目录
账号密码登陆器(for,while,break,continue):
前言
自己学习python的学习记录,自己学习python的历程,有些东西知道就未记录,代码都是自己手敲的,不断学习,不断记录。
视频地址:https://www.bilibili.com/video/av29247220/?p=58
或:https://www.bilibili.com/video/av13690129?p=59
参考:1. http://www.cnblogs.com/yuanchenqi/articles/5782764.html
2. http://www.cnblogs.com/resn/p/5776403.html
3. http://www.cnblogs.com/alex3714/articles/5465198.html
python基础
变量
声明变量
| 1 2 3 |
|
上述代码声明了一个变量,变量名为: name,变量name的值为:"Alex Li"
变量定义的规则:
-
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield'] - 变量名区分大小写
九九乘法表实现
#九九乘法表
num = 1
while num <= 9:
first = 1
while first <= num:
print(str(num)+"*"+str(first)+'='+str(num*first),end="\t")
first += 1
num += 1
print()注释:
#
“”“。。。。。”“” :多行注释,多行赋值
‘’‘。。。。。’‘’
msg = '''hello 1
hello 2
hello 3
'''
print(msg)Pycharm设置:
代码开头自动生成信息:

pycharm多行注释快捷键ctrl+?
格式化输出
占位符
%s s=string
%d d=digit
%f f= float
name = input('Name:')
age = int(input('Age:'))
job = input('Job:')
salary = input('Salary:')
if salary.isdigit(): #长得像不像数字,比如200d,200
salary = int(salary)
else:
#print('must input digit')
#exit()
exit('must input digit')
msg = '''
----------------info of %s----------------
Name:%s
Age:%s
Job:%s
Salary:%s
You will be retired in %s years
------------------end----------------------
'''%(name,name,age,job,salary,65-age)
print(msg)账号密码登陆器(for,while,break,continue):
_user = "alex"
_passwd = 'abc123'
passed_authentication = False #假,不成立
for i in range(3):
username = input("username:")
password = input('password:')
if username == _user and password == _passwd:
print("Welcom %s login..." %_user)
passed_authentication = True
break #中断
else:
print('Invalid username or password')
if not passed_authentication:#只有在False时执行
print('臭流氓')_user = "alex"
_passwd = 'abc123'
for i in range(3):
username = input("username:")
password = input('password:')
if username == _user and password == _passwd:
print("Welcom %s login..." %_user)
break #中断
else:
print('Invalid username or password')
else: #只要for循环正常执行完毕,就会执行else,若break打断则不执行1
print('臭流氓')_user = "alex"
_passwd = 'abc123'
counter = 0
while counter < 3:
username = input("username:")
password = input('password:')
if username == _user and password == _passwd:
print("Welcom %s login..." %_user)
break #中断
else:
print('Invalid username or password')
counter += 1
else: #只要while循环正常执行完毕,就会执行else,若break打断则不执行1
print('臭流氓')_user = "alex"
_passwd = 'abc123'
counter = 0
while counter < 3:
username = input("username:")
password = input('password:')
if username == _user and password == _passwd:
print("Welcom %s login..." %_user)
break #中断
else:
print('Invalid username or password')
counter += 1
if counter == 3:
keep_going_choice = input('还试吗【y/n】')
if keep_going_choice == 'y':
counter = 0
else: #只要while循环正常执行完毕,就会执行else,若break打断则不执行
print('臭流氓')exit_flag = False
for i in range(10):
if i < 5:
continue
print(i)
for j in range(10):
print('layer2',j)
if j == 6:
exit_flag = True
break
if exit_flag:
break列表和元组:
切片:
a = ['1','2','3','4','5']
#切片
print(a[1:]) #一直取到最后一个值
print(a[1:-1]) #一直取到倒数第二个值
print(a[1:-1:1]) #从左往右,以步长为1取值
print(a[1::2]) #从左往右,以步长为2取值
print(a[3::-1]) #从右往左取,负号表示反向取值
print(a[-2::-1]) #从倒数第二个值开始反向取值添加:
#添加
a.append('6') #默认添加到list的最后
print(a)
a.insert(1,'1.5') #添加到指定位置,1是添加的位置(索引为1的位置)
print(a)修改:
a = ['1','2','3','4','5']
#修改
a[1] = '二'
print(a)
a[1:3] = ['二','三']
print(a)删除:
#删除
a.remove('2') #删除指定的元素
a.remove(a[0])
print(a)
b = a.pop(1) #返回删除的元素
print(a)
print(b)
del a[0]
print(a)
del a #删除整个列表对象列表方法:
count
#count
t = ['to','be','or','not','to','be' ].count('to') #计算元素出现的次数
print(t)extend
#extend
a = [1,2,3]
b = [4,5,6]
a.extend(b) #把b添加到a
print(a)
print(b)
c = a + b #连接a,b生成新列表c
index
#index
t = ['to','be','or','not','to','be' ]
print(t.index('be')) #获取元素的位置索引
first_be = t.index('be')
first_list = t[first_be+1:]
second_be = first_list.index('be')
print(first_be + second_be + 1) #取第二个bereverse
#reverse
t = ['to','be','or','not','to','be' ] #倒置列表
t.reverse()
print(t)sort
#sort
x = [4,6,2,7,3,8] #按Ascll码从小到大排序
x.sort()
print(x)
x.sort(reverse=True) #按从大到小
print(x)clear
清空列表,成空列表
身份确认
print(type(x) is list)元组
与列表相比不可修改元组的内容。
#接收多个元素
a,b = [2,3]
print(a)
print(b)
购物车:
#购物车
product_list = [
('Mac',9000),
('kindle',800),
('tesla',90000),
('python book',105),
('bike',2000),
]
saving = input('please input your saving:')
shopping_car = []
if saving.isdigit():
saving = int(saving)
while True:
for i,v in enumerate(product_list,1): #枚举,添加序号,并从1开始
print(i,'>>>>>>>>>',v)
choice = input('input your choice number[exit:q]:')
#验证输入是否合法
if choice.isdigit():
choice = int(choice)
if 0 < choice <= len(product_list):
p_item = product_list[choice - 1]
if p_item[1] < saving: #如果本金足够买该商品
saving -= p_item[1] #本金减去商品要花费的钱
shopping_car.append(p_item) #将商品存入购物车
else:
print('not sufficient funds,residue%s'%saving)
else:
print('there is no this number')
elif choice == 'q':
print('------------------you have buy---------------------')
for i in shopping_car:
print(i)
print('the money is residued %s'%saving)
break
else:
print('输入不规范')字典
键值对,无序存储,键唯一。
增
#增
dic1 = {'name':'alex'}
dic1['age'] = 18
print(dic1)
dic1.setdefault('age',20) #检查是否有age这个键了,若有则不修改
ret = dic1.setdefault('ae',20) #有age这个键了,则返回原age这个键对应的值,若没有则怎加age键值对后,再返回age这个键对应的值
print(dic1)
print(ret)查
#查 通过键去查对应的值
dic3 = {'age':18,'name':'alex','hobby':'girl'}
print(dic3['name'])
print(list(dic3.keys())) # 查所有的键
print(list(dic3.values())) #查所有的值
print(list(dic3.items())) #查所有键值对改
#改
dic4 = {'age':18,'name':'alex','hobby':'girl'}
dic5 = {'1':'11','2':222,'age':20}
dic4.update(dic5) #用dic5的内容更新dic4,若dic4中不存在的就添加,若dic4中也有这个键,则覆盖
print(dic4)删
#删
dic4 = {'age':18,'name':'alex','hobby':'girl'}
del dic4['name']
print(dic4)
dic4.clear() #清空整个字典,空字典
print(dic4)
print(dic4.pop('age')) #返回值
print(dic4)
a = dic4.popitem() #删除最后一个键值对,字典是无序的所以也叫随机删除,以元组的形式返回删除的键值对
print(a,dic4)其他操作
dict6 = dict.fromkeys(['host1','host2','host3'],['test2','test2']) #将第二项参数同意赋值给第一项,第一项为键
print(dict6) #{'host1': ['test2', 'test2'], 'host2': ['test2', 'test2'], 'host3': ['test2', 'test2']}
dict6['host2'][1] = 'test3' #想修改host2对应的值的第二项
print(dict6) #{'host1': ['test2', 'test3'], 'host2': ['test2', 'test3'], 'host3': ['test2', 'test3']}全修改了排序
#排序
dic7 = {'1':'111','2':'110','0':'000'}
print(sorted(dic7))#['0', '1', '2']给键排序
print(sorted(dic7.values()))#['000', '110', '111'] 给值排序
print(sorted(dic7.items())) #[('0', '000'), ('1', '111'), ('2', '110')]按键给键值对排序遍历
#遍历
dic4 = {'age':18,'name':'alex','hobby':'girl'}
for i in dic4:
print(i,dic4[i]) #age 18...
for i in dic4.items():
print(i) #返回元组的形式('age', 18)...
for i,v in dic4.items():
print(i,v) #age 18...字符串
也可以索引切片
重复打印字符串
print('hello'*2)#重复打印 hellohello判断是否包含该内容
print('el' in 'hello') #判断内容是否在字符串中True,列表等也可以用in判断字符串拼接
#字符串拼接
a = '123'
b = 'abc'
c = a + b
print(c)#123abc
#join
c1 = ''.join([a,b])#拼接a和b字符串
c2 = '*****'.join([a,b]) #用*****来拼接a和b字符串
print(c1) #123abc
print(c2) #123*****abc字符串内置方法
#字符串内置方法
st = 'hello kitty'
st1 = 'h\tello kitty'
st2 = 'hello kitty {name} is {age}'
print(st.count('1')) #统计元素个数
print(st.capitalize()) #首字母大写
print(st.center(50,'-')) #打印50个字符,原字符居中,用-补足
print(st.endswith('y')) #判断是否以y结尾
print(st.startswith('he')) #判断是否以he开始
print(st1.expandtabs(tabsize=10)) #设定tab表示几个空格
print(st.find('t')) #查找到该元素第一个元素的位置,找不到返回-1
print(st2.format(name = 'alex',age = '37')) #hello kitty alex is 37
print(st2.format_map({'name':'alex','age':37}))#hello kitty alex is 37
print(st.index('t')) #查找到该元素第一个元素的位置,找不到会直接报错
print(st.isalnum()) #是否只包含数字和字母,汉字,有特殊字符(空格)返回False
print(st.isdigit()) #判断是否是整形数字
print(st.isnumeric())#判断是否是整形数字
print(st.isidentifier()) #判断变量名是否非法
print(st.islower()) #判断是否全小写
print(st.isupper()) #判断是否全大写
print(st.isspace()) #判断是否为空格
print('My Title'.istitle()) #判断是否符合标题格式
print('My Title'.lower()) #大写变小写
print('My Title'.upper()) #小写变大写
print('My Title'.swapcase()) #大小写反转
print('My Title'.ljust(50,'*'))#My Title******************************************
print('My Title'.rjust(50,'*'))#******************************************My Title
print(' My Title'.strip())#去除开头和末尾的空格与换行符,制表符
print(' My Title'.lstrip())#去左
print(' My Title'.rstrip())#去右
print('My Title'.replace('itle','lesson'))#替换
print('My Title Title'.replace('itle','lesson',1))#替换第一个
print('My Title Title'.rfind('t'))#找到右边开始的第一个t的索引,11
print('My Title Title'.split(' '))#以空格分割字符串,['My', 'Title', 'Title']
print('My Title Title'.rsplit('t',1)) #以右边开始分割,分割1次['My Title Ti', 'le']
print('My title title'.title()) #转换成标题格式,My Title Title三级菜单
简单版
menu = {
'北京':{
'朝阳':{
'国贸':{
'CICC':{}
},
'望京':{
'陌陌':{},
'奔驰':{}
}
}
},
'上海':{
}
}
back_flag = False
exit_flag = False
while not back_flag and not exit_flag:
for key in menu:
print(key)
choice = input('>>:').strip()
if choice in menu:
while not back_flag and not exit_flag:
for key2 in menu[choice]:
print(key2)
choice2 = input('>>:').strip()
if choice2 == 'b':
back_flag = True
if choice2 in menu[choice]:
while not back_flag and not exit_flag:
for key3 in menu[choice][choice2]:
print(key3)
choice3 = input('>>:').strip()
if choice3 == 'b':
back_flag = True
if choice3 in menu[choice][choice2]:
while not back_flag and not exit_flag:
for key4 in menu[choice][choice2][choice3]:
print(key4)
choice4 = input('>>:').strip()
print('last level')
if choice4 == 'b':
back_flag = True
if choice4 =='q':
exit_flag = True
else:
back_flag = False
else:
back_flag = False
else:
back_flag = False进阶版
#__author:"Shao Dongheng"
#date:2018/11/1
menu = {
'北京':{
'朝阳':{
'国贸':{
'CICC':{}
},
'望京':{
'陌陌':{},
'奔驰':{}
}
}
},
'上海':{
}
}
current_layer = menu #记录前层,用于循环
#parent_layer = menu
parent_layers = [] #保存父层
while True:
for key in current_layer:
print(key)
choice = input('>>:').strip()
if len(choice) == 0:continue
if choice in current_layer:
#parent_layer = current_layer #将改之前的current_layer赋给parent_layer
parent_layers.append(current_layer)
current_layer = current_layer[choice] #修改成子层
elif choice == 'b':
#current_layer = parent_layer #子层得到父层的值
if parent_layers: #如果列表不为空
current_layer = parent_layers.pop()
else:
print('无此项')编码解码

python3:
默认是unicode。
encode 在编码的同时,会把数据转换成bytes类型;
decode 在解码的同时,会把bytes类型转换成字符。
文件操作
小重山
昨夜寒蛩不住鸣。
惊回千里梦,已三更。
起来独自绕阶行。
人悄悄,帘外月胧明。
白首为功名,旧山松竹老,阻归程。
欲将心事付瑶琴。
知音少,弦断有谁听。读
data = open('小重山','r',encoding='utf8').read()
f = open('小重山','r',encoding='utf8') #读模式只能读,写模式只能写
#data = f.read()
data = f.read(5)#取前5个字符
print(data)
f.close()f = open('小重山','r',encoding='utf8') #读模式只能读,写模式只能写
print(f.readline())
print(f.readline())#会接着读下一行
f.close()
f = open('小重山','r',encoding='utf8') #读模式只能读,写模式只能写
print(f.readlines())#读整个文件,返回列表['昨夜寒蛩不住鸣。\n', '惊回千里梦,已三更。\n', '起来独自绕阶行。\n',
# '人悄悄,帘外月胧明。\n', '白首为功名,旧山松竹老,阻归程。\n', '欲将心事付瑶琴。\n', '知音少,弦断有谁听。']
f.close()
f = open('小重山','r',encoding='utf8') #读模式只能读,写模式只能写
for i in f.readlines():
print(i.strip()) #因为文件中的每一句有一个默认换行,print也有一个自动换行,所以去掉默认换行
f.close()
f = open('小重山','r',encoding='utf8') #读模式只能读,写模式只能写
for i in f: #内部将f作为迭代器,用一个用一个,用一行取一行,但如果要用enumerate()只能是f.readlines
print(i.strip()) #因为文件中的每一句有一个默认换行,print也有一个自动换行,所以去掉默认换行
f.close()写
f = open('小重山','w',encoding='utf8') #会清空文件中的内容
f.write('hello world')
f.close()
f = open('小重山2','w',encoding='utf8') #创建了一个空文件
print(f.fileno()) #返回一个整数,文件描述符,每个文件唯一
f.write('hello world')
f.write('alex\n')#hello worldalex直接跟在上一句后面
f.write('alex') #添加换行符才能换行
f.close()添加
f = open('小重山2','a',encoding='utf8')#向文件添加内容,不可读
f.write('hello world')#直接跟在上一句后面
f.close()光标
f = open('小重山','r',encoding='utf8')
print(f.tell())
print(f.read(4))
print(f.tell()) #光标的位置,字母是返回4,中文返回12
f.seek(3)#移动光标位置到3处,由于是中文,移动一个字符要移动3字节的光标
print(f.tell())
print(f.read())#从光标位置3处开始读,即第二个中文开始
f.close()可读可写
#r+,w+,a+
f = open('小重山','r+',encoding='utf8') #可读可写,从头开始读
print(f.readline())
f.write('岳飞') #紧跟在文件末尾添加内容
f.close()
f = open('小重山2','w+',encoding='utf8') #先清空,可读可写
print(f.readline())
f.write('岳飞')
print(f.tell()) #6,写的时候,光标也移动了
print(f.readline())#光标在文字后面,所以读不到东西
f.close()
f = open('小重山2','a+',encoding='utf8') #a是从文件最后开始向文件追加内容的,光标在最后,可读可写
f.write('岳飞')
print(f.readline())#也读不到东西
f.close()修改
修改文件内容:
得先取出所有内容,在修改后存回去,因为write只会在文件末尾添加内容f_read = open('小重山2','r',encoding='utf8')
f_write = open('小重山3','w',encoding='utf8')
num = 0
for line in f_read:
num += 1
if num == 5:#修改第五行内容
line = ''.join([line.strip(),'alex\n'])#在句尾添加alex
f_write.write(line)字典等类型存入文件
#字典等类型存入文件
a = str({'beijing':{'1':111}}) #转换成字符串
print(type(a))
print(a)#输出的是字符串 '{'beijing':{'1':111}}'
a = eval(a)
print(type(a))
print(a) #输出{'beijing':{'1':111}}with
#with 不需要close
with open('log','r') as f:
f.readline()
#同时管理多个文件对象
with open('log1','r') as f_read,open('log2','w') as f_write:
for line in f_read:
f_write.write(line)ubuntu
以后补吧。先用什么查什么。
。。。
Python进阶基础
深浅拷贝
浅拷贝
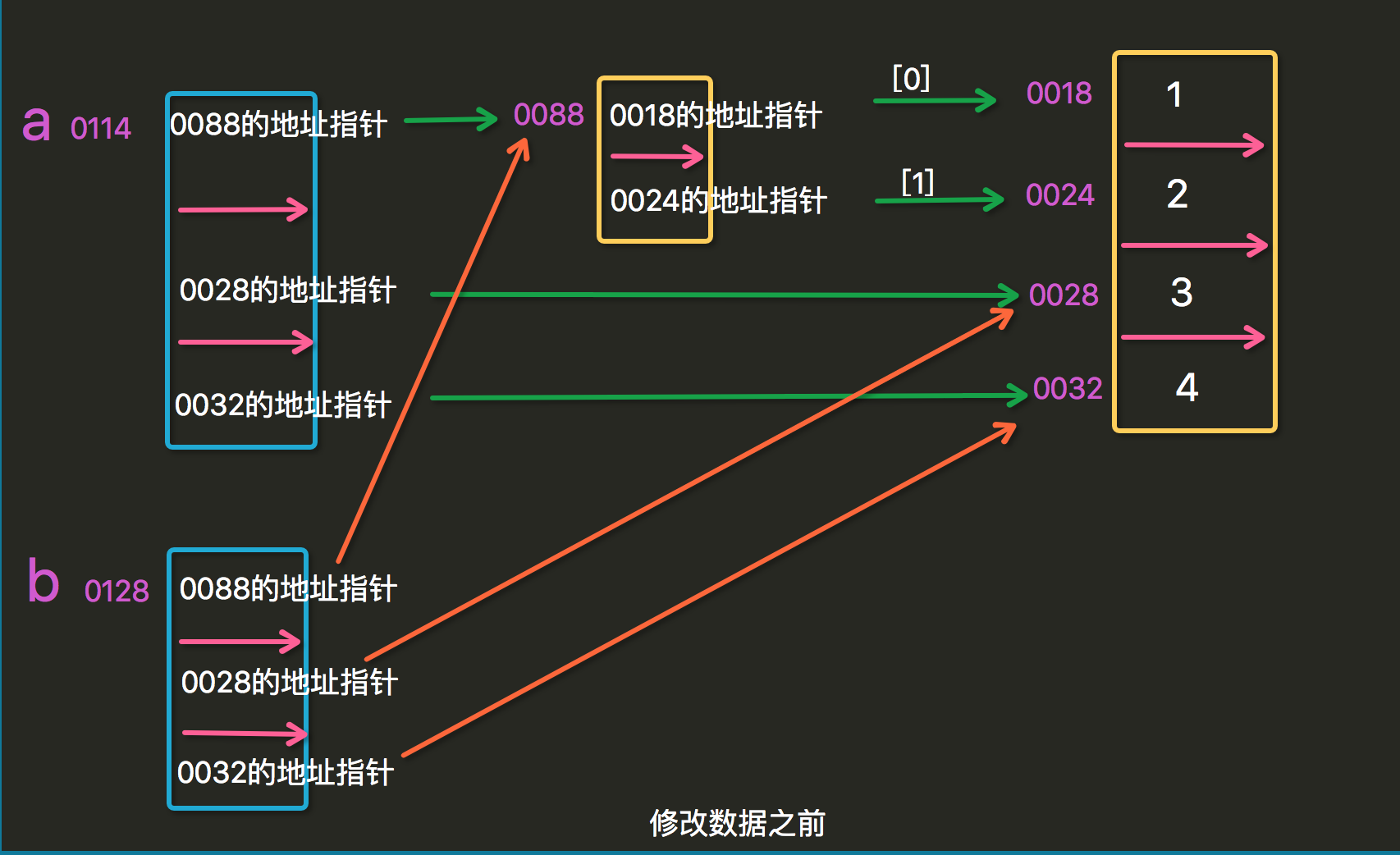
s = [1,'alex','alvin']
print(s)
s1 = s #让s1也指向该列表,并不是拷贝了数据
s1[0] = 2
print(s1) #[2, 'alex', 'alvin']
print(s) #s1的修改影响s,[2, 'alex', 'alvin']
s2 = s.copy() #浅拷贝
s2[0] = 3
print(s2) #[3, 'alex', 'alvin']
print(s) #s2的修改不影响S,[2, 'alex', 'alvin']#浅拷贝
ss = [[1,2],'alex','alvin']
ss1 = ss.copy()
print(ss1)
ss1[0] = 'linux' #修改拷贝数据的第一层
print(ss1) #['linux', 'alex', 'alvin']
print(ss) #[[1, 2], 'alex', 'alvin'],浅拷贝没改变原数据第一层的数据
ss = [[1,2],'alex','alvin']
ss1[0][1] = 3
print(ss1)#[[1, 3], 'alex', 'alvin']
print(ss) #[[1, 3], 'alex', 'alvin'],浅拷贝修改拷贝数据第二层,会使源数据第二层也被改变
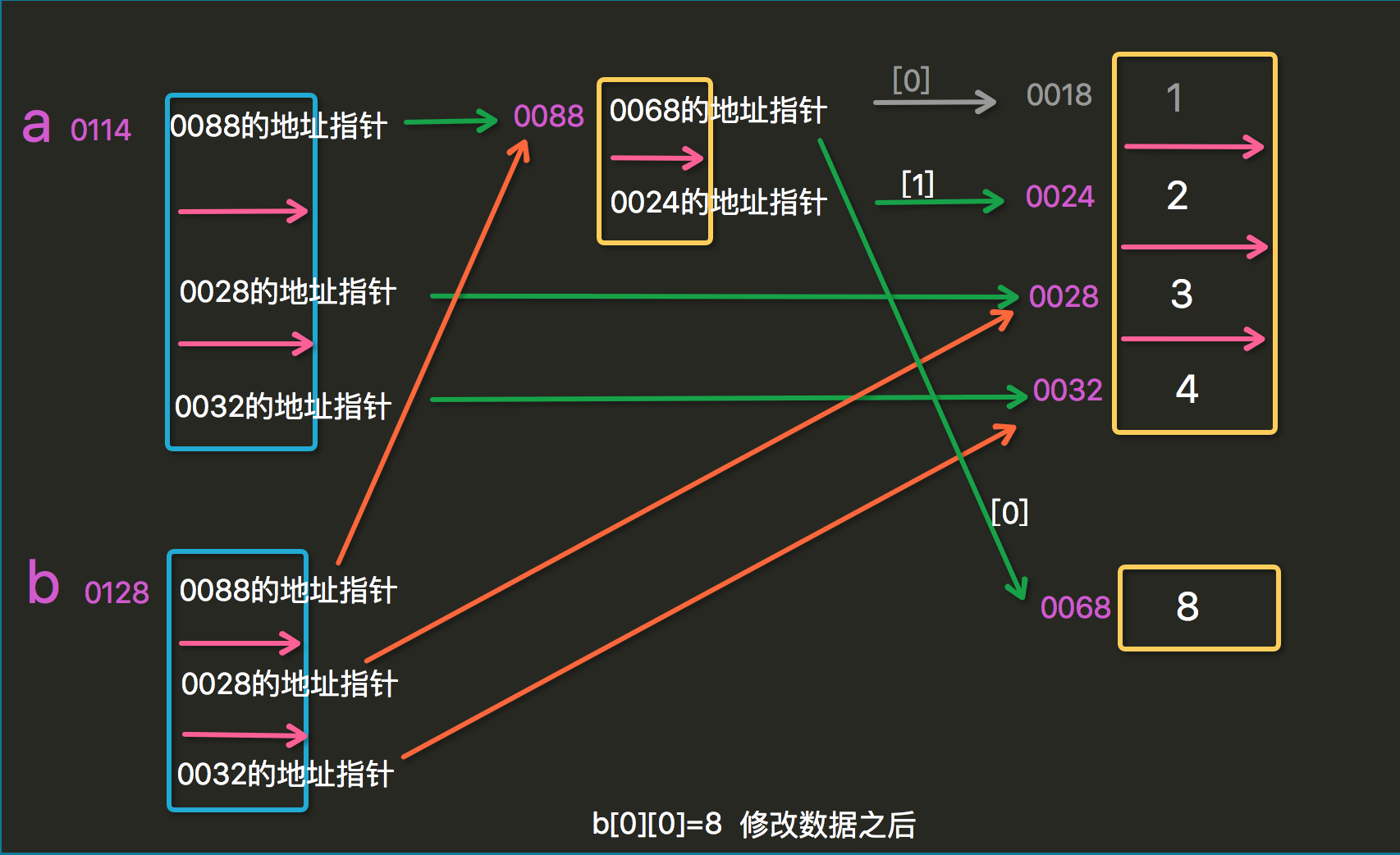
深拷贝
import copy
a = [[1,2],'alex','alvin']
a1 = copy.copy(a) #浅拷贝,修改第二层的拷贝数据会改变原数据,(修改第一层不会)
a1[0][1] = 4
print(a) #[[1, 4], 'alex', 'alvin']
print(a1) #[[1, 4], 'alex', 'alvin']
a2 = copy.deepcopy(a) #深拷贝,修改拷贝数据不会改变原数据
a2[0][1] = 5
print(a) #[[1, 4], 'alex', 'alvin']
print(a2) #[[1, 5], 'alex', 'alvin']集合set
hash
一个对象能被称为 hashable , 它必须有个 hash 值,这个值在整个生命周期都不会变化,而且必须可以进行相等比较,所以一个对象可哈希,它必须实现__hash__() 与 __eq__() 方法。
Python 的某些链接库在内部需要使用hash值,例如往集合中添加对象时会用__hash__() 方法来获取hash值,看它是否与集合中现有对象的hash值相同,如果相同则会舍去不加入,如果不同,则使用__eq__() 方法比较是否相等,以确定是否需要加入其中。
对于 Python 的内建类型来说,只要是创建之后无法修改的(immutable)类型都是 hashable 如字符串,可变动的都是 unhashable的比如:列表、字典、集合,他们在改变值的同时却没有改变id,无法由地址定位值的唯一性,因而无法哈希。我们自定义的类的实例对象默认也是可哈希的(hashable),而hash值也就是它们的id()。
作者:三十六_
链接:https://www.jianshu.com/p/bc5195c8c9cb
集合的创建
#集合的创建
#无序,不重复
a = {'alex li','a'}
print(a) #{'a', 'alex li'}
print(type(a)) #<class 'set'>
s = set('alex li')
print(s) #{'x', ' ', 'e', 'a', 'l', 'i'} 去除了重复的l
s1 = ['alex','1']
ss = set(s1) #列表转集合
print(ss) #{'1', 'alex'}
s2 = list(s1) #转换成列表
print(s2) #['alex', '1']
li = [[1,2],2,'alex']
s3 = set(li) #TypeError: unhashable type: 'list',不可hash的元素不能转集合
print(s3)集合的修改
#修改集合
s1 = ['alex','1']
ss = set(s1) #列表转集合
ss.add('uu') #添加一个元素
print(ss) #{'uu', 'alex', '1'}
ss.update('ops')
print(ss) #{'s', 'alex', 'p', 'uu', 'o', '1'} #将字符串的每个元素当单独元素添加
ss.update([12,'eee']) #添加多个
print(ss) #{'s', '1', 'p', 'uu', 'eee', 12, 'o', 'alex'}集合的删除
#删除
s1 = ['alex','1','2']
ss = set(s1) #列表转集合
ss.remove('2')
print(ss)#{'1', 'alex'}
s1 = ['alex','1','2']
ss = set(s1) #列表转集合
ss.pop() #随机的
print(ss)#{'1', 'alex'}
ss.clear()#空集合
print(ss)
del ss #删除集合
print(ss)
判断
#判断子集
print(set('alex') == set('alexlexlex')) #True,相等价的
print(set('alex') < set('alexwwwww'))#True,是否包含
print(set('alex') < set('alex'))#False,要后者比前者元素多关系测试
#关系测试
a = set([1,2,3,4,5])
b = set([4,5,6,7,8])
#交集
print(a.intersection(b)) #{4, 5}
print(a & b) #{4, 5}
#并集
print(a.union(b)) #{1, 2, 3, 4, 5, 6, 7, 8}
print(a | b) #{1, 2, 3, 4, 5, 6, 7, 8}
#差集
print(a.difference(b)) #{1, 2, 3}
print(a - b)
#对称差集
print(a.symmetric_difference(b)) #{1, 2, 3, 6, 7, 8}除去交集元素
print(a ^ b)
#超集
print(a.issuperset(b)) #False,a是否是b的超集,是否包含b
#子集
print(a.issubset(b))#False,a是否是b的子集