在系统架构设计当中,限流是一个不得不说的话题,因为他太不起眼,但是也太重要了。这点有些像古代镇守边陲的将士,据守隘口,抵挡住外族的千军万马,一旦隘口失守,各种饕餮涌入城内,势必将我们苦心经营的朝堂庙店洗劫一空,之前的所有努力都付之一炬。所以今天我们点了这个话题,一方面是要对限流做下总结,另一方面,抛砖引玉,看看大家各自的系统中,限流是怎么做的。
提到限流,映入脑海的肯定是限制流量四个字,其重点在于如何限。而且这个限,还分为单机限和分布式限,单机限流,顾名思义,就是对部署了应用的docker机或者物理机,进行流量控制,以使得流量的涌入呈现可控的态势,防止过大过快的流量涌入造成应用的性能问题,甚至于失去响应。分布式限流,则是对集群的流量限制,一般这类应用的流量限制集中在一个地方来进行,比如redis,zk或者其他的能够支持分布式限流的组件中。这样当流量过大过快的时候,不至于因为集群中的一台机器被压垮而带来雪崩效应,造成集群应用整体坍塌。
下面我们来细数一下各种限流操作。
1. 基于计数器的单机限流
此类限流,一般是通过应用中的计数器来进行流量限制操作。计数器可以用Integer类型的变量,也可以用Java自带的AtomicLong来实现。原理就是设置一个计数器的阈值,每当有流量进入的时候,将计数器递增,当达到阈值的时候,后续的请求将会直接被抛弃。代码实现如下://限流计数器
private static AtomicLong counter = new AtomicLong();
//限流阈值
private static final long counterMax = 500;
//业务处理方法
public void invoke(Request request) {
try {
//请求过滤
if (counter.incrementAndGet() > counterMax) {
return;
}
//业务逻辑
doBusiness(request);
} catch (Exception e) {
//错误处理
doException(request,e);
} finally {
counter.decrementAndGet();
}
}
上面的代码就是一个简单的基于计数器实现的单机限流。代码简单易行,操作方便,而且可以带来不错的效果。但是缺点也很明显,那就是先来的流量一般都能打进来,后来的流量基本上都会被拒绝。每个请求被执行的概率其实是不一样的,这样就使得早来的用户反而获取不到执行机会,晚来的用户反而有被执行的可能。
所以总结一下此种限流优缺点:
优点:代码简洁,操作方便
缺点:先到先得,先到的请求可执行概率为100%,后到的请求可执行概率小一些,每个请求获得执行的机会是不平等的。
那么,如果想让每个请求获得执行的机会是平等的话,该怎么做呢?
2. 基于随机数的单机限流
此种限流算法,使得请求可被执行的概率是一致的,所以相对于基于计数器实现的限流说来,对用户更加的友好一些。代码如下://获取随机数
private static ThreadLocalRandom ptgGenerator = ThreadLocalRandom.current();
//限流百分比,允许多少流量通过此业务,这里限定为10%
private static final long ptgGuarder = 10;
//业务处理方法
public void invoke(Request request) {
try {
//请求进入,获取百分比
int currentPercentage = ptgGenerator.nextInt(1, 100);
if (currentPercentage <= ptgGuarder) {
//业务处理
doBusiness(request);
} else {
return;
}
} catch (Exception e) {
//错误处理
doException(request, e);
}
}
从上面代码可以看出来,针对每个请求,都会先获取一个随机的1~100的执行率,然后和当前限流阈值(比如当前接口只允许10%的流量通过)相比,如果小于此限流阈值,则放行;如果大于此限流阈值,则直接返回,不做任何处理。和之前的计数器限流比起来,每个请求获得执行的概率是一致的。当然,在真正的业务场景中,用户可以通过动态配置化阈值参数,来控制每分钟通过的流量百分比,或者是每小时通过的流量百分比。但是如果对于突增的高流量,此种方法则有点问题,因为高并发下,每个请求之间进入的时间很短暂,导致nextInt生成的值,大概率是重复的,所以这里需要做的一个优化点,就是为其寻找合适的seed,用于优化nextInt生成的值。
优点:代码简洁,操作简便,每个请求可执行的机会是平等的。
缺点:不适合应用突增的流量。
3. 基于时间段的单机限流
有时候,我们的应用只想在单位时间内放固定的流量进来,比如一秒钟内只允许放进来100个请求,其他的请求抛弃。那么这里的做法有很多,可以基于计数器限流实现,然后判断时间,但是此种做法稍显复杂,可控性不是特别好。
那么这里我们就要用到缓存组件来实现了。原理是这样的,首先请求进来,在guava中设置一个key,此key就是当前的秒数,秒数的值就是放进来的请求累加数,如果此累加数到100了,则拒绝后续请求即可。代码如下://获取guava实例
private static LoadingCache<Long, AtomicLong> guava = CacheBuilder.newBuilder()
.expireAfterWrite(5, TimeUnit.SECONDS)
.build(new CacheLoader<Long, AtomicLong>() {br/>@Override
public AtomicLong load(Long seconds) throws Exception {
return null;
}
});
//每秒允许通过的请求数
private static final long requestsPerSecond = 100;
//业务处理方法
public void invoke(Request request) {
try {
//guava key
long guavaKey = System.currentTimeMillis() / 1000;
//请求累加数
long guavaVal = guava.get(guavaKey).incrementAndGet();
if (guavaVal <= requestsPerSecond) {
//业务处理
doBusiness(request);
} else {
return;
}
} catch (Exception e) {
//错误处理
doException(request, e);
}
}
从上面的代码中可以看到,我们巧妙的利用了缓存组件的特性来实现。每当有请求进来,缓存组件中的key值累加,到达阈值则拒绝后续请求,这样很方便的实现了时间段限流的效果。虽然例子中给的是按照秒来限流的实现,我们可以在此基础上更改为按照分钟或者按照小时来实现的方案。
优点:操作简单,可靠性强
缺点:突增的流量,会导致每个请求都会访问guava,由于guava是堆内内存实现,势必会对性能有一点点影响。其实如果怕限流影响到其他内存计算,我们可以将此限流操作用堆外内存组件来实现,比如利用OHC或者mapdb等。也是比较好的备选方案。
4. 基于漏桶算法的单机限流
所谓漏桶( Leaky bucket ),则是指,有一个盛水的池子,然后有一个进水口,有一个出水口,进水口的水流可大可小,但是出水口的水流是恒定的。下图图示可以显示的更加清晰: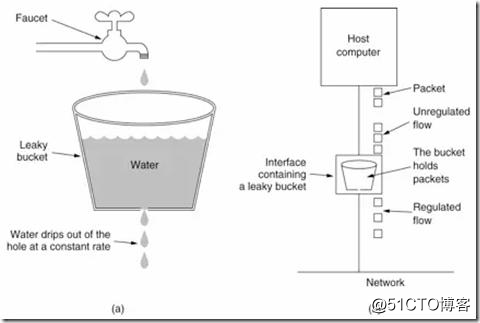
图片描述(最多50字)
从图中我们可以看到,水龙头相当于各端的流量,进入到漏桶中,当流量很小的时候,漏桶可以承载这种流量,出水口按照恒定的速度出水,水不会溢出来。当流量开始增大的时候,漏桶中的出水速度赶不上进水速度,那么漏桶中的水位一直在上涨。当流量再大,则漏桶中的水过满则溢。
由于目前很多MQ,比如rabbitmq等,都属于漏桶算法原理的具体实现,请求过来先入queue队列,队列满了抛弃多余请求,之后consumer端匀速消费队列里面的数据。所以这里不再贴多余的代码。
优点:流量控制效果不错
缺点:不能够很好的应付突增的流量。适合保护性能较弱的系统,但是不适合性能较强的系统。如果性能较强的系统能够应对这种突增的流量的话,那么漏桶算法是不合适的。
5. 基于令牌桶算法的单机限流
所谓令牌桶( Token Bucket ),则是指,请求过来的时候,先去令牌桶里面申请令牌,申请到令牌之后,才能去进行业务处理。如果没有申请到令牌,则操作终止。具体说明如下图: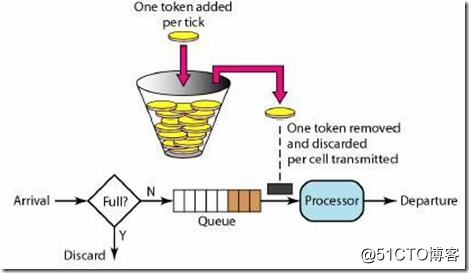
图片描述(最多50字)
由于生成令牌的流量是恒定的,面对突增流量的时候,桶里有足够令牌的情况下,突增流量可以快速的获取到令牌,然后进行处理。从这里可以看出令牌桶对于突增流量的处理是容许的。
由于目前guava组件中已经有了对令牌桶的具体实现类:RateLimiter, 所以我们可以借助此类来实现我们的令牌桶限流。代码如下://指定每秒放1个令牌
private static RateLimiter limiter = RateLimiter.create(1);
//令牌获取超时时间
private static final long acquireTimeout = 1000;
//业务处理方法
public void invoke(Request request) {
try {
//拿到令牌则进行业务处理
if (limiter.tryAcquire(acquireTimeout, TimeUnit.MILLISECONDS)) {
//业务处理
doBusiness(request);
}
//拿不到令牌则退出
else {
return;
}
} catch (Exception e) {
//错误处理
doException(request, e);
}
}
从上面代码我们可以看到,一秒生成一个令牌,那么我们的接口限定为一秒处理一个请求,如果感觉接口性能可以达到1000tps单机,那么我们可以适当的放大令牌桶中的令牌数量,比如800,那么当突增流量过来,会直接拿到令牌然后进行业务处理。但是当令牌桶中的令牌消费完毕之后,那么请求就会被阻塞,直到下一秒另一批800个令牌生成出来,请求才开始继续进行处理。
所以利用令牌桶的优缺点就很明显了:
有点:使用简单,有成熟组件
缺点:适合单机限流,不适合分布式限流。
6. 基于redis lua的分布式限流
由于上面5中限流方式都是单机限流,但是在实际应用中,很多时候我们不仅要做单机限流,还要做分布式限流操作。由于目前做分布式限流的方法非常多,我就不再一一赘述了。我们今天用到的分布式限流方法,是redis+lua来实现的。
为什么用redis+lua来实现呢?原因有两个:
其一:redis的性能很好,处理能力强,且容灾能力也不错。
其二:一个lua脚本在redis中就是一个原子性操作,可以保证数据的正确性。
由于要做限流,那么肯定有key来记录限流的累加数,此key可以随着时间进行任意变动。而且key需要设置过期参数,防止无效数据过多而导致redis性能问题。
来看看lua代码:--限流的key
local key = 'limitkey'..KEYS[1]
--累加请求数
local val = tonumber(redis.call('get', key) or 0)
--限流阈值
local threshold = tonumber(ARGV[1])
if val>threshold then
--请求被限
return 0
else
--递增请求数
redis.call('INCRBY', key, "1")
--5秒后过期
redis.call('expire', key, 5)
--请求通过
return 1
end
之后就是直接调用使用,然后根据返回内容为0还是1来判定业务逻辑能不能走下去就行了。这样可以通过此代码段来控制整个集群的流量,从而避免出现雪崩效应。当然此方案的解决方式也可以利用zk来进行,由于zk的强一致性保证,不失为另一种好的解决方案,但是由于zk的性能没有redis好,所以如果在意性能的话,还是用redis吧。
优点:集群整体流量控制,防止雪崩效应
缺点:需要引入额外的redis组件,且要求redis支持lua脚本。
总结
通过以上6种限流方式的讲解,主要是想起到抛砖引玉的作用,期待大家更好更优的解决方法。
以上代码都是伪代码,使用的时候请进行线上验证,否则带来了副作用的话,就得不偿失了