项目源码:https://github.com/jackroos/word_frequency
项目简介
本次结对编程的项目是写一个程序来统计文本文件中英语单词的频率,详见博客:https://www.cnblogs.com/xinz/archive/2011/11/27/2265000.html
需求
- 输出单个文件中的前N个最常出现的英语单词;
- 支持stop words, 即可以在统计词汇时跳过一些常用词,如 "a", "it", "the", "and", "this";
- 输出单个文件中前N个最常出现的短语;
- 把动词形态统一之后再计数;
- (可选)统计动词-介词短语。
命令行参数
wf [-f|-c|-p <len>|-q <preposition-list>] [-n <num>] [-x <stop-words>] [-v <verb-dict>] [-d [-s]] <path>
Options:
-f: Count word occurrences.
-c: Count character occurrences.
-p <len>: Count phrase occurrences, treating any <len> contiguous words as a phrase.
-q <preposition-list>: Count VERB-PREPOSITION pair occurrences. <prepostition-list> is the path to
the list of prepositions. -v must be specified. THIS IS AN OPTIONAL FEATURE.
-v <verb-dict>: Use <verb-dict> as a verb dictionary that can be used with -p or -q.
-d: Treat <path> as the path to a directory and operate on each file inside the directory.
-s: Recurse into sub-directories. Must be used with -d.
-n <num>: Output only the top <num> items.
-x <stop-words>: Use <stop-words> as a list of stop words, which are ignored in the
counting. Effective only with -f or -p specified.
<path>: The path to the input file if -d is not specified.结对编程
合作方式
我们在这次结对编程里采用的是分工的合作方式,我主要负责代码的构建,我队友主要负责效能分析与代码测试。
代码设计与规范
编程语言:Python
模块设计:
- 包括main主程序,读入并预处理文件的工具函数,后端统计频率得到“频率字典”(即以统计的物体作为key,其频率作为value),并对频率字典进行排序,得到频率最高的前n个统计物体的频率字典。
- 模块之间的关系见下图:
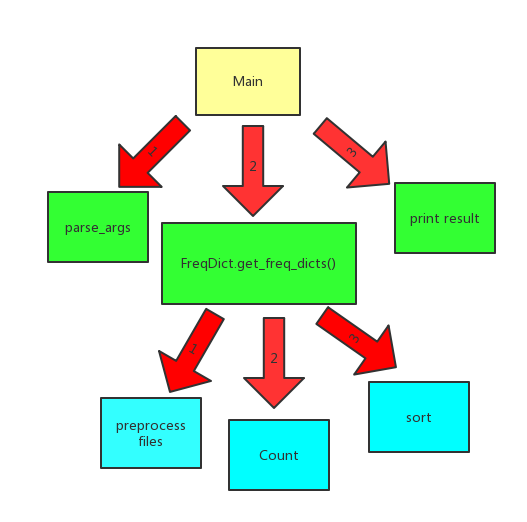
代码规范:
- 采用面向对象的封装、继承、多态的思想,统计字母、单词、短语的不同的类继承同一个父类,然后在每个子类具体实现虚函数;
- 每个单独功能尽量单独出来,例如每个类可以把实现细节单独成一些函数,相当于C++的私有成员函数。
如何投入到项目中,得到最优的结果
在这次结对编程的项目中,我们通过前期的讨论,很快地确定了编程语言以及模块的设计,从而后面可以很高效地实现各个独立的模块,并进行改进;然后由于我们选择的是用python语言,而python解释器自带GIL锁,从而无法通过多线程提升我们代码的运行效率,所以我们决定利用多进程对多文件处理的情况进行优化。
队友的优缺点
复审代码认真仔细,善于利用各种效能分析工具,善于提出问题;有时候有点拖延症。
效能分析与代码优化
初步实现思路:
多进程读入文件,通过正则表达式匹配得到字母/单词/句子的列表
利用python的Counter对相应的物体进行计数,然后利用Counter的most_common和python的sorted进行排序
对于处理多个文件时,利用python的multiprocessing库多进程处理。
效能分析结果:
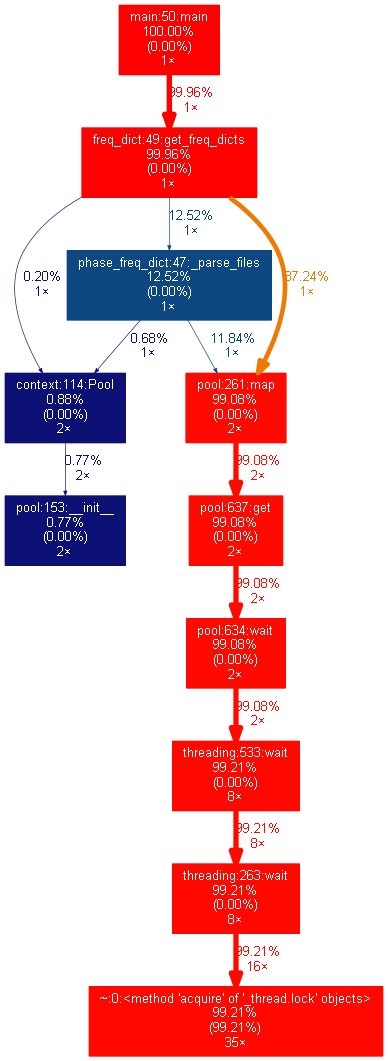
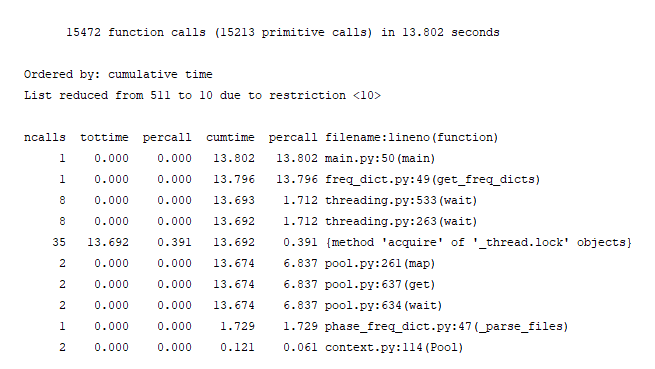

我们发现处理多个文件的并行效率并不高,原因是多个进程无法共享内存,所以每个进程需要向系统获得锁,然后读取相应的object list,而object list是字母/单词/句子的列表,开销非常大,从而会使并行效率十分低。
改进:
改进思路:将处理文件也放到各自进程中处理,这样各个进程就只需要把各自文件路径拷贝到自己的内存,大大降低了内存的时间开销。
效能分析:
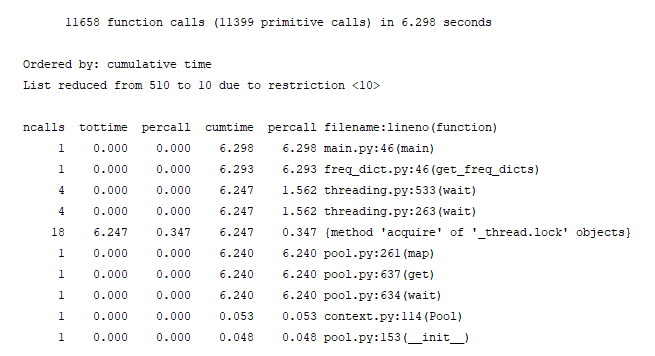
运行时间比之前快了一倍,主要是因为每个进程只需要获得各自的文件路径,从而使并行效率大大提高。
测试
- 我们用unittest来进行测试主要有以下几个部分
- testChar_freq :测试基本的字符频率
- testWord_freq :测试单词频率
- testPhrase_freq :测试短语频率
- testWord_add_stop_freq :有stopword时的单词频率测试
- testPhrase_add_stop_freq :有stopword时的短语频率测试
- testPhrase_add_verb_freq :有原形变化时的短语频率测试
测试结果
测试代码见https://github.com/jackroos/word_frequency/blob/master/test.py