Hystrix的线程隔离技术,来防止雪崩这种可怕的致命性线上故障。
hystrix的线程隔离技术除了线程池,还有另外一种方式:信号量。
线程池和信号量的区别
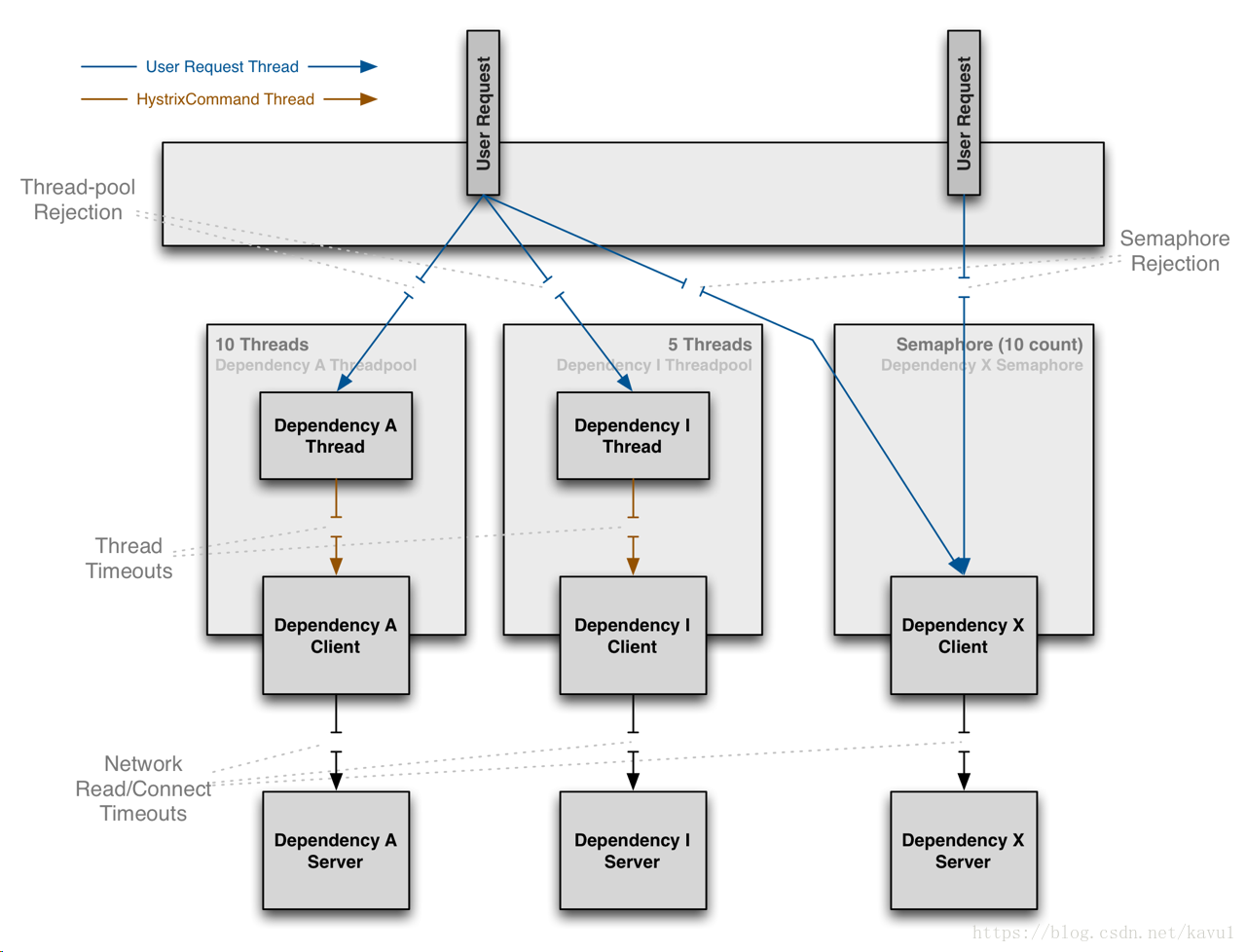
在《Hystrix线程隔离技术解析-线程池》一文最后,我们谈到了线程池的缺点,当我们依赖的服务是极低延迟的,比如访问内存缓存,就没有必要使用线程池的方式,那样的话开销得不偿失,而是推荐使用信号量这种方式。下面这张图说明了线程池隔离和信号量隔离的主要区别:线程池方式下业务请求线程和执行依赖的服务的线程不是同一个线程;信号量方式下业务请求线程和执行依赖服务的线程是同一个线程
信号量和线程池的区别.png
如何使用信号量来隔离线程
将属性execution.isolation.strategy设置为SEMAPHORE ,象这样 ExecutionIsolationStrategy.SEMAPHORE,则Hystrix使用信号量而不是默认的线程池来做隔离。
public class CommandUsingSemaphoreIsolation extends HystrixCommand {
private final int id;
public CommandUsingSemaphoreIsolation(int id) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("ExampleGroup"))
// since we're doing work in the run() method that doesn't involve network traffic
// and executes very fast with low risk we choose SEMAPHORE isolation
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
.withExecutionIsolationStrategy(ExecutionIsolationStrategy.SEMAPHORE)));
this.id = id;
}
@Override
protected String run() {
// a real implementation would retrieve data from in memory data structure
// or some other similar non-network involved work
return "ValueFromHashMap_" + id;
}
}
总结
信号量隔离的方式是限制了总的并发数,每一次请求过来,请求线程和调用依赖服务的线程是同一个线程,那么如果不涉及远程RPC调用(没有网络开销)则使用信号量来隔离,更为轻量,开销更小。
转载自:https://www.cnblogs.com/xiaohanlin/p/8012561.html
间接转载请注明出处: http://www.jianshu.com/p/df1525d58c20
参考资料:https://github.com/Netflix/Hystrix/wiki