版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/83508403
1 YARN 产生背景
- MapReduce1.x 存在的问题:单点故障和 节点压力大不易扩展;
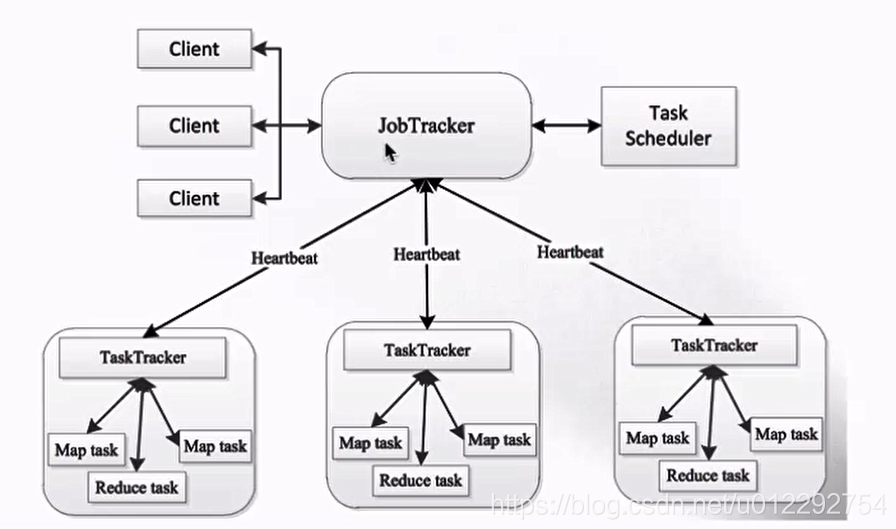
- Hadoop1.x 时,MapReduce -> Master/Slave 架构,1个 JobTracker 带多个 TaskTracker
- JobTracker : 负责资源管理和作业调度
- TaskTracker: 定期向 JT 汇报 本节点的健康状况、资源使用情况、作业执行情况;接受来自JT 的命令——启动任务
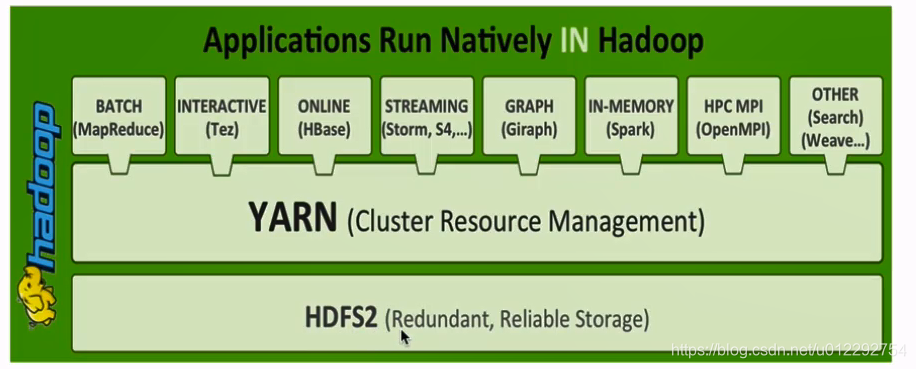
- YARN:不同计算框架可以共享同一个 HDFS 集群上的数据,享受整体的资源调度
2 YARN 的架构
http://archive-primary.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0/hadoop-yarn/hadoop-yarn-site/YARN.html
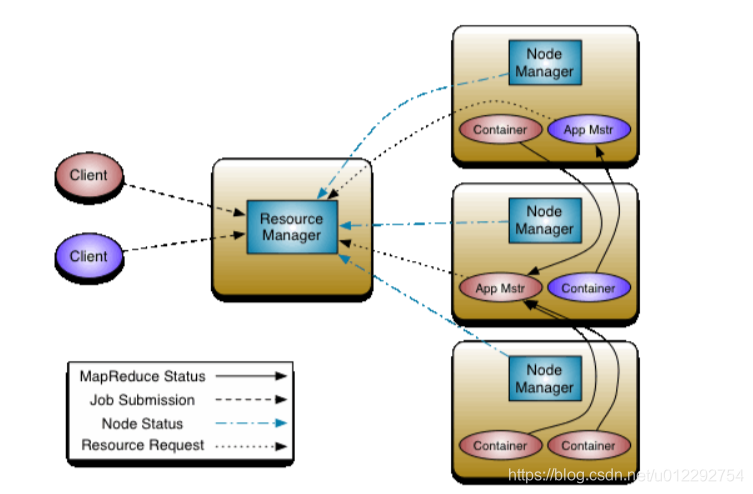
- ResourceManager:RM,整个集群同一时间提供服务的RM只有一个,负责集群资源的统一管理和调度,处理客户端的请求——提交一个作业,杀死一个作业;监控NM,一旦某个NM挂了,那么该 NM 上运行的任务需要告诉 AM;
- NodeManager:NM,整个集群有多个,负责本节点资源管理和使用,定时向 RM 汇报本节点的资源使用情况;接收并处理来自 RM 的各种命令:启动 Container; 处理来自 AM 的命令;单个节点的资源管理
- **ApplicationMaster **: AM,负责应用程序的管理,每个应用程序对应一个:MR,Spark;为应用程序向 RM 申请资源(core,memory),分配给内部的 task;需要与 NM 通信:启动/停止 task,task 是运行在 container 里面, AM也是运行在 container里面;
- Container:封装了CPU,Memory 等资源的一个容器,是一个任务运行环境的抽象
- Client:提交作业,查看进度
3 YARN 环境搭建
3.1 mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3.2 yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
3.3 启动 YARN
[hadoop@node1 ~]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/apps/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-resourcemanager-node1.out
node1: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-nodemanager-node1.out
浏览器访问 http://node1:8088
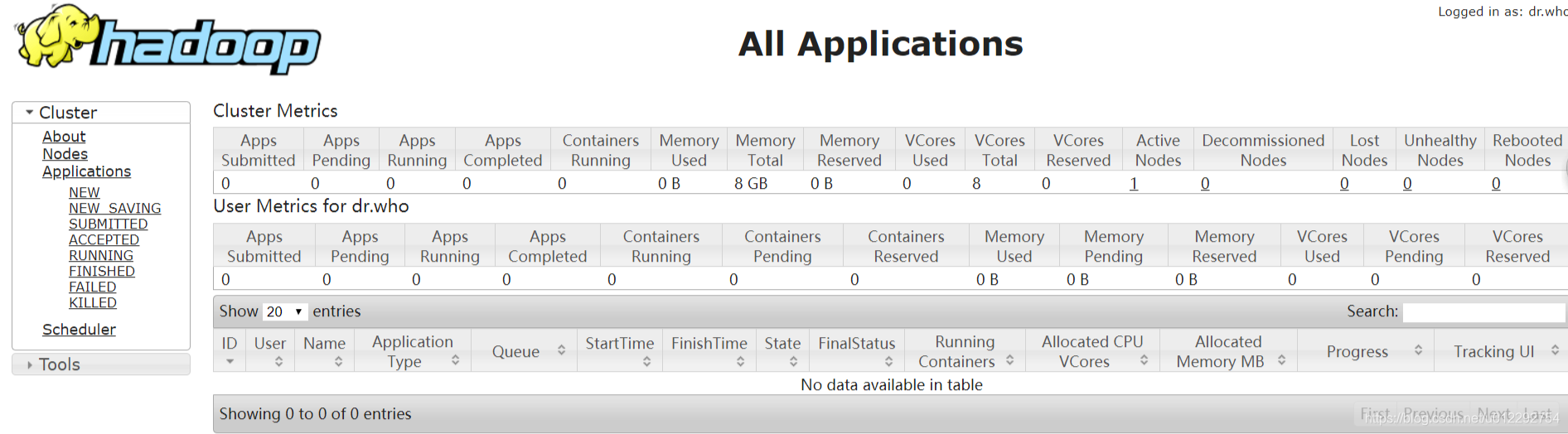
4 提交 MapReduce 作业到 YARN
自带案例 /home/hadoop/apps/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce2
hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar
[hadoop@node1 mapreduce2]$ hadoop jar
RunJar jarFile [mainClass] args...
[hadoop@node1 mapreduce2]$ hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar
An example program must be given as the first argument.
Valid program names are:
aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files.
aggregatewordhist: An Aggregate based map/reduce program that computes the histogram of the words in the input files.
bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi.
dbcount: An example job that count the pageview counts from a database.
distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi.
grep: A map/reduce program that counts the matches of a regex in the input.
join: A job that effects a join over sorted, equally partitioned datasets
multifilewc: A job that counts words from several files.
pentomino: A map/reduce tile laying program to find solutions to pentomino problems.
pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method.
randomtextwriter: A map/reduce program that writes 10GB of random textual data per node.
randomwriter: A map/reduce program that writes 10GB of random data per node.
secondarysort: An example defining a secondary sort to the reduce.
sort: A map/reduce program that sorts the data written by the random writer.
sudoku: A sudoku solver.
teragen: Generate data for the terasort
terasort: Run the terasort
teravalidate: Checking results of terasort
wordcount: A map/reduce program that counts the words in the input files.
wordmean: A map/reduce program that counts the average length of the words in the input files.
wordmedian: A map/reduce program that counts the median length of the words in the input files.
wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files.
[hadoop@node1 mapreduce2]$
[hadoop@node1 mapreduce2]$ hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi
Usage: org.apache.hadoop.examples.QuasiMonteCarlo <nMaps> <nSamples>
Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]
[hadoop@node1 mapreduce2]$
[hadoop@node1 mapreduce2]$ hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi 2 3
Number of Maps = 2
Samples per Map = 3
18/10/29 22:19:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Wrote input for Map #0
Wrote input for Map #1
Starting Job
18/10/29 22:19:02 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
18/10/29 22:19:03 INFO input.FileInputFormat: Total input paths to process : 2
18/10/29 22:19:04 INFO mapreduce.JobSubmitter: number of splits:2
18/10/29 22:19:04 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1540822729980_0001
18/10/29 22:19:04 INFO impl.YarnClientImpl: Submitted application application_1540822729980_0001
18/10/29 22:19:04 INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1540822729980_0001/
18/10/29 22:19:04 INFO mapreduce.Job: Running job: job_1540822729980_0001
18/10/29 22:19:16 INFO mapreduce.Job: Job job_1540822729980_0001 running in uber mode : false
18/10/29 22:19:16 INFO mapreduce.Job: map 0% reduce 0%
18/10/29 22:19:26 INFO mapreduce.Job: map 50% reduce 0%
18/10/29 22:19:27 INFO mapreduce.Job: map 100% reduce 0%
18/10/29 22:19:32 INFO mapreduce.Job: map 100% reduce 100%
18/10/29 22:19:33 INFO mapreduce.Job: Job job_1540822729980_0001 completed successfully
18/10/29 22:19:33 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=50
FILE: Number of bytes written=335472
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=522
HDFS: Number of bytes written=215
HDFS: Number of read operations=11
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=15859
Total time spent by all reduces in occupied slots (ms)=4321
Total time spent by all map tasks (ms)=15859
Total time spent by all reduce tasks (ms)=4321
Total vcore-seconds taken by all map tasks=15859
Total vcore-seconds taken by all reduce tasks=4321
Total megabyte-seconds taken by all map tasks=16239616
Total megabyte-seconds taken by all reduce tasks=4424704
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=36
Map output materialized bytes=56
Input split bytes=286
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=56
Reduce input records=4
Reduce output records=0
Spilled Records=8
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=245
CPU time spent (ms)=1260
Physical memory (bytes) snapshot=458809344
Virtual memory (bytes) snapshot=8175378432
Total committed heap usage (bytes)=262033408
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=236
File Output Format Counters
Bytes Written=97
Job Finished in 30.938 seconds
Estimated value of Pi is 4.00000000000000000000
[hadoop@node1 mapreduce2]$