当需要分布式缓存的时候,通过key的hash值分散数据存储hash(n)%缓存服务器台数,同时也可以快速查找数据而不用遍历所有的服务器。如下图:

但是这样,当业务拓展想要增加一台服务器的话,要么缓存服务器数据全部需要重新计算存储 -----hash(n)%5 。 要么需要遍历所有缓存服务器。不够灵活。
所以就出现了一致性hash算法,来解决这样的问题。
Hash环,如下图所示:

一致性Hash算法是key的hash值,对2^32取模,对服务器确定确定此数据在环上的位置(比如A,B,C,D)。
数据进来后对2^32 取模,得到一个值K1,在Hash环中顺时针找到服务器节点。
假如B服务器节点失效:
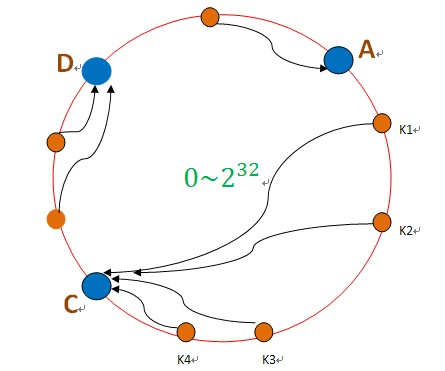
如果是B失效了,将B的数据迁移至C即可,对于原本散列在A和D的数据,不需要做任何改变。
扫描二维码关注公众号,回复:
3926992 查看本文章

总结:一致性hash算法(DHT)通过减少影响范围的方式解决了增减服务器导致的数据散列问题,从而解决了分布式环境下负载均衡问题。