一、可移植性
1.1 数据类型可移植性
由于内核可能运行在不同的架构上,不同的架构具有不同的机器字长,因而可移植性对内核编程非常重要。内核数据使用的数据类型分为 3 个主要类型- 标准C类型
- 明确大小的类型
- 用作特定内核对象的类型
1.1.1 标准 C 类型
使用标准C类型时,必须知道它们的长度在不同架构上可能是会变的,标准C对每种类型的长度没有一个很严格的规定,对于很多类型,它们的长度都可能是会变化的。1.1.2明确大小的类型
有时内核代码需要一个特定大小的数据,内核提供了下列数据类型来使用:u8; /* unsigned byte (8 bits) */
u16; /* unsigned word (16 bits) */
u32; /* unsigned 32-bit value */
u64; /* unsigned 64-bit value */
如果需要带符号的固定长度的类型,可以用
s8; /* unsigned byte (8 bits) */
s16; /* unsigned word (16 bits) */
s32; /* unsigned 32-bit value */
s64; /* unsigned 64-bit value */
或者也可以使用以下数据类型:
u_int8_t;
u_int16_t;
u_int32_t;
u_int64_t
或
int8_t;
int16_t;
int32_t;
int64_t
1.1.3 接口特定的类型
内核中一些场景中使用的数据类型是特别定义的类型,使用这种类型可以具有很好的可移植性。比如进程标识符的类型时pid_t,其它的一些包括:uid_t,timer_t等等,具体的可见include/linux/types.h文件。2.2 时间可移植性
对于时间可移植性来说,linux保证HZ个时钟滴答需要时间为1秒。2.3 页大小
对于内存页,内核保证每个内存页大小为PAGE_SIZE。2.4 对齐
当需要存取不对齐数据时(比如读写非4字节对齐的4字节值),需要考虑该问题,因为不是所有架构都支持非对齐地址上的访问。在文件asm/unaligned.h中定义了两个宏:get_unaligned(ptr);
put_unaligned(val, ptr);
用于支持这种访问。
2.5字节序
由于内核可能运行在不同的架构上,不同架构的字节序是不同的,编写程序时应该尽量不要依赖于字节序,当确实需要特定的字节序时,有两个方法:- 根据内核提供的大小端宏来编写相应代码,如果是大端模式,则内核会定义宏__BIG_ENDIAN,如果是小端模式,内核会定义宏__LITTLE_ENDIAN
- 使用内核提供的转换函数在不同的类型之间进行转换,可以通过asm/byteorder.h文件找到最终被包含的文件并找到这些定义
二、内核数据结构
2.1 链表
链表是最常见的基本数据结构,内核提供了一套操作链表的API,这些API包含了链表的所有操作。这套API定义在linux/list.h中。其中包括两个版本:- 常规的双向循环链表
- 用于散列表的双向链表
struct list_head {
struct list_head *next, *prev;
};
该结构既用于常规链表的头,也用于常规链表的节点。当一个数据结构包含该结构或者指向该结构的指针时,它就可以使用常规链表的API来操作,因为API只需要该结构的地址作为参数。
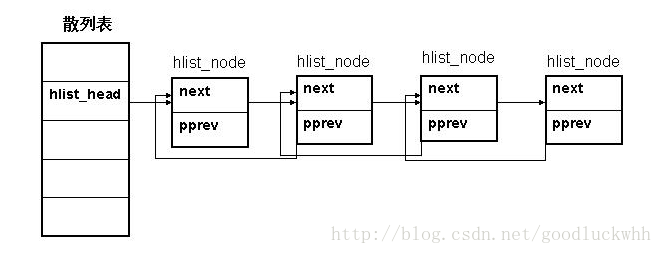
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};
它是用于散列表版本的链表的节点数据结构,使用该版本的链表的数据结构需要包含该结构或者指向该结构的指针,在使用链表API时,将该结构的指针作为参数传递给API即可。
二者的区别:
- 当使用常规版本时,需要使用链表的数据结构只需要包括一个struct list_head结构或其指针,即可使用API进行操作,链表头包含两个指针,一个指向链表尾部,一个指向链表头部。
- 而使用用于散列表版本时,链表头使用数据结构struct hlist_head,它只包含一个链表指向链表第一个元素的指针,使用链表的数据结构需要包含的是struct hlist_node数据结构或其指针,然后即可使用API进行操作。之所以有这个区别是因为当使用散列表时,可以期望链表的长度较短,使用两个头会浪费宝贵的内存。
- 用于散列表的版本不是循环链表
详细的API接口可以参考该文件。
2.2 kref
kref是一个引用计数器,它被嵌套进其它的结构中,记录所嵌套结构的引用计数。其定义如下:struct kref {
atomic_t refcount;
};
它用于跟踪它所嵌入的结构的使用情况。一般情况下,当其为0时,就要执行清理动作了。
相关API也比较简单,可以参考文件include/linux/kref.h,不过需要说明的是当调用kref_put时,如果引用计数变为了0,则kref_put会执行调用者提供的release函数,调用者可以在该函数中左自己想要的清理工作。
初始化之后,kref的使用应该遵循以下三条规则:
- 如果你创建了一个该结构,除非它不给被人使用,否则必须对它调用kref_get增加引用计数。
- 当不在使用该结构时,必须对它调用kref_put
- 如果代码试图在还没拥有引用计数的情况下就调用kref_get,就必须串行化kref_put和kref_get的执行。因为很可能在kref_get执行之前或者执行中,kref_put就被调用并把整个结构释放掉了。内核的文档中给出了一个例子:
static DEFINE_MUTEX(mutex);
static LIST_HEAD(q);
struct my_data
{
struct kref refcount;
struct list_head link;
};
static struct my_data *get_entry()
{
struct my_data *entry = NULL;
mutex_lock(&mutex);
if (!list_empty(&q)) {
entry = container_of(q.next, struct my_data, link);
kref_get(&entry->refcount);
}
mutex_unlock(&mutex);
return entry;
}
static void release_entry(struct kref *ref)
{
struct my_data *entry = container_of(ref, struct my_data, refcount);
list_del(&entry->link);
kfree(entry);
}
static void put_entry(struct my_data *entry)
{
mutex_lock(&mutex);
kref_put(&entry->refcount, release_entry);
mutex_unlock(&mutex);
}
由于在kref_put时可能会调用提供的release函数,因此API也提供了两个其它版本的put接口:
- kref_put_spinlock_irqsave:该版本需要多提东一个spinlock作为参数,它保证减小ref计数和调release函数的操作在锁住该自旋锁并关闭中断的情况下进行,也就是说在SMP架构下也是中断安全的。
- kref_put_mutex:该版本需要多提东一个mutex作为参数,它保证减小ref计数和掉release函数的操作在该mutex的保护下进行,因而是“线程”安全的。
2.3 klist
struct klist_node;
struct klist {
spinlock_t k_lock;
struct list_head k_list;
void (*get)(struct klist_node *);
void (*put)(struct klist_node *);
} __attribute__ ((aligned (sizeof(void *))));
#define KLIST_INIT(_name, _get, _put) \
{ .k_lock = __SPIN_LOCK_UNLOCKED(_name.k_lock), \
.k_list = LIST_HEAD_INIT(_name.k_list), \
.get = _get, \
.put = _put, }
#define DEFINE_KLIST(_name, _get, _put) \
struct klist _name = KLIST_INIT(_name, _get, _put)
extern void klist_init(struct klist *k, void (*get)(struct klist_node *),
void (*put)(struct klist_node *));
struct klist_node {
void *n_klist; /* never access directly */
struct list_head n_node;
struct kref n_ref;
};- 链表头k_list,它就是klist的链表头
- 自旋锁k_lock,用于保护链表
- get,引用链表中的节点时将被调用
- put,当不在引用链表中的节点时将被调用,它和get一起维护了klist_node中的引用计数。
- n_klist:指向节点所在的klist头,由于klist是4字节对齐的,因而该指针的最低两个比特必为0,其中第0比特有特殊用途。
- n_node:链表元素
- n_ref:kref引用计数,跟踪记录了该节点被引用的次数,引用次数由链表头的get和put维护。
- klist中删除节点时,可能节点的引用计数还不为0,因此节点并不会被删除,但是有的场景下,使用者可能期望节点确实被删除后再继续进行操作,为此klist提供了两个API接口来进行删除的:
- klist_remove,该API不仅会递减引用计数并提交删除请求,并且会等待节点确实被删除
- klist_del,该API仅仅递减引用计数,并提交删除请求,但是不会等待,不过如果它触发了真正的删除动作,则会唤醒等待删除真正完成的任务
另外当提交删除请求时,klist会将节点中n_klist的0比特设置为1,表示该节点已经被请求删除了,只是暂时还没真正删除。标记了该比特的节点在遍历时将会被忽略
- 由于需要考虑被忽略的节点,即已经被请求删除的节点,因而klist的遍历稍微复杂些。它用函数实现,并用struct klist_iter记录中间状态。klist机制也提供了两个API用于遍历:
- klist_iter_init_node用于从klist中的某个节点开始遍历,使用它初始化遍历时,可以直接访问当前节点或者用klist_next访问下一节点
- klist_iter_init用于从链表头开始遍历的,使用它初始化遍历时,只能用klist_next访问下一节点
2.4 红黑树
三、内核调试
由于内核的特殊性,内核代码很难在调试器控制下运行,也很难跟踪,并且由于内核代码用于服务整个系统,无法简单的将某个故障与特定的“任务”关联起来,因而内核程序的调试是比较特殊的。
3.1内核对调试的支持
为了方便调试,内核提供了很多选项,这些选项为内核调试提供了比较丰富的调试支持,它们覆盖了内存管理、分配,内核同步、互斥,驱动子系统等等内核的基本子系统,因而对于内核开发者来说是很有用的。以下是一些其中一些选项(大多选项都位于kernel hacking菜单中)。- CONFIG_DEBUG_KERNEL:这个用于使能内核调试选项,它本身不激活任何调试特性。CONFIG_DEBUG_SLAB:使能内存分配的调试功能,打开该选项,则slab子系统会在申请和释放内存时进行一些检查。
- CONFIG_DEBUG_PAGEALLOC:使能页面的分配调试。
- CONFIG_DEBUG_SPINLOCK:使能自旋锁的调试支持,可用于检测是否存在重复解锁同
- CONFIG_MAGIC_SYSRQ:使能"魔术 SysRq"键
- CONFIG_DEBUG_STACKOVERFLOW:使能栈溢出的检查。
- CONFIG_DEBUG_STACK_USAGE:使能栈使用信息的调试支持。内核会监测堆栈使用并作一些统计, 这些统计可以用魔术 SysRq 键得到
- CONFIG_KALLSYMS和CONFIG_KALLSYMS_ALL:它们位于"Generl setup"菜单中,用于将内核符号表包含在系统中。如果没有内核符号表,则oops信息无法给出回溯的符号信息,只能给出16进制的地址信息。
- CONFIG_IKCONFIG和CONFIG_IKCONFIG_PROC:它们位于"Generl setup"菜单中,使能它后才能在/proc/config.gz中来访问内核配置信息。
- CONFIG_DEBUG_DRIVER:该选项在”Device Drivers->Generic Driver Options”菜单中,用于使能驱动框架的调试信息。
- CONFIG_INPUT_EVBUG:该选项在"Device drivers-> Input device support "菜单中,它用于大卖输入事件的详细日志,需要注意的是它会记录了输入设备的所有输入,包括密码。
- CONFIG_PROFILING:该选项位于"Profiling support"菜单中。用于打开系统系能调试跟踪的功能,它对于剖析系统系能非常有用,也可用于系统挂起的调试。
3.2 用log调试
用打开来进行调试或者说用log来调试是最基本的调试手段,无论是内核还是用户程序,因为有些bug是在特定场合和应用场景下才出现的,换了环境后很难复现,而有的bug需要长时间运行才能复现,这时候一个精心设计的log系统就能起到大的用途,通过精心选择log点和所要记录的信息,我们可以收集bug现场的所有我们想要的信息,还可以跟踪bug产生的过程,因而log是一个非常重要的调试手段。内核中打印需要用printk来实现。
3.2.1 printk
printk类似于用户空间的printf,但是也有不同,printk允许调用者指定消息的log等级,系统定义的log等级定义在include/linux/kern_levels.h中,包括:- KERN_EMERG:用于紧急消息, 常常是那些崩溃前的消息.
- KERN_ALERT:需要立刻动作的情形.
- KERN_CRIT:严重情况, 常常与严重的硬件或者软件失效有关.
- KERN_ERR:用来报告错误情况; 设备驱动常常使用 KERN_ERR 来报告硬件故障.
- KERN_WARNING:有问题的情况的警告, 这些情况自己不会引起系统的严重问题.
- KERN_NOTICE:正常情况, 但是仍然值得注意. 在这个级别一些安全相关的情况会报告.
- KERN_INFO:信息型消息. 在这个级别, 很多驱动在启动时打印它们发现的硬件的信息.
- KERN_DEBUG:用作调试消息
如果调用printk时没有指定消息的log等级,则将使用默认的log等级。
系统也有一个log等级,如果printk的log等级大于等于当前系统的log等级,则消息会被打印到当前控制台。用户空间对于系统log的处理涉及到两个daemon:klogd和syslogd。
- klogd会通过syslog()系统调用或者读取proc文件系统来获取内核的log信息,如果 klogd 没有运行,则用户空间只能通过读 /proc/kmsg 来获取信息或者使用dmesg来获取信息。
- syslogd这个守护进程根据/etc/syslog.conf,将不同的服务产生的log记录到不同的文件中,它是通过klogd来读取系统内核log信息的,如果 klogd 和 syslogd 都在运行,则无论内核log等级为多少,内核都会将消息添加到/var/log/messages(如果syslog的配置文件有某个log的等级的设置,就按照syslogd的配置进行处理)。
即:如果 klogd 进程在运行, 它获取内核消息并分发给 syslogd, syslogd 接着检查/etc/syslog.conf 来找出如何处理它们. syslogd 根据log类型和一个优先级来区分消息; log类型和优先级的允许值在 <sys/syslog.h> 中定义, 内核消息由 LOG_KERN 来表示.如果 klogd 没有运行, 数据保留在printk的环形缓存中直到有人读它或者缓存被覆盖.
全局变量console_loglevel记录了系统当前的log等级,可以通过/proc/sys/kernel/printk文件读写它,这个文件有 4 个整型值,分别为:
当前log级别,适用没有明确log级别的消息的缺省级别,允许的最小log级别,启动时缺省log级别。
写单个值到这个文件将修改当前log级别为这个值。另外使用dmesg –n {数值}也可以用于修改系统的当前log等级为{数值}
系统的log被记录在一个环形缓存中,缓存的长度可以使用dmesg –s {大小}来修改,printk将信息写入该环形缓存,如果环形缓存填满,printk 绕回并在缓存的开头增加新数据,覆盖掉最老的数据。
3.2.2 速率限制
采用log机制时,有时候需要限制打印的速率,否则打印信息可能将系统拖垮,内核提供了一个函数用于进行打印速率限制printk_ratelimit,如果要使用它来限制打印速率,则应该首先调用它,如果它返回非零值则可以继续打印,否则不打印。3.3 通过查询来调试
Linux系统提供了一些机制用于向用户空间提供查询内核信息的接口。这些信息也可以帮我们分析定位问题。用log机制不失为一种很好的调试方式,但是大量的log会影响系统性能。而Linux内核提供的查询机制可以让我们在需要某些信息时再来获取信息,而不是随时打印,这有助于降低系统的负载。*nix系统提供许多工具来获取系统消息:ps, netstat, vmstat, 等等。
内核提供的两个重要的查询内核信息的机制是:/proc文件系统,/sysfs文件系统以及ioctl,这几种方式都可以用于向用户空间提供内核信息。它们提供了一套机制给内核部件使用,内核部件只要使用这些API就能很方便的向用户空间开发接口。不同的是:
- 使用两个文件系统时,接口会出现在这两个文件系统相应的位置,即接口以文件的形式存在,可以直接使用cat/echo等命令来操作,而使用ioctl时则开发的接口是编程接口,需要写程序来使用。
- ioctl比使用文件系统要快。
- 通过ioctl实现的调试机制,如果不公开其它人无法知道无法使用。
3.4 使用strace来调试
使用strace命令可以跟踪所有的用户空间程序发出的系统调用。它不仅显示调用, 还以符号形式显示调用的参数和返回值。当一个系统调用失败,错误的符号值和对应的字符串都会被输出出来。该命令有助于我们分析是哪个调用导致程序无法运行了。3.5调试系统故障
内核程序出现异常(比如oops时)时,一般都会打印一些log信息出来,这些信息对于分析定位问题是很有帮助的,下边的信心是从kernel的git tree里取的一个oops信息:On CONFIG_X86_32 this results in the following oops:
BUG: unable to handle kernel paging request at f7f22280
IP: [<c10257b9>] reserve_ram_pages_type+0x89/0x210
*pdpt = 0000000001978001 *pde = 0000000001ffb067 *pte = 0000000000000000
Oops: 0000 [#1] PREEMPT SMP
Modules linked in:
Pid: 0, comm: swapper Not tainted 3.0.0-acpi-efi-0805 #3
EIP: 0060:[<c10257b9>] EFLAGS: 00010202 CPU: 0
EIP is at reserve_ram_pages_type+0x89/0x210
EAX: 0070e280 EBX: 38714000 ECX: f7814000 EDX: 00000000
ESI: 00000000 EDI: 38715000 EBP: c189fef0 ESP: c189fea8
DS: 007b ES: 007b FS: 00d8 GS: 0000 SS: 0068
Process swapper (pid: 0, ti=c189e000 task=c18bbe60 task.ti=c189e000)
Stack:
80000200 ff108000 00000000 c189ff00 00038714 00000000 00000000 c189fed0
c104f8ca 00038714 00000000 00038715 00000000 00000000 00038715 00000000
00000010 38715000 c189ff48 c1025aff 38715000 00000000 00000010 00000000
Call Trace:
[<c104f8ca>] ? page_is_ram+0x1a/0x40
[<c1025aff>] reserve_memtype+0xdf/0x2f0
[<c1024dc9>] set_memory_uc+0x49/0xa0
[<c19334d0>] efi_enter_virtual_mode+0x1c2/0x3aa
[<c19216d4>] start_kernel+0x291/0x2f2
[<c19211c7>] ? loglevel+0x1b/0x1b
[<c19210bf>] i386_start_kernel+0xbf/0xc8
当在内核代码中使用一个非法指针时,内核通常会给出一个oops消息。Oops消息包含了是什么样的错误,出错时的处理器状态,包括CPU 寄存器内容和一些其它的信息。比较重要的是EIP和Call Trace,通常通过它们就可以找到出问题的位置和原因。
- EIP包含出问题的位置,比如EIP is at reserve_ram_pages_type+0x89/0x210表明问题出在reserve_ram_pages_type中,该函数大小为0x210,问题出在该函数起始地址偏移0x89处。
- Call Trace包含了出问题时的内核栈,如果内核没有包含符号表,则这个打印是以16进制地址打印的。
3.5.1 有编译好的内核镜像
gdb vmlinux(gdb)b *func+offset
或者
(gdb)l *func+offset
3.5.2 有编译好的二进制文件, 用objdump看
objdump -S file.o > /tmp/file.s然后查看该反汇编指令文件
3.5.3 有编译好的内核镜像,用addr2line看
addr2line -e vmlinux func+offset另外, 内核源代码目录的./scripts/decodecode文件是用来解码Oops的:
./scripts/decodecode < Oops.txt
3.6 系统挂起
尽管内核代码的大部分 bug 以 oops 消息结束,但有时候bug也可能导致系统完全挂起,没有任何打印消息。例如如果代码进入一个死循环,内核就会停止调度。调试这种问题的一种方式是在自己的代码中加入log,定期打印一些信息到控制台,如果一段时间log没有被更新,就可以根据这个信息找到哪里导致挂起了。
另外一个可用的工具是SysRq魔法键。通过该机制我们能够获取很多当前系统的信息。魔法键的功能可以在编译内核时通过配置文件打开,也可以在系统启动后通过修改文件/proc/sys/kernel/sysrq来打开或者关闭该功能,sysrq的取值及其含义:
- 0:关闭该功能
- 1:打开所有的功能表示打开
- 大于1:所允许的功能的掩码(具体每个比特位表示什么含义,最好查看Documents/sysrq.txt文件
- b:立刻重启系统,并且不会对磁盘进行同步也不会卸载磁盘
- d:显示所有被持有的锁
- e:向除init进程之外的所有进程发送SIGTERM信号
- i:向除init进程之外的所有进程发送SIGKILL信号
- l:为所有在活动状态的CPU打印其堆栈信息
- m:打印当前内存信息
- p:打印当前的寄存器状态以及标记
- q:为所有CPU打印armed的高精度定时器以及所有的时钟设备的详细信息。
- t:打印当前任务以及它们的堆栈信息
- w:打印处于不可中断阻塞状态的任务的信息